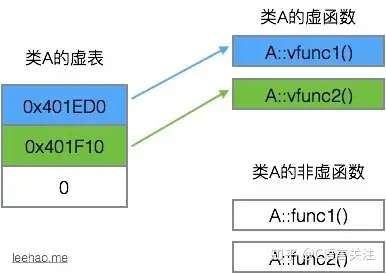
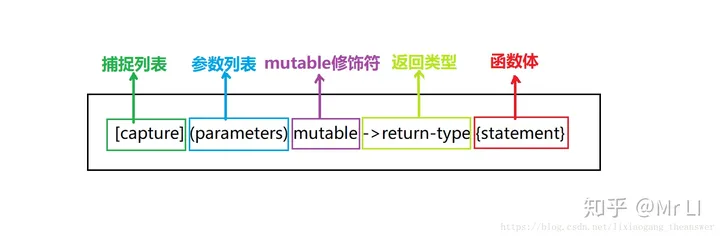
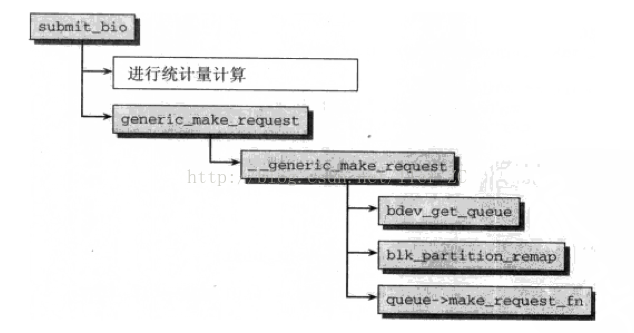
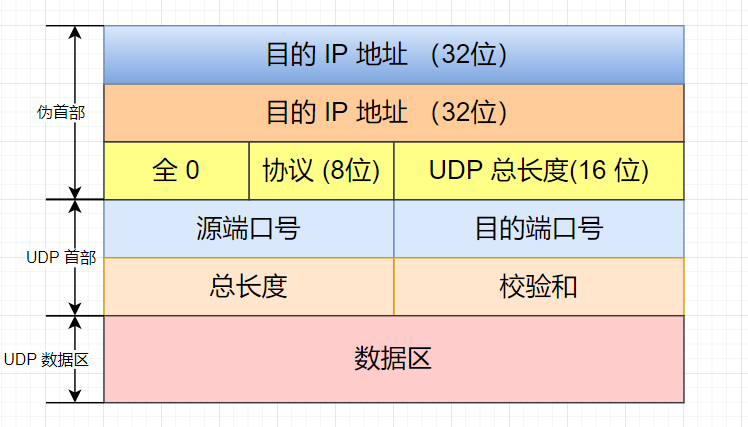
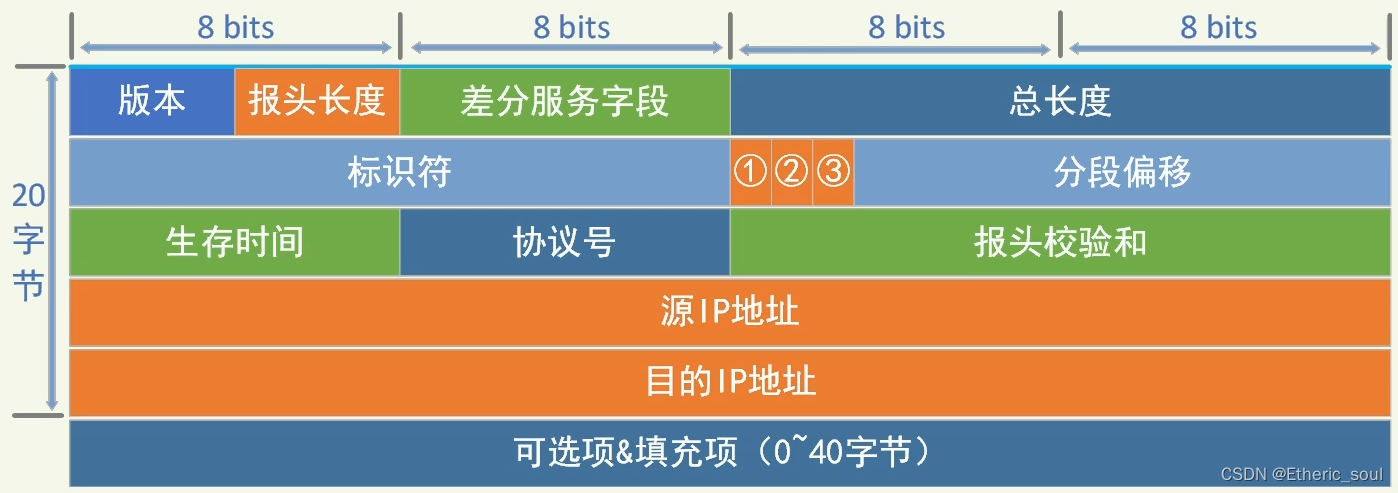
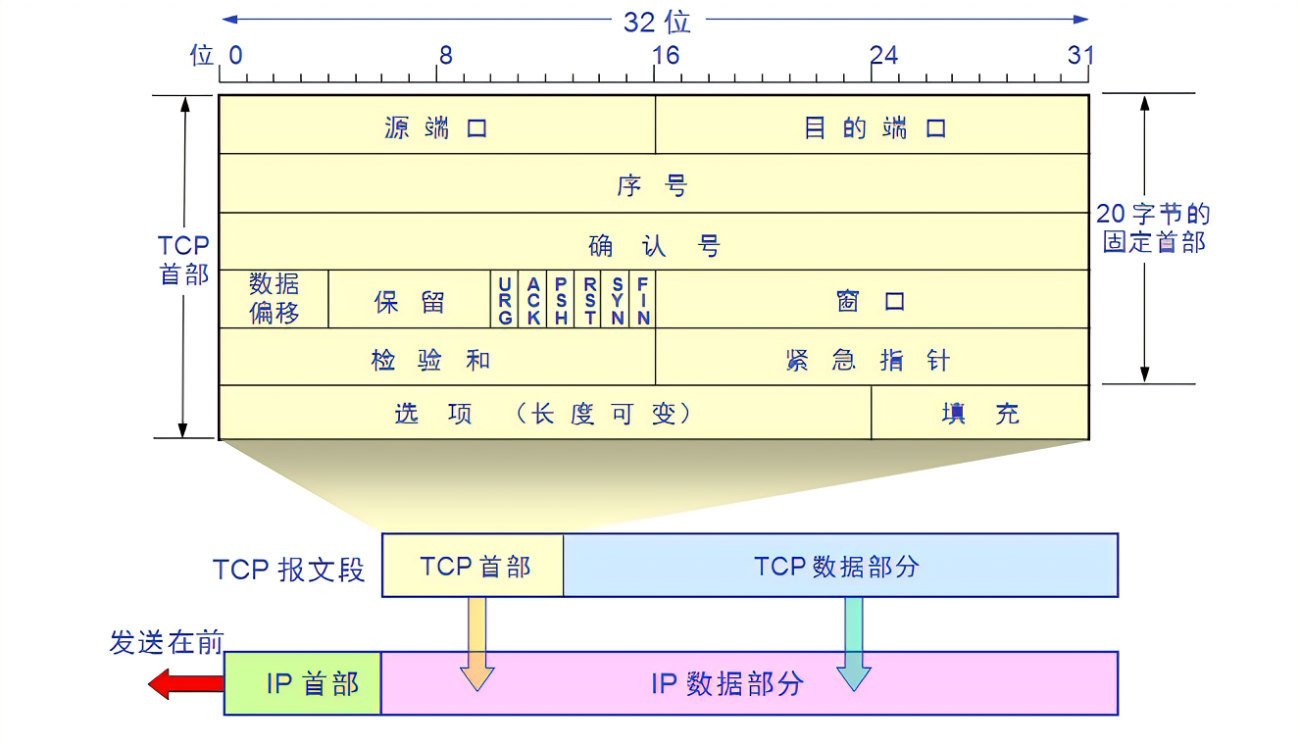
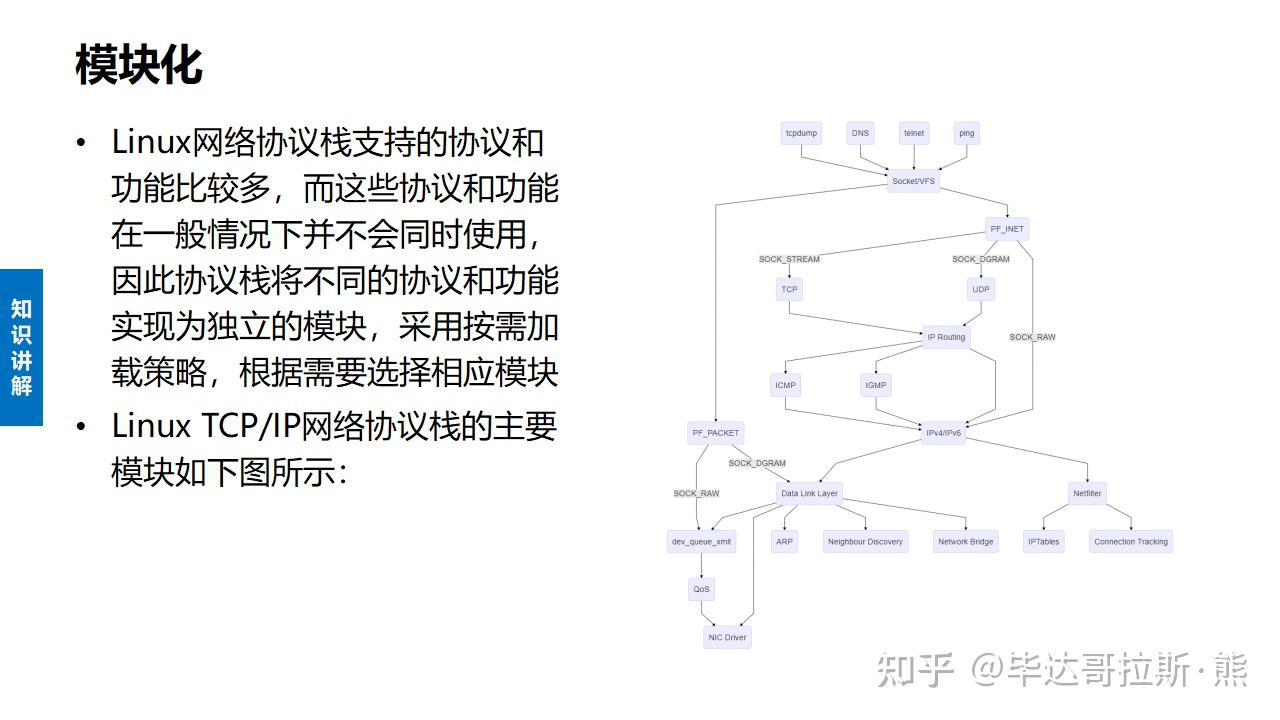
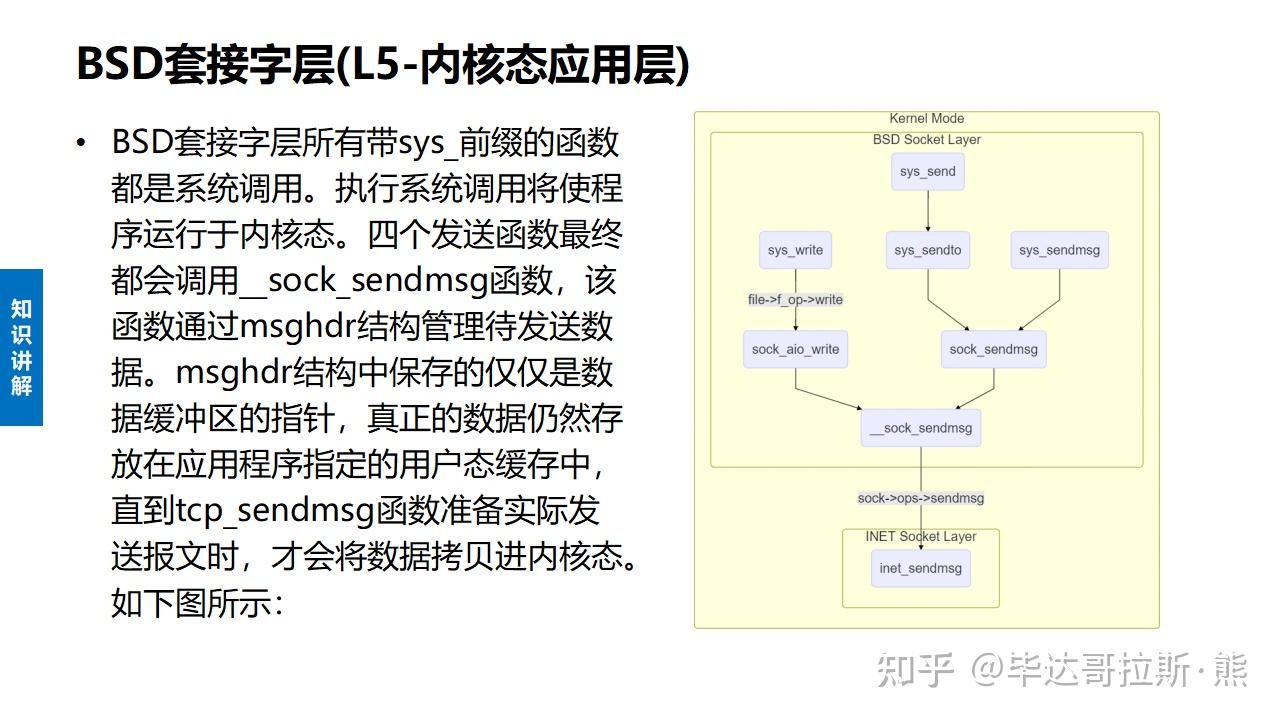
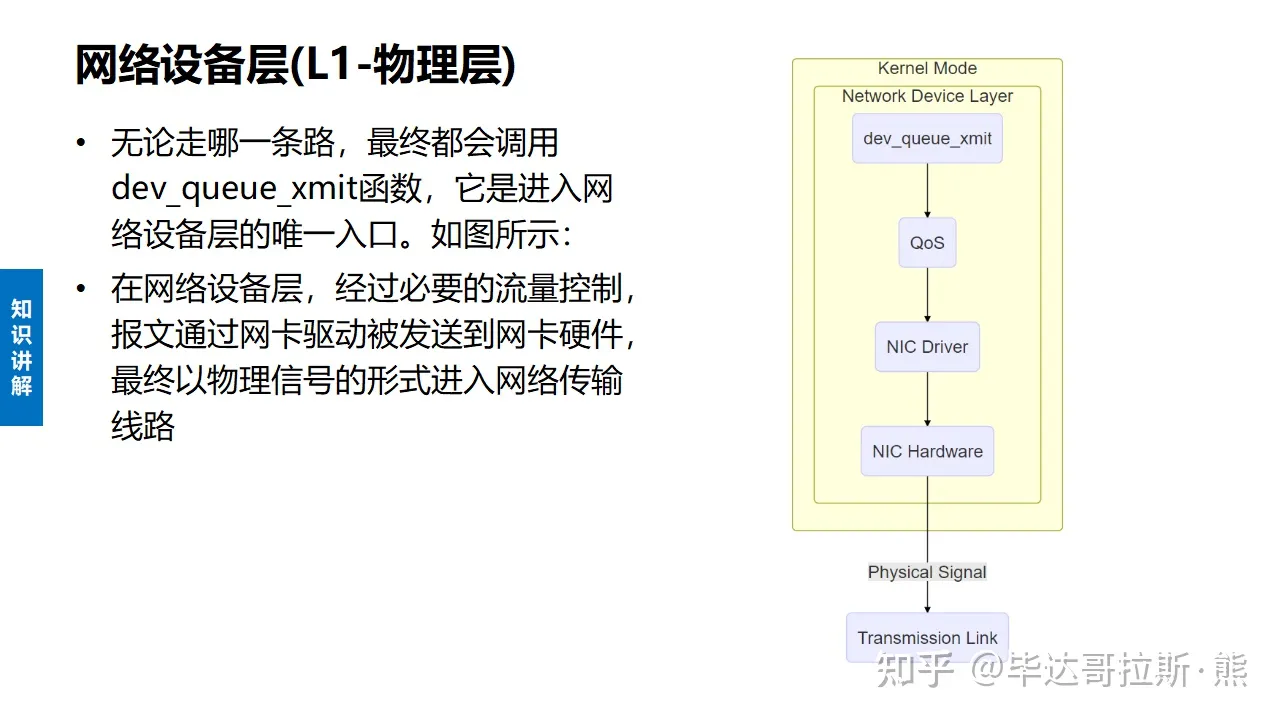
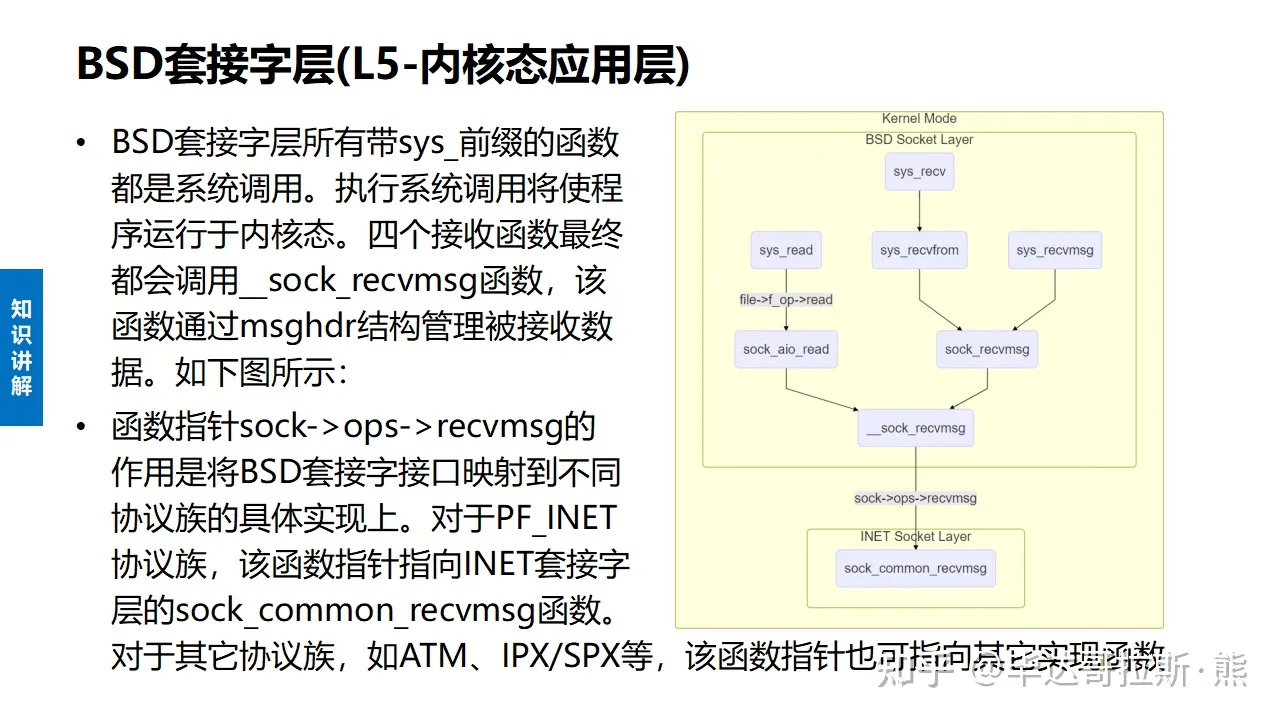
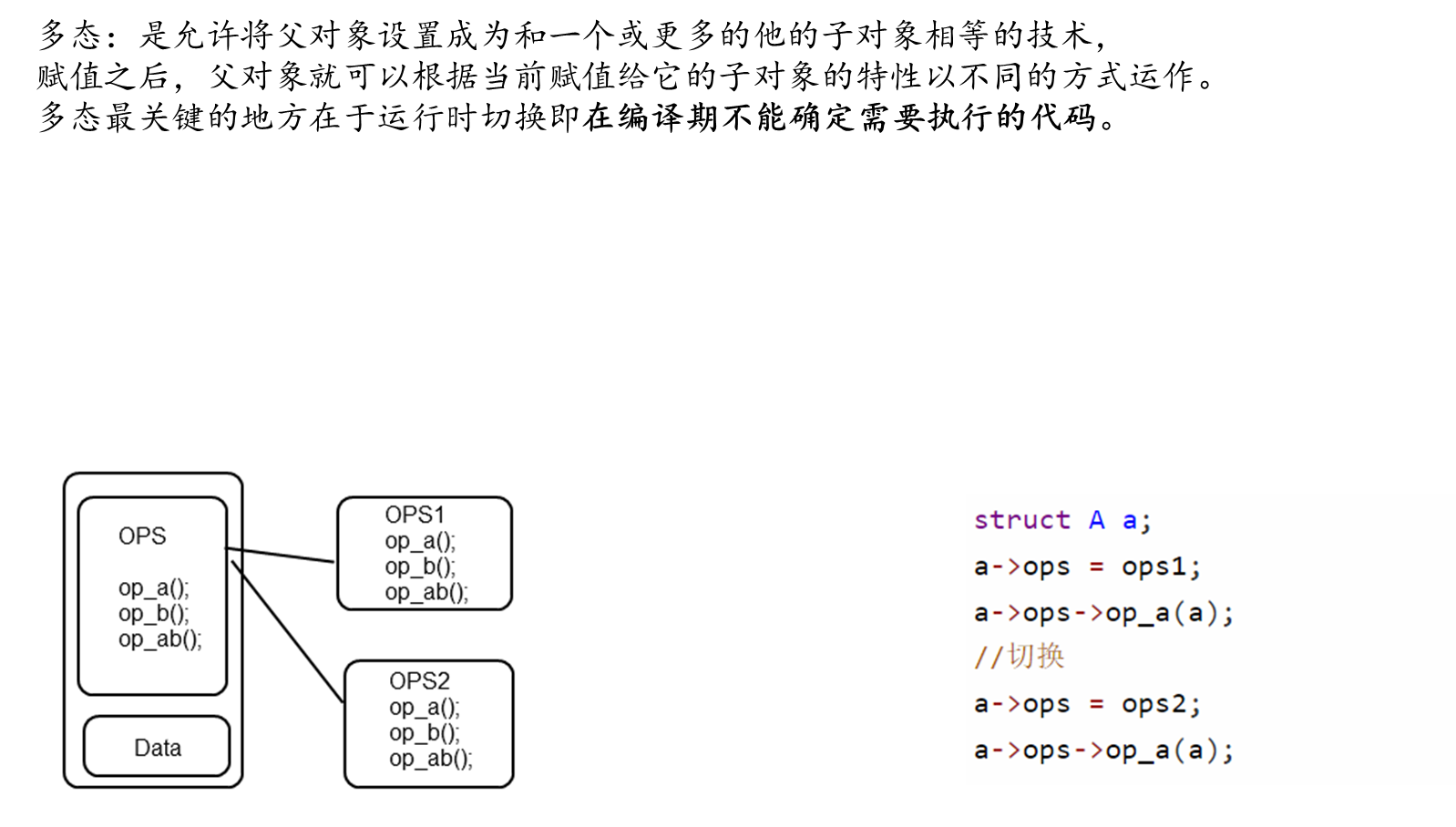
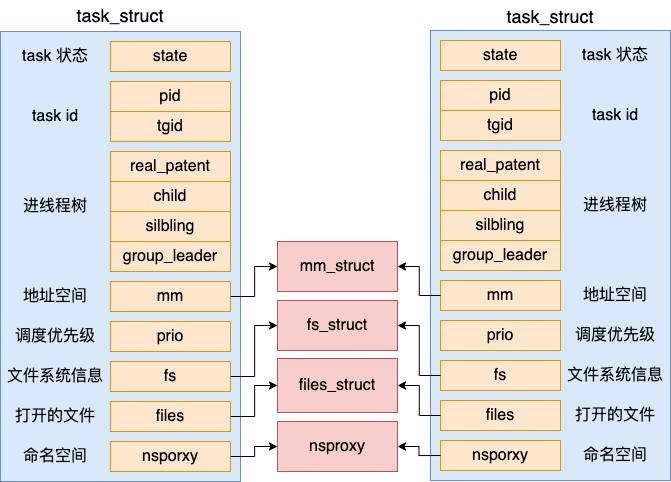
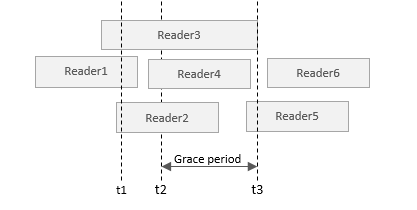
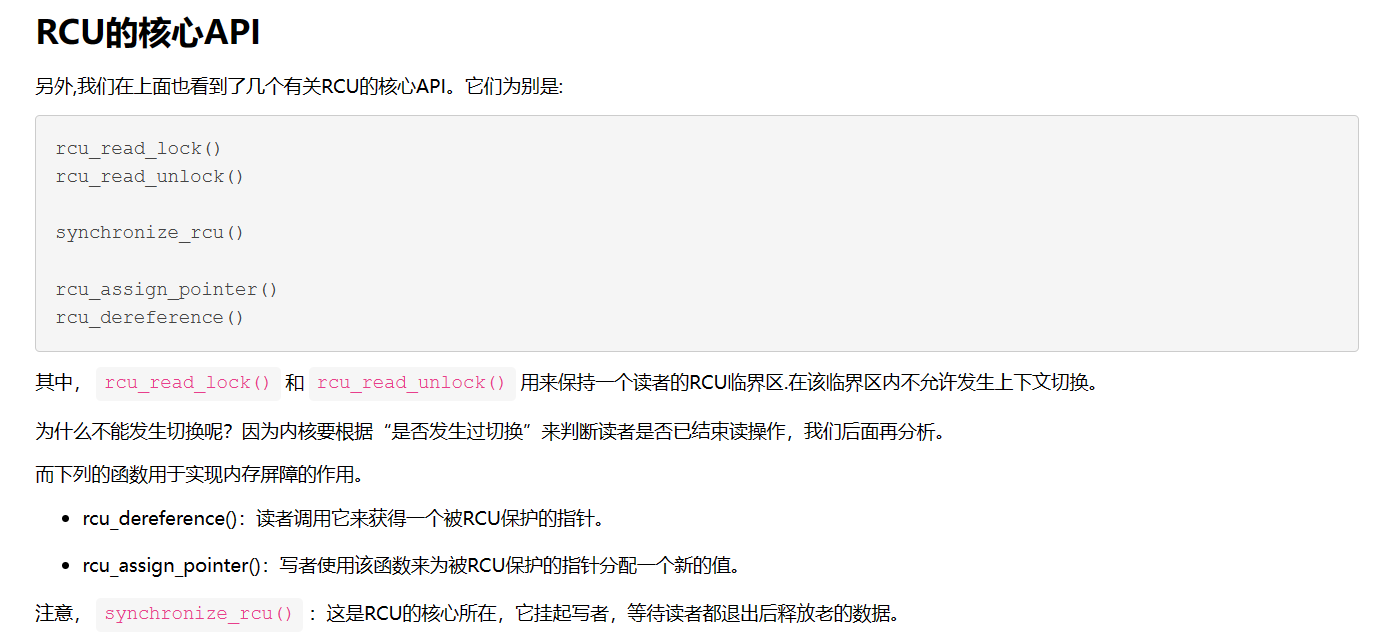
LwIP 协议栈之 udp 协议解析 UDP报文头部:8字节 伪首部完全是虚拟的,它并不会和用户数据报一起被发送出去,只是在校验和的计算过程中会被使用到,伪首部主要来自于运载 UDP 报文的 IP 数据报首部,将源 IP 地址和目的 IP 地址加入到校验和的计算中可以验证用户数据报是否已经到达正确的终点。
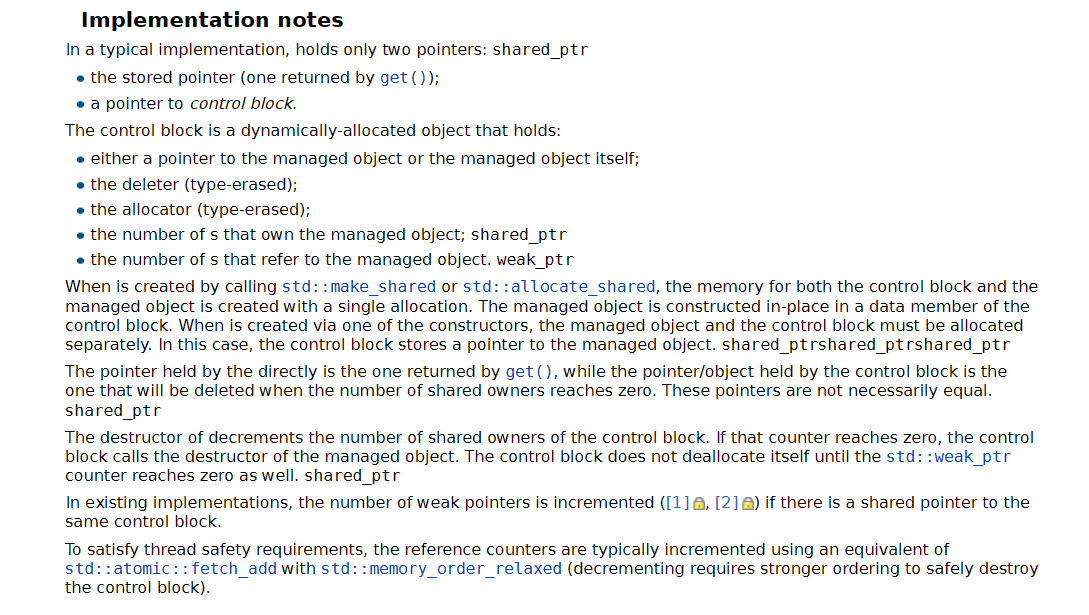
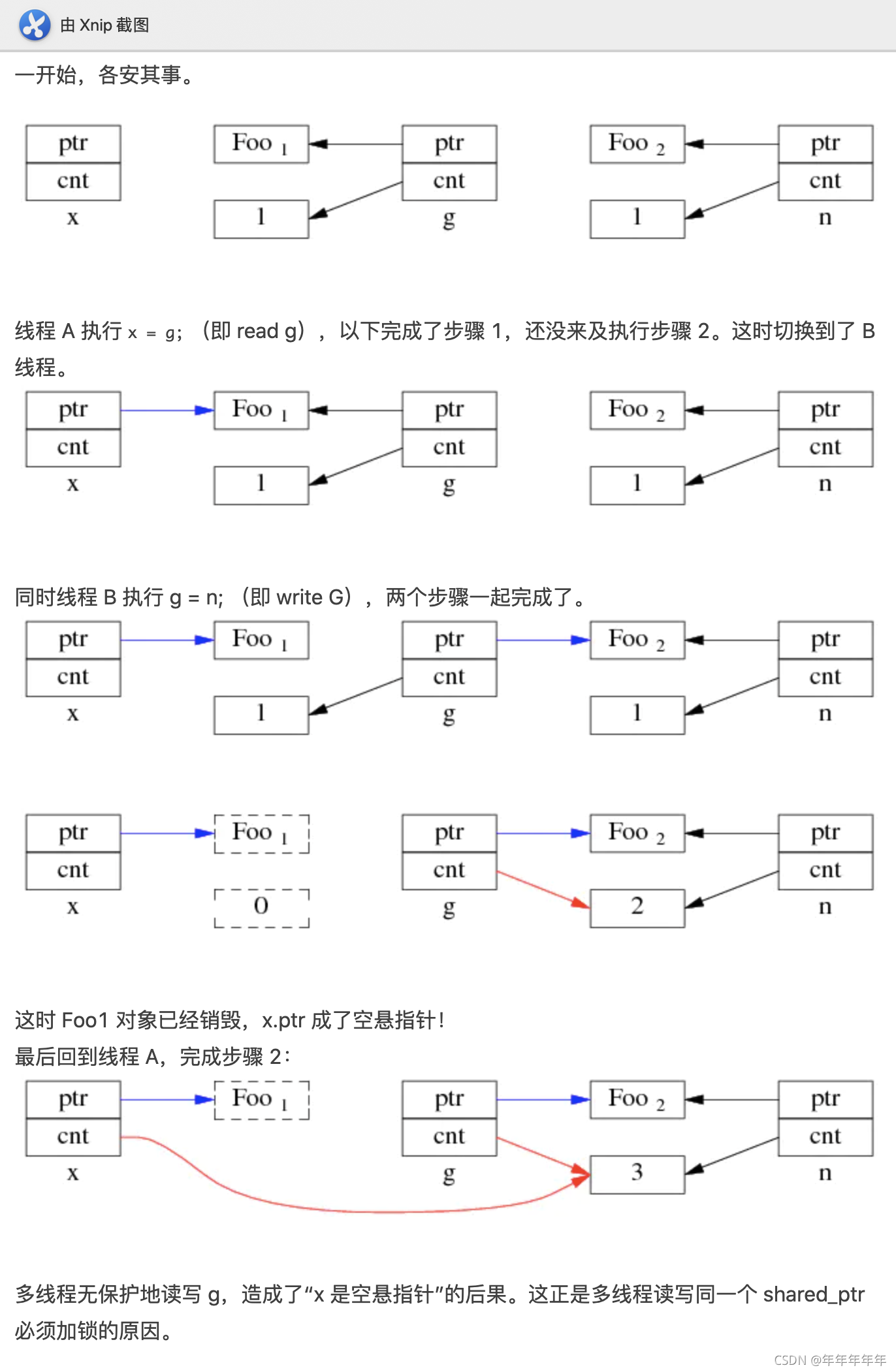
线程安全: 1 引用计数修改 线程安全 To satisfy thread safety requirements, the reference counters are typically incremented using an equivalent of std::atomic::fetch_add with std::memory_order_relaxed (decrementing requires stronger ordering to safely destroy the control block).
x = NewNode(key, height); for (int i = 0; i < height; i++) { // NoBarrier_SetNext() suffices since we will add a barrier when // we publish a pointer to "x" in prev[i]. x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i)); prev[i]->SetNext(i, x); }
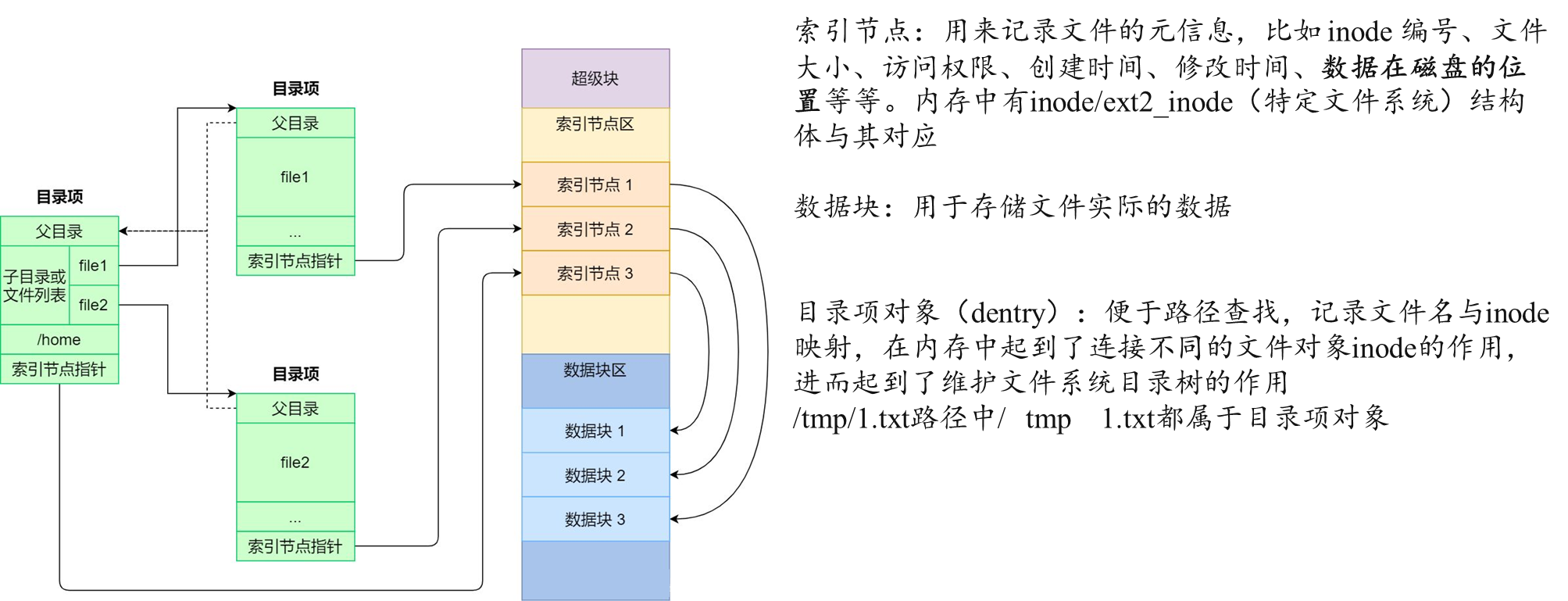
/* * Keep mostly read-only and often accessed (especially for * the RCU path lookup and 'stat' data) fields at the beginning * of the 'struct inode' */ structinode { umode_t i_mode; unsignedshort i_opflags; kuid_t i_uid; kgid_t i_gid; unsignedint i_flags;
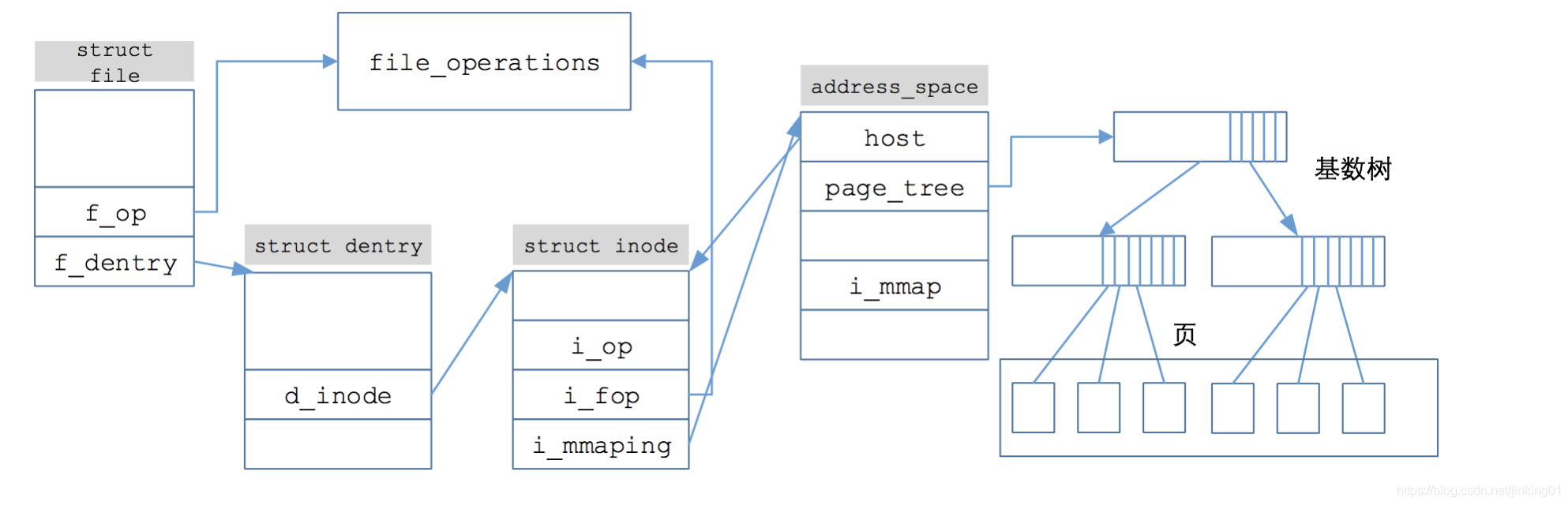
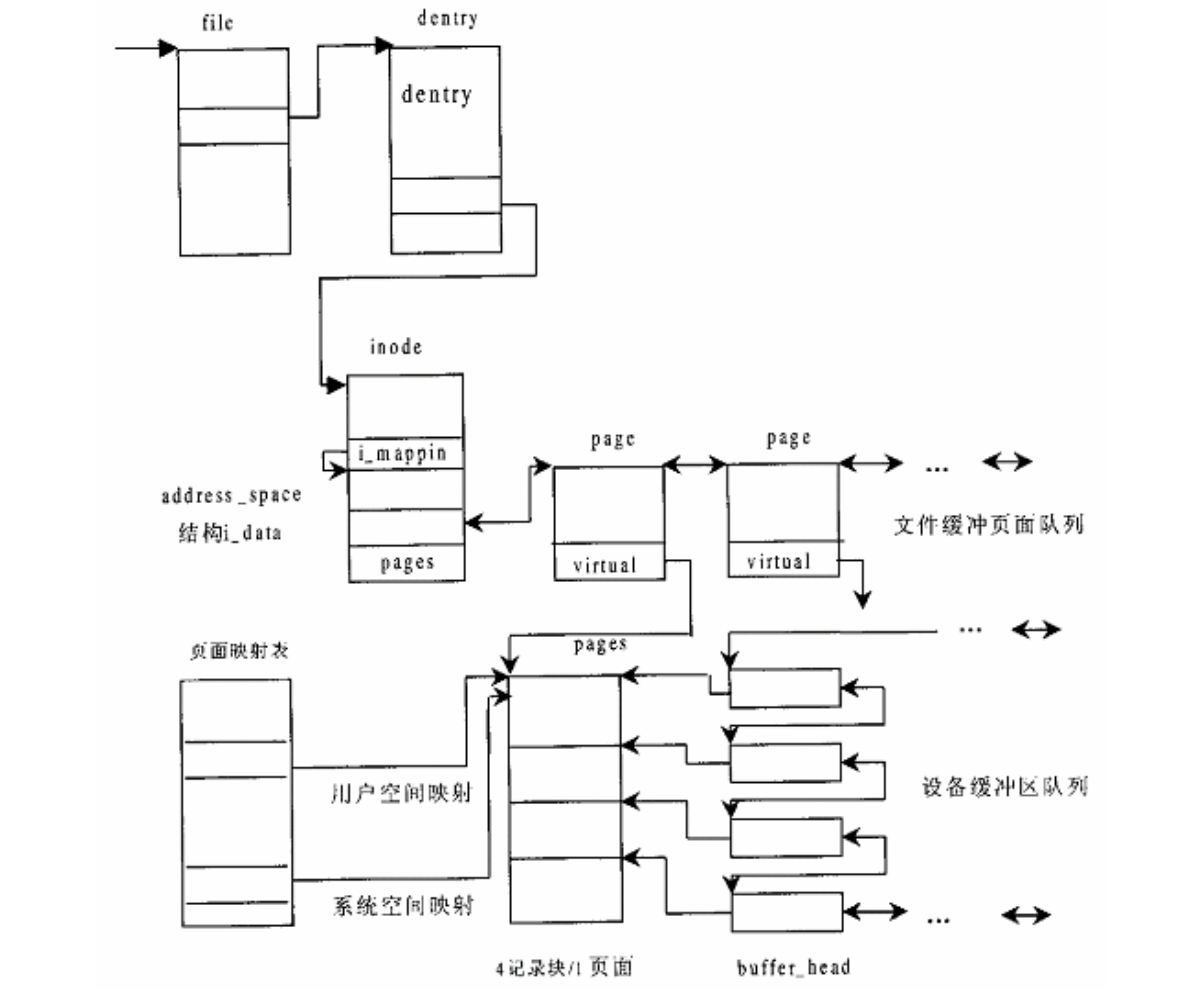
structaddress_space { structinode *host;/* owner: inode, block_device */ structradix_tree_rooti_pages;/* cached pages */ atomic_t i_mmap_writable;/* count VM_SHARED mappings */ structrb_root_cachedi_mmap;/* tree of private and shared mappings */ structrw_semaphorei_mmap_rwsem;/* protect tree, count, list */ /* Protected by the i_pages lock */ unsignedlong nrpages; /* number of total pages */ /* number of shadow or DAX exceptional entries */ unsignedlong nrexceptional; pgoff_t writeback_index;/* writeback starts here */ conststructaddress_space_operations *a_ops;/* methods */ unsignedlong flags; /* error bits */ spinlock_t private_lock; /* for use by the address_space */ gfp_t gfp_mask; /* implicit gfp mask for allocations */ structlist_headprivate_list;/* for use by the address_space */ void *private_data; /* ditto */ errseq_t wb_err; } __attribute__((aligned(sizeof(long)))) __randomize_layout;
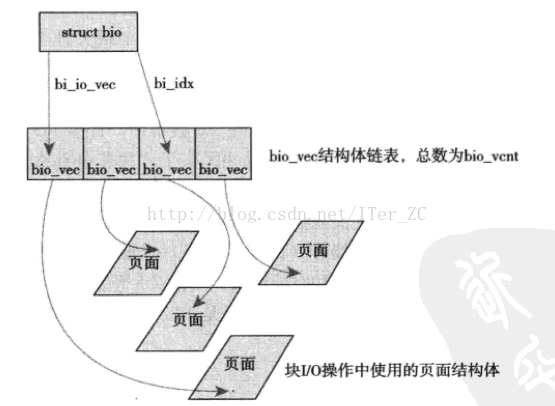
/* * Historically, a buffer_head was used to map a single block * within a page, and of course as the unit of I/O through the * filesystem and block layers. Nowadays the basic I/O unit * is the bio, and buffer_heads are used for extracting block * mappings (via a get_block_t call), for tracking state within * a page (via a page_mapping) and for wrapping bio submission * for backward compatibility reasons (e.g. submit_bh). */ structbuffer_head { unsignedlong b_state; /* buffer state bitmap (see above) */ structbuffer_head *b_this_page;/* circular list of page's buffers */ structpage *b_page;/* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */ size_t b_size; /* size of mapping */ char *b_data; /* pointer to data within the page */
structblock_device *b_bdev; bh_end_io_t *b_end_io; /* I/O completion */ void *b_private; /* reserved for b_end_io */ structlist_headb_assoc_buffers;/* associated with another mapping */ structaddress_space *b_assoc_map;/* mapping this buffer is associated with */ atomic_t b_count; /* users using this buffer_head */ };
/* MakeRoomForWrite MaybeScheduleCompaction BGWork BackgroundCall BackgroundCompaction DoCompactionWork */ // 省略大部分代码 Status DBImpl::DoCompactionWork(CompactionState* compact){ input->SeekToFirst(); Status status; ParsedInternalKey ikey; std::string current_user_key; bool has_current_user_key = false; SequenceNumber last_sequence_for_key = kMaxSequenceNumber; while (input->Valid()) { // Handle key/value, add to state, etc. bool drop = false; ParseInternalKey(key, &ikey) if (!has_current_user_key || user_comparator()->Compare(ikey.user_key, Slice(current_user_key)) != 0) { // First occurrence of this user key current_user_key.assign(ikey.user_key.data(), ikey.user_key.size()); has_current_user_key = true; last_sequence_for_key = kMaxSequenceNumber; }
if (last_sequence_for_key <= compact->smallest_snapshot) { // Hidden by an newer entry for same user key drop = true; // (A) } elseif (ikey.type == kTypeDeletion && ikey.sequence <= compact->smallest_snapshot && compact->compaction->IsBaseLevelForKey(ikey.user_key)) { // For this user key: // (1) there is no data in higher levels // (2) data in lower levels will have larger sequence numbers // (3) data in layers that are being compacted here and have // smaller sequence numbers will be dropped in the next // few iterations of this loop (by rule (A) above). // Therefore this deletion marker is obsolete and can be dropped. drop = true; } last_sequence_for_key = ikey.sequence;
if (!drop) { // Open output file if necessary if (compact->builder == nullptr) { status = OpenCompactionOutputFile(compact); if (!status.ok()) { break; } } if (compact->builder->NumEntries() == 0) { compact->current_output()->smallest.DecodeFrom(key); } compact->current_output()->largest.DecodeFrom(key); compact->builder->Add(key, input->value());
// Close output file if it is big enough if (compact->builder->FileSize() >= compact->compaction->MaxOutputFileSize()) { status = FinishCompactionOutputFile(compact, input); if (!status.ok()) { break; } }
input->Next(); } return status; }
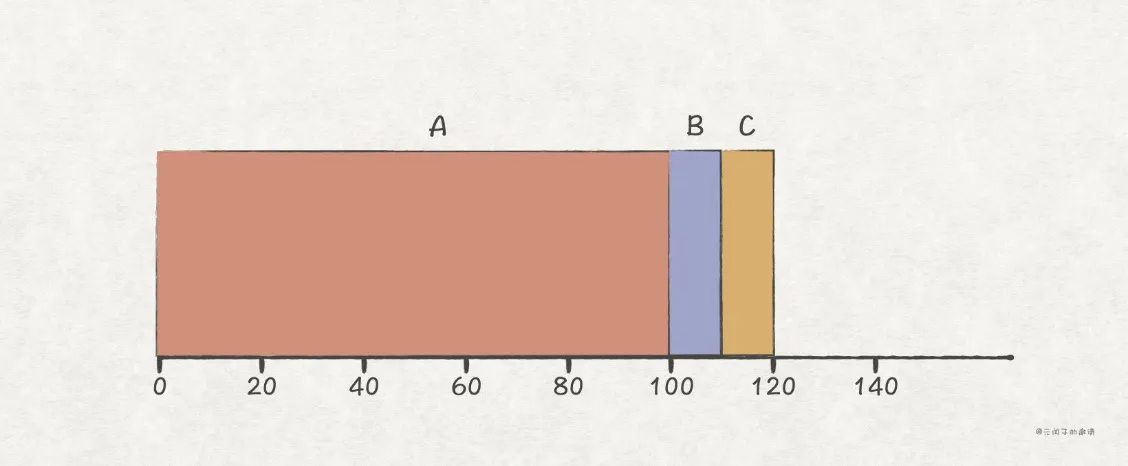
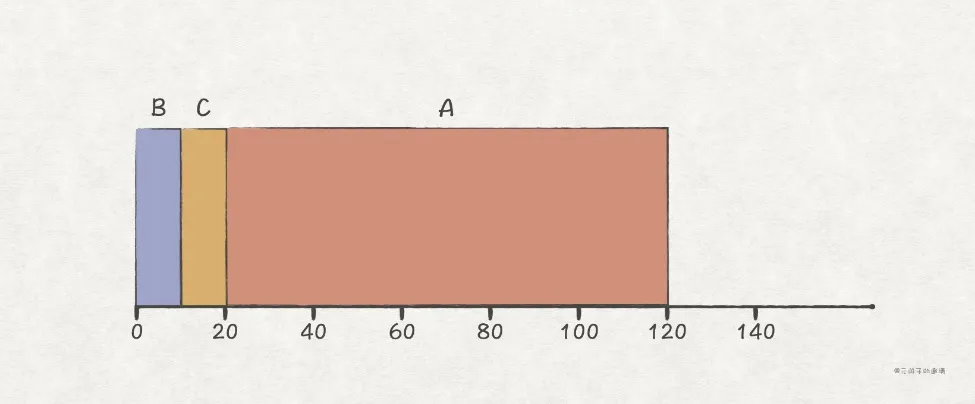
首先,对于相同的key,序列号越大,排序越小,越靠前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
intInternalKeyComparator::Compare(const Slice& akey, const Slice& bkey)const{ // Order by: // increasing user key (according to user-supplied comparator) // decreasing sequence number // decreasing type (though sequence# should be enough to disambiguate) int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey)); // 先使用user key比较器进行比较 if (r == 0) { // 若user key相等则比较序列号 constuint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8); constuint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8); if (anum > bnum) { // 按序列号降序排序 r = -1; } elseif (anum < bnum) { r = +1; } } return r; }
if (last_sequence_for_key <= compact->smallest_snapshot) { // Hidden by an newer entry for same user key drop = true; // (A) } elseif (ikey.type == kTypeDeletion && ikey.sequence <= compact->smallest_snapshot && compact->compaction->IsBaseLevelForKey(ikey.user_key)) { // For this user key: // (1) there is no data in higher levels // (2) data in lower levels will have larger sequence numbers // (3) data in layers that are being compacted here and have // smaller sequence numbers will be dropped in the next // few iterations of this loop (by rule (A) above). // Therefore this deletion marker is obsolete and can be dropped. drop = true; }
classDate { public: Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month),_day(day) {} voidSetTimeOfDate(int hour, int minute, int second) { // 直接访问时间类私有的成员变量 _t._hour = hour; _t._minute = minute; _t.second = second; } private: int _year; int _month; int _day; Time _t; };
存储过程
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/*in 输入参数的存储过程 输入id查询的行*/ DELIMITER $$ CREATEPROCEDURE b(IN pr_id INT) BEGIN SELECT*FROM a WHERE id=pr_id;
END$$ DELIMITER $$
/*out 的存储过程的说法*/ DELIMITER $$ CREATEPROCEDURE c(OUT pr_name VARCHAR(20)) BEGIN