本文最后更新于:9 天前
CS144 2023 简要记录 前言: 因为大学时候学计网的无聊体验,相关的八股不怎么愿意看,面试的时候一直被问计网相关的问题都不怎么能回答上来,虽然现在秋招快结束了,但还是打算趁着国庆假期以及后面几天,把之前就听说过的CS144计网课程实验做完,补齐计网这一环。由于只是为了熟悉计网,故不怎么会详细记录实验过程,只是写一些印象深刻的点,由于这是个人网站,没做什么seo优化,搜索引擎不怎么能搜到,故直接把相关代码贴上去。
如有任何问题,欢迎联系我,个人邮箱:r1523646952@163.com
环境搭建:
安装高版本的ubuntu保证g++版本符合要求
清华ubuntu镜像:ubuntu-23.04-desktop-amd64
实验pdf备份:https://github.com/1020xyr/cs144-pdf
lab0 wget与内存字节流实现 lab0地址:check0.pdf
string_view不涉及实际的内存管理
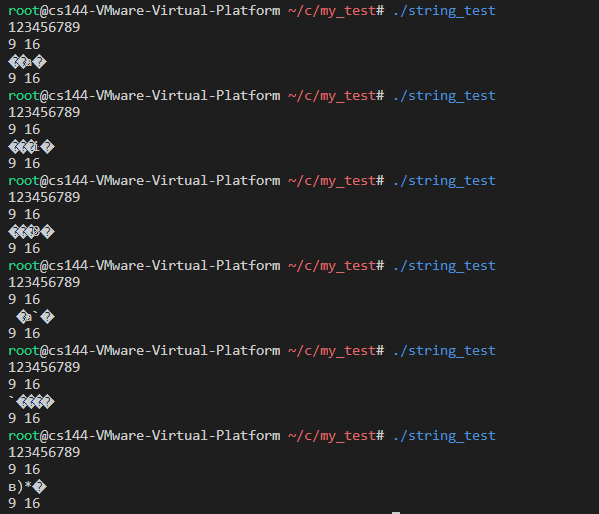
刚开始ByteStream类中使用string_view存储字节流,虽然知道string_view和leveldb中的Slice类差不多,但总感觉它会维持一份它所指的内存(特别是使用了移动构造函数),但实际测试却发现报错,指向栈内内存,故改成string存储
string_view测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <string> #include <iostream> using namespace std;string_view GetView () {"123456789" ;size () << " " << sizeof (view) << endl;return view;int main () auto view = GetView ();size () << " " << sizeof (view) << endl;
Writer::push 数据为空时处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 {"peeks" , 2 };execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "cat" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Peek { "ca" } );execute ( Peek { "ca" } );execute ( BytesBuffered { 2 } );execute ( Peek { "ca" } );execute ( Peek { "ca" } );execute ( Pop { 1 } );execute ( Push { "" } );execute ( Push { "" } );execute ( Push { "" } );execute ( Peek { "a" } );execute ( Peek { "a" } );execute ( BytesBuffered { 1 } );catch ( const exception& e ) {"Exception: " << e.what () << endl;return EXIT_FAILURE;
测试时以上测试段一直过不去,后面发现即使数据为空也会向字节流中加入一个””,可以在peek时进行特殊处理,返回第一个非空的string,但更简单的是直接在push时不加入空数据
1 2 3 if ( data.empty () || avil == 0 ) { return ;
无符号整数while循环 > 0
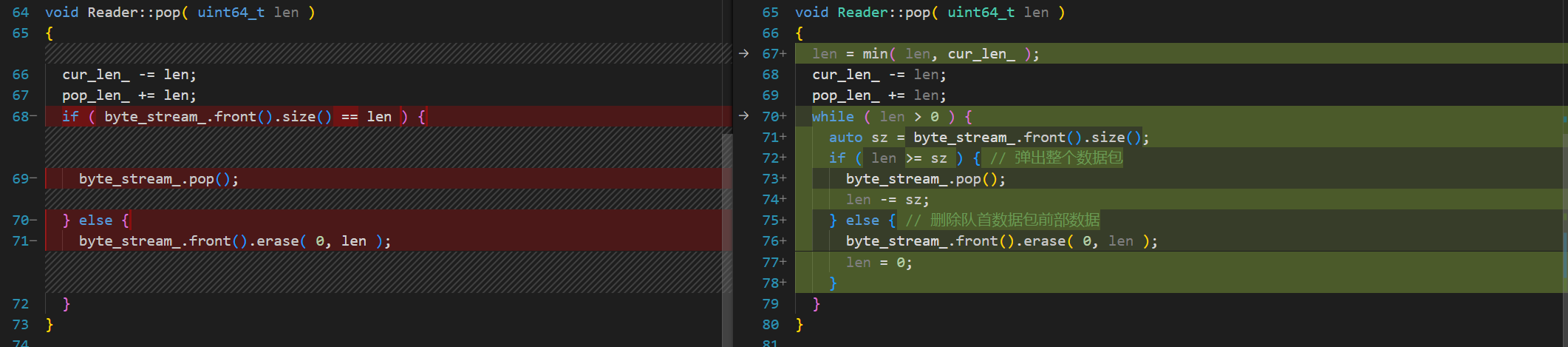
刚开始我的Reader::pop实现如左边所示,这是基于byte_stream_helpers中read函数的基本用法,使用peek后选择性进行裁剪后调用pop,故pop的len一定小于等于第一个string的长度,当然以上代码是可以通过全部测试用例的。写完之后,看了看网上其他实现,发现CS144 2023 完全指南 比我考虑多一点,故对其他情况进行处理。
实现过程中忽略了len为无符号整数的特点,想通过使len小于0结束循环,然后导致循环出错,发现了这一点。也就是说使用无符号整数当作while循环条件是很危险的,只有==0的时候才能跳出循环,len>0实际上等同于len!=0,并且len变成“负数”时值更加无法预测,导致程序行为非常诡异,尽量少使用无符号整数当作循环条件
通过截图:
参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void get_URL ( const string& host, const string& path ) Address addr ( host, "http" ) ; connect ( addr ); "GET " + path + " HTTP/1.1\r\nHost: cs144.keithw.org\r\nConnection: close\r\n\r\n" ;write ( str ); while ( !tcp_socket.eof () ) { read ( content );close ();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class ByteStream protected :uint64_t capacity_;uint64_t cur_len_ { 0 };uint64_t push_len_ { 0 };uint64_t pop_len_ { 0 };bool close_flag_ { false };bool error_flag_ { false };public :explicit ByteStream ( uint64_t capacity ) Reader& reader () ;const Reader& reader () const Writer& writer () ;const Writer& writer () const
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 #include <stdexcept> #include "byte_stream.hh" using namespace std;ByteStream ( uint64_t capacity ) : capacity_ ( capacity ) {}void Writer::push ( string data ) const uint64_t avil = available_capacity ();if ( data.empty () || avil == 0 ) { return ;if ( data.size () > avil ) { erase ( avil );size ();size ();emplace ( move ( data ) ); void Writer::close () true ;void Writer::set_error () true ;bool Writer::is_closed () const return close_flag_;uint64_t Writer::available_capacity () const return capacity_ - cur_len_;uint64_t Writer::bytes_pushed () const return push_len_;string_view Reader::peek () const return byte_stream_.front (); bool Reader::is_finished () const return close_flag_ && ( cur_len_ == 0 );bool Reader::has_error () const return error_flag_;void Reader::pop ( uint64_t len ) min ( len, cur_len_ );while ( len > 0 ) {auto sz = byte_stream_.front ().size ();if ( len >= sz ) { pop ();else { front ().erase ( 0 , len );0 ;uint64_t Reader::bytes_buffered () const return cur_len_;uint64_t Reader::bytes_popped () const return pop_len_;
lab1 重组器 重组器的数据结构选择为list,每一个链表节点保存子串的起始索引,终止索引,string数据,链表节点顺序与区间范围顺序一致。insert操作主要分成两种情况:(1)到达数据在小于等于预期索引,则将该数据写入字节流,并写入后面连续的子串数据 (2)到达数据在大于预期索引,则考虑是否需要暂存数据,而后检查list中子串位置关系,确保各子串存储数据范围不重叠
ps: 实现过程中我想要使得情况2的处理更加简洁,但一直想不到非常好的方法,最后直接遍历链表,不同位置关系分类讨论,懒得想更好的方法了,而且先写出来一个能过测试的demo也是便于进一步优化的,一昧空想意义不大。
问题
终止条件:
出现末尾子串标记且末尾子串前所有数据均写入字节流
1 2 3 if ( unassembler_string_.empty () && occur_last_string_ ) {close ();
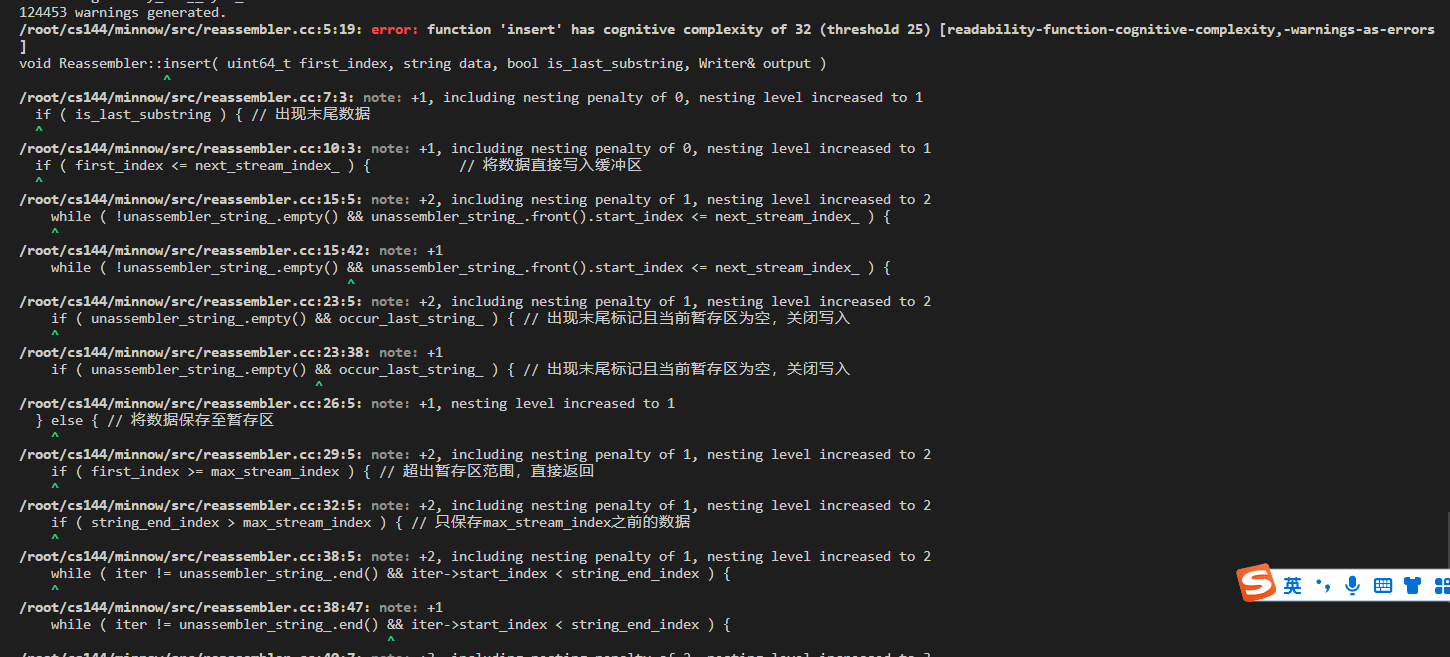
语法风格检查:
minnow/src/reassembler.cc:5:19: error: function ‘insert’ has cognitive complexity of 32 (threshold 25) [readability-function-cognitive-complexity,-warnings-as-errors]
将insert函数拆分为insert_bytestream函数与insert_tmp_buffer函数
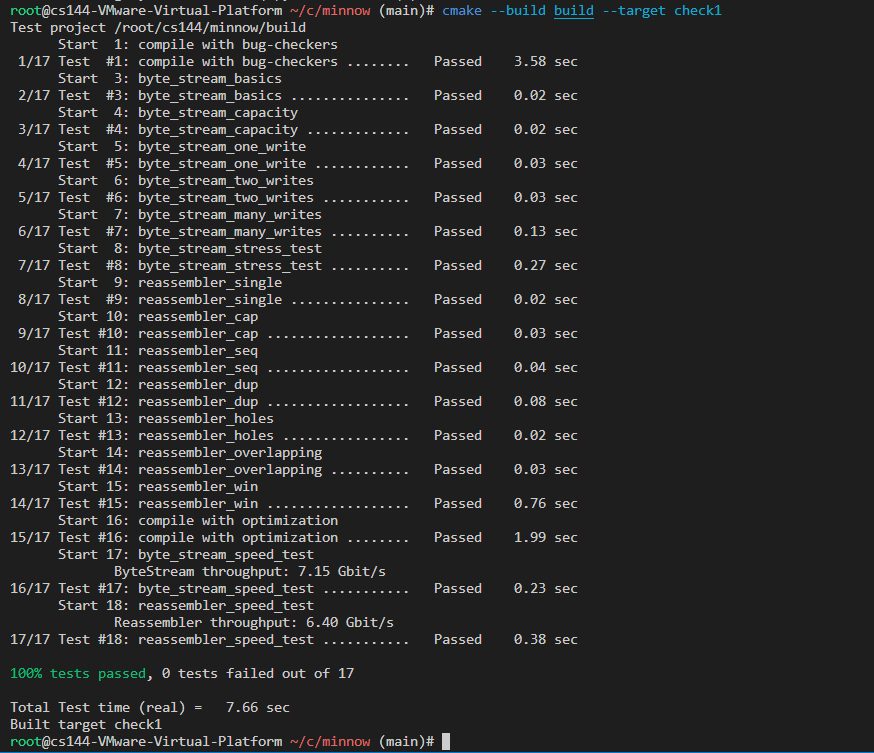
测试通过截图
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #pragma once #include "byte_stream.hh" #include <list> #include <string> struct Substring uint64_t start_index {};uint64_t end_index {};Substring ( uint64_t start, uint64_t end, std::string&& s )start_index ( start ), end_index ( end ), data ( std::move ( s ) )Substring ( Substring&& substr ) noexcept start_index ( substr.start_index ), end_index ( substr.end_index ), data ( std::move ( substr.data ) )operator =( Substring&& substr ) noexcept move ( substr.data );return *this ;Substring () noexcept = default ;Substring () noexcept = default ;Substring ( const Substring& ) noexcept = default ;operator =( const Substring& ) noexcept = default ;class Reassembler public :void insert ( uint64_t first_index, std::string data, bool is_last_substring, Writer& output ) uint64_t bytes_pending () const private :void insert_bytestream ( uint64_t first_index, std::string& data, Writer& output ) void insert_tmp_buffer ( uint64_t first_index, std::string& data, Writer& output ) uint64_t next_stream_index_ { 0 }; uint64_t bytes_pending_num_ { 0 }; bool occur_last_string_ { false };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 #include "reassembler.hh" using namespace std;void Reassembler::insert ( uint64_t first_index, string data, bool is_last_substring, Writer& output ) if ( is_last_substring ) { true ;if ( first_index <= next_stream_index_ ) { insert_bytestream ( first_index, data, output );else { insert_tmp_buffer ( first_index, data, output );void Reassembler::insert_bytestream ( uint64_t first_index, std::string& data, Writer& output ) erase ( 0 , next_stream_index_ - first_index ); push ( move ( data ) );bytes_pushed (); while ( !unassembler_string_.empty () && unassembler_string_.front ().start_index <= next_stream_index_ ) {auto & first_substring = unassembler_string_.front ();erase ( 0 , next_stream_index_ - first_substring.start_index ); push ( move ( first_substring.data ) );bytes_pushed (); pop_front (); if ( unassembler_string_.empty () && occur_last_string_ ) { close ();void Reassembler::insert_tmp_buffer ( uint64_t first_index, std::string& data, Writer& output ) const uint64_t max_stream_index = next_stream_index_ + output.available_capacity ();uint64_t string_end_index = first_index + data.length ();if ( first_index >= max_stream_index ) { return ;if ( string_end_index > max_stream_index ) { erase ( max_stream_index - first_index );auto iter = unassembler_string_.begin ();while ( iter != unassembler_string_.end () && iter->start_index < string_end_index ) {if ( iter->start_index <= first_indexreturn ;if ( iter->start_index >= first_indexerase ( iter );else { if ( iter->start_index <= first_indexerase ( 0 , iter->end_index - first_index );else if ( iter->start_index < string_end_indexerase ( iter->start_index - first_index );emplace ( iter, first_index, string_end_index, move ( data ) );return ;emplace ( iter, first_index, string_end_index, move ( data ) );uint64_t Reassembler::bytes_pending () const return bytes_pending_num_;
lab2 TCP接收端 我的Wrap32::unwrap实现比较复杂,但思想比较简单,设checkpoint / 2^32 = x,遍历x-1 x x+1三个点,选择与checkpoint差绝对值最小的系数k 2^32 * k + seq_no
CS144 2023 Lab Checkpoint 2: the TCP receiver 中的实现更简洁一点,但懒得改了
TCPReceiver中的代码更多是根据测试报错然后修改,主要的点就在于SYN标志位 FIN标志位与序号 流索引的关系,以及窗口最大值限制。
对于确认号中FIN标志是否占据一个序列号,我刚开始是通过TCPReceiver::receive中判断是否出现FIN标志位且重组器为空来判断是否接收全部数据,而后以这个变量计算确认号
1 2 3 4 5 6 7 8 if ( occur_fin_ && reassembler.bytes_pending () == 0 ) { true ;if ( occur_syn_ ) { wrap ( inbound_stream.bytes_pushed () + 1 + recv_all_data_, zero_point_ );
这样的实现比较复杂,在看了CS144 2023 Lab Checkpoint 2: the TCP receiver 实现后,发现inbound_stream.is_closed()方法效果一致,故简化代码,以is_closed代替以上方法
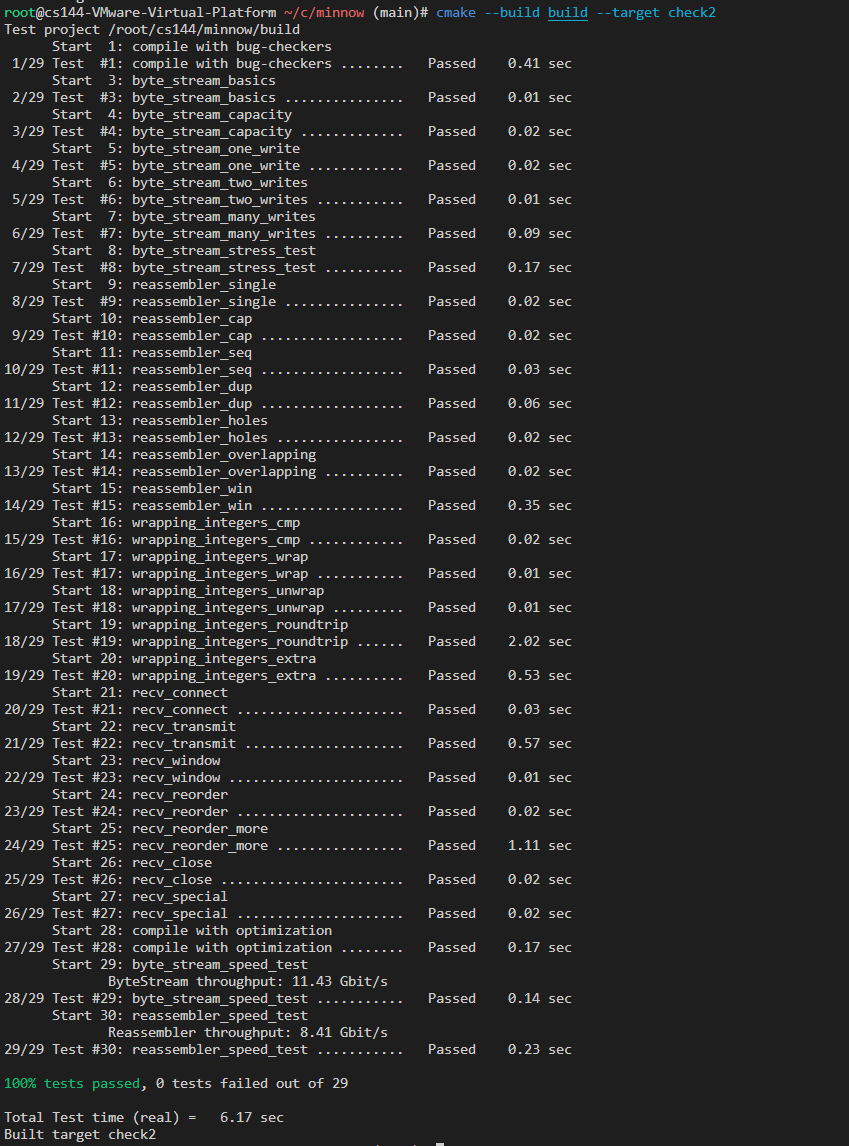
测试通过截图
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #pragma once #include <cstdint> class Wrap32 protected :uint32_t raw_value_ {};public :explicit Wrap32 ( uint32_t raw_value ) : raw_value_( raw_value ) {static Wrap32 wrap ( uint64_t n, Wrap32 zero_point ) uint64_t unwrap ( Wrap32 zero_point, uint64_t checkpoint ) const operator +( uint32_t n ) const { return Wrap32 { raw_value_ + n }; }bool operator ==( const Wrap32& other ) const { return raw_value_ == other.raw_value_; }static uint64_t unsigned_abs ( uint64_t a, uint64_t b ) return ( a > b ) ? a - b : b - a; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include "wrapping_integers.hh" #include <algorithm> using namespace std;Wrap32 Wrap32::wrap ( uint64_t n, Wrap32 zero_point ) return Wrap32 { zero_point + n };uint64_t Wrap32::unwrap ( Wrap32 zero_point, uint64_t checkpoint ) const const uint64_t pow32 = 1ULL << 32 ;const uint32_t seq_no = raw_value_ - zero_point.raw_value_;uint64_t min_abs = pow32 + 1 ;uint64_t k = 0 ;const auto multiple = static_cast <int64_t >( checkpoint / pow32 );const int64_t low_bound = max <int64_t >( 0 , multiple - 1 ); const int64_t high_bound = min <int64_t >( multiple + 1 , pow32 - 1 ); for ( int64_t i = low_bound; i <= high_bound; i++ ) {const uint64_t sub = unsigned_abs ( i * pow32 + seq_no, checkpoint );if ( min_abs > sub ) {return k * pow32 + seq_no;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #pragma once #include "reassembler.hh" #include "tcp_receiver_message.hh" #include "tcp_sender_message.hh" class TCPReceiver public :void receive ( TCPSenderMessage message, Reassembler& reassembler, Writer& inbound_stream ) TCPReceiverMessage send ( const Writer& inbound_stream ) const ;private :bool occur_syn_ { false }; 0 };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include "tcp_receiver.hh" using namespace std;void TCPReceiver::receive ( TCPSenderMessage message, Reassembler& reassembler, Writer& inbound_stream ) if ( message.SYN ) {true ;if ( occur_syn_ ) {insert ( message.seqno.unwrap ( zero_point_, inbound_stream.bytes_pushed () ) + message.SYN - 1 ,TCPReceiverMessage TCPReceiver::send ( const Writer& inbound_stream ) const if ( occur_syn_ ) { wrap ( inbound_stream.bytes_pushed () + 1 + inbound_stream.is_closed (), zero_point_ );min <uint64_t >( UINT16_MAX, inbound_stream.available_capacity () ); return msg;
未完待续(等搞完毕设再写)