源码地址:linux-4.19.90\drivers\net\ethernet\realtek\r8169.c
源码阅读环境:Windows 搭建 opengrok|极客教程
在线阅读网站:bootlin
注意:为把握函数主要功能,我忽略了许多出错处理的代码
初始化
阅读网卡驱动源码第一步,简要看一下发送描述符,接收描述符,发送缓存区,接收缓冲区定义与初始化
RTL8169数据手册
第九节介绍发送描述符与接收描述符
发送描述符
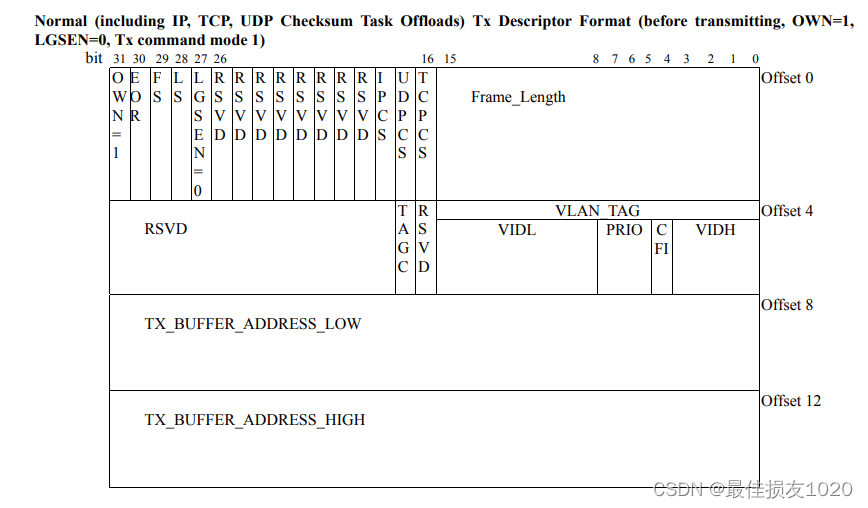
接收描述符

1
2
3
4
5
6
7
8
9
10
11
12
|
596 struct TxDesc {
597 __le32 opts1;
598 __le32 opts2;
599 __le64 addr;
600 };
602 struct RxDesc {
603 __le32 opts1;
604 __le32 opts2;
605 __le64 addr;
606 };
|
手册中写明了描述符的大小与字节对齐要求
Each descriptor consists of 4 consecutive double words. The start address of each descriptor group should be 256-byte alignment.
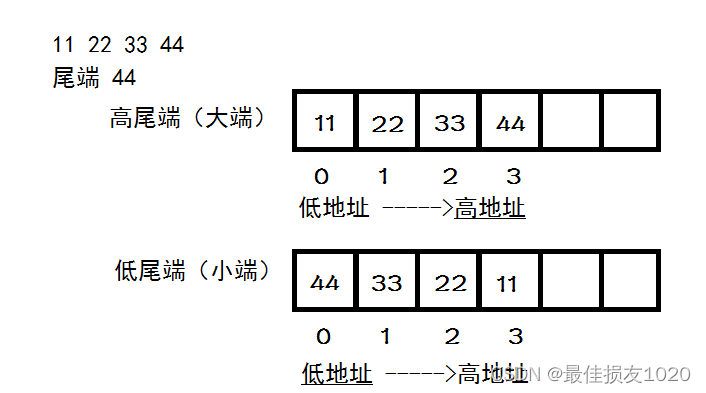
轻松记住大端小端的含义(附对大端和小端的解释)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
650 struct rtl8169_private {
657 u32 cur_rx;
658 u32 cur_tx;
659 u32 dirty_tx;
660 struct rtl8169_stats rx_stats;
661 struct rtl8169_stats tx_stats;
662 struct TxDesc *TxDescArray;
663 struct RxDesc *RxDescArray;
664 dma_addr_t TxPhyAddr;
665 dma_addr_t RxPhyAddr;
666 void *Rx_databuff[NUM_RX_DESC];
667 struct ring_info tx_skb[NUM_TX_DESC];
715 };
608 struct ring_info {
609 struct sk_buff *skb;
610 u32 len;
611 u8 __pad[sizeof(void *) - sizeof(u32)];
612 };
74 #define R8169_REGS_SIZE 256
75 #define R8169_RX_BUF_SIZE (SZ_16K - 1)
76 #define NUM_TX_DESC 64
77 #define NUM_RX_DESC 256U
78 #define R8169_TX_RING_BYTES (NUM_TX_DESC * sizeof(struct TxDesc))
79 #define R8169_RX_RING_BYTES (NUM_RX_DESC * sizeof(struct RxDesc))
6860
6864 tp->TxDescArray = dma_alloc_coherent(&pdev->dev, R8169_TX_RING_BYTES,
6865 &tp->TxPhyAddr, GFP_KERNEL);
6869 tp->RxDescArray = dma_alloc_coherent(&pdev->dev, R8169_RX_RING_BYTES,
6870 &tp->RxPhyAddr, GFP_KERNEL);
4313 static void rtl8169_init_ring_indexes(struct rtl8169_private *tp)
4314 {
4315 tp->dirty_tx = tp->cur_tx = tp->cur_rx = 0;
4316 }
5950 static inline void rtl8169_mark_as_last_descriptor(struct RxDesc *desc)
5951 {
5952 desc->opts1 |= cpu_to_le32(RingEnd);
5953 }
5978 static int rtl8169_init_ring(struct rtl8169_private *tp)
5979 {
5980 rtl8169_init_ring_indexes(tp);
5981
5982 memset(tp->tx_skb, 0, sizeof(tp->tx_skb));
5983 memset(tp->Rx_databuff, 0, sizeof(tp->Rx_databuff));
5984
5985 return rtl8169_rx_fill(tp);
5986 }
5955 static int rtl8169_rx_fill(struct rtl8169_private *tp)
5956 {
5957 unsigned int i;
5958
5959 for (i = 0; i < NUM_RX_DESC; i++) {
5960 void *data;
5961
5962 data = rtl8169_alloc_rx_data(tp, tp->RxDescArray + i);
5967 tp->Rx_databuff[i] = data;
5968 }
5969
5970 rtl8169_mark_as_last_descriptor(tp->RxDescArray + NUM_RX_DESC - 1);
5971 return 0;
5976 }
5902 static struct sk_buff *rtl8169_alloc_rx_data(struct rtl8169_private *tp,
5903 struct RxDesc *desc)
5904 {
5905 void *data;
5906 dma_addr_t mapping;
5907 struct device *d = tp_to_dev(tp);
5908 int node = dev_to_node(d);
5910 data = kmalloc_node(R8169_RX_BUF_SIZE, GFP_KERNEL, node);
5921 mapping = dma_map_single(d, rtl8169_align(data), R8169_RX_BUF_SIZE,
5922 DMA_FROM_DEVICE);
5929 desc->addr = cpu_to_le64(mapping);
5930 rtl8169_mark_to_asic(desc);
5931 return data;
5936 }
|
可以看到TxDescArray RxDescArray使用了一致性DMA映射(dma_alloc_coherent),其中的数据存放采用流式DMA映射(DMA_FROM_DEVICE)。一致性DMA映射与流式DMA映射的不同见以下博客
一致性DMA映射与流式DMA映射
dma_addr_t与流式映射和一致性映射
一致性DMA映射不使用Cache,流式DMA映射谨慎地使用Cache
x86_64硬件保证了DMA一致性,无需考虑一致性DMA映射与流式DMA映射。
流式DMA映射根据数据方向对cache进行”flush/invalid”,既保证了数据一致性,也避免了完全关闭cache带来的性能影响。既然如此,为什么不抛弃一致性DMA映射,全面拥抱“更强大”的流式DMA映射呢?
考虑如下情况:当CPU和DMA需要频繁的操作一块内存区域的时候,如果采用流式DMA映射的话,需要频繁的”cache flush/invalid”操作(没有cache hit或者write hit的话,cache存在的意义就不大了),而刷cache是比较耗时的,就会导致开销比较大。这个时候,更适合采用一致性DMA映射。
接下来阅读寄存器映射相关代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 650 struct rtl8169_private {
651 void __iomem *mmio_addr;
715 };
83
84 #define RTL_W8(tp, reg, val8) writeb((val8), tp->mmio_addr + (reg))
85 #define RTL_W16(tp, reg, val16) writew((val16), tp->mmio_addr + (reg))
86 #define RTL_W32(tp, reg, val32) writel((val32), tp->mmio_addr + (reg))
87 #define RTL_R8(tp, reg) readb(tp->mmio_addr + (reg))
88 #define RTL_R16(tp, reg) readw(tp->mmio_addr + (reg))
89 #define RTL_R32(tp, reg) readl(tp->mmio_addr + (reg))
247 enum rtl_registers {
248 MAC0 = 0,
249 MAC4 = 4,
250 MAR0 = 8,
251 CounterAddrLow = 0x10,
252 CounterAddrHigh = 0x14,
253 TxDescStartAddrLow = 0x20,
254 TxDescStartAddrHigh = 0x24,
255 TxHDescStartAddrLow = 0x28,
256 TxHDescStartAddrHigh = 0x2c,
257 FLASH = 0x30,
258 ERSR = 0x36,
259 ChipCmd = 0x37,
260 TxPoll = 0x38,
261 IntrMask = 0x3c,
262 IntrStatus = 0x3e,
320 };
|
其中__iomem是linux2.6.9内核中加入的特性。用来个表示指针是指向一个I/O的内存空间,主要是为了驱动程序的通用性考虑。由于不同的CPU体系结构对I/O空间的表示可能不同,当使用__iomem时,编译器会忽略对变量的检查(因为用的是void __iomem)。若要对它进行检查,当__iomem的指针和正常的指针混用时,就会发出一些警告。
寄存器内存映射代码如下:
1
2
3
4
5
6
7
8
9
| 7489
7490 region = ffs(pci_select_bars(pdev, IORESOURCE_MEM)) - 1;
7496
7497 if (pci_resource_len(pdev, region) < R8169_REGS_SIZE) {
7498 dev_err(&pdev->dev, "Invalid PCI region size(s), aborting\n");
7499 return -ENODEV;
7500 }
7502 rc = pcim_iomap_regions(pdev, BIT(region), MODULENAME);
7508 tp->mmio_addr = pcim_iomap_table(pdev)[region];
|
其中一些内核函数的实现源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| 5664 int pci_select_bars(struct pci_dev *dev, unsigned long flags)
5665 {
5666 int i, bars = 0;
5667 for (i = 0; i < PCI_NUM_RESOURCES; i++)
5668 if (pci_resource_flags(dev, i) & flags)
5669 bars |= (1 << i);
5670 return bars;
5671 }
13 static inline int ffs(int x)
14 {
15 int r = 1;
16
17 if (!x)
18 return 0;
19 if (!(x & 0xffff)) {
20 x >>= 16;
21 r += 16;
22 }
23 if (!(x & 0xff)) {
24 x >>= 8;
25 r += 8;
26 }
27 if (!(x & 0xf)) {
28 x >>= 4;
29 r += 4;
30 }
31 if (!(x & 3)) {
32 x >>= 2;
33 r += 2;
34 }
35 if (!(x & 1)) {
36 x >>= 1;
37 r += 1;
38 }
39 return r;
40 }
6 #define BIT(nr) (1UL << (nr))
370 int pcim_iomap_regions(struct pci_dev *pdev, int mask, const char *name)
371 {
372 void __iomem * const *iomap;
373 int i, rc;
374
375 iomap = pcim_iomap_table(pdev);
376 if (!iomap)
377 return -ENOMEM;
378
379 for (i = 0; i < DEVICE_COUNT_RESOURCE; i++) {
380 unsigned long len;
381
382 if (!(mask & (1 << i)))
383 continue;
384
386 len = pci_resource_len(pdev, i);
390 rc = pci_request_region(pdev, i, name);
395 if (!pcim_iomap(pdev, i, 0))
396 goto err_region;
397 }
398
399 return 0;
400
321 void __iomem *pcim_iomap(struct pci_dev *pdev, int bar, unsigned long maxlen)
322 {
323 void __iomem **tbl;
327 tbl = (void __iomem **)pcim_iomap_table(pdev);
331 tbl[bar] = pci_iomap(pdev, bar, maxlen);
332 return tbl[bar];
333 }
|
linux驱动 关于资源resource
发包
然后看网络设备的操作函数,简要分析发包过程
1
2
3
4
5
6
| 7193 static const struct net_device_ops rtl_netdev_ops = {
7194 .ndo_open = rtl_open,
7195 .ndo_stop = rtl8169_close,
7197 .ndo_start_xmit = rtl8169_start_xmit,
7198 .ndo_tx_timeout = rtl8169_tx_timeout,
7210 };
|
1、网卡驱动创建tx descriptor ring(一致性DMA内存),将tx descriptor ring的总线地址写入网卡寄存器
2、协议栈通过dev_queue_xmit()将sk_buff下送网卡驱动
3、网卡驱动将sk_buff放入tx descriptor ring,更新TDT
4、DMA感知到TDT的改变后,找到tx descriptor ring中下一个将要使用的descriptor
5、DMA通过PCI总线将descriptor的数据缓存区复制到Tx FIFO
6、复制完后,通过MAC芯片将数据包发送出去
7、发送完后,网卡更新TDH,启动硬中断通知CPU释放数据缓存区中的数据包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
4569 static void rtl_set_rx_tx_desc_registers(struct rtl8169_private *tp)
4570 {
4571
4576 RTL_W32(tp, TxDescStartAddrHigh, ((u64) tp->TxPhyAddr) >> 32);
4577 RTL_W32(tp, TxDescStartAddrLow, ((u64) tp->TxPhyAddr) & DMA_BIT_MASK(32));
4578 RTL_W32(tp, RxDescAddrHigh, ((u64) tp->RxPhyAddr) >> 32);
4579 RTL_W32(tp, RxDescAddrLow, ((u64) tp->RxPhyAddr) & DMA_BIT_MASK(32));
4580 }
6279 static netdev_tx_t rtl8169_start_xmit(struct sk_buff *skb,
6280 struct net_device *dev)
6281 {
6282 struct rtl8169_private *tp = netdev_priv(dev);
6283 unsigned int entry = tp->cur_tx % NUM_TX_DESC;
6284 struct TxDesc *txd = tp->TxDescArray + entry;
6285 struct device *d = tp_to_dev(tp);
6286 dma_addr_t mapping;
6287 u32 status, len;
6288 u32 opts[2];
6289 int frags;
6290
6291 if (unlikely(!TX_FRAGS_READY_FOR(tp, skb_shinfo(skb)->nr_frags))) {
6292 netif_err(tp, drv, dev, "BUG! Tx Ring full when queue awake!\n");
6293 goto err_stop_0;
6294 }
6295
6296 if (unlikely(le32_to_cpu(txd->opts1) & DescOwn))
6297 goto err_stop_0;
6298
6299 opts[1] = cpu_to_le32(rtl8169_tx_vlan_tag(skb));
6300 opts[0] = DescOwn;
6301
6302 if (!tp->tso_csum(tp, skb, opts)) {
6303 r8169_csum_workaround(tp, skb);
6304 return NETDEV_TX_OK;
6305 }
6306
6307 len = skb_headlen(skb);
6308 mapping = dma_map_single(d, skb->data, len, DMA_TO_DEVICE);
6315 tp->tx_skb[entry].len = len;
6316 txd->addr = cpu_to_le64(mapping);
6317
6318 frags = rtl8169_xmit_frags(tp, skb, opts);
6319 if (frags < 0)
6320 goto err_dma_1;
6321 else if (frags)
6322 opts[0] |= FirstFrag;
6323 else {
6324 opts[0] |= FirstFrag | LastFrag;
6325 tp->tx_skb[entry].skb = skb;
6326 }
6327
6328 txd->opts2 = cpu_to_le32(opts[1]);
6329
6330 skb_tx_timestamp(skb);
6331
6332
6333 dma_wmb();
6334
6335
6336 status = opts[0] | len | (RingEnd * !((entry + 1) % NUM_TX_DESC));
6337 txd->opts1 = cpu_to_le32(status);
6338
6339
6340 wmb();
6341
6342 tp->cur_tx += frags + 1;
6343
6344 RTL_W8(tp, TxPoll, NPQ);
6345
6346 mmiowb();
6347
6348 if (!TX_FRAGS_READY_FOR(tp, MAX_SKB_FRAGS)) {
6349
6352 smp_wmb();
6353 netif_stop_queue(dev);
6354
6361 smp_mb();
6362 if (TX_FRAGS_READY_FOR(tp, MAX_SKB_FRAGS))
6363 netif_wake_queue(dev);
6364 }
6366 return NETDEV_TX_OK;
6379 }
|
rtl8169_start_xmit函数的主要功能就是解析skb中的数据,填充发送描述符,而后发包。
发送描述符定义如下:
1
2
3
4
5
| 596 struct TxDesc {
597 __le32 opts1;
598 __le32 opts2;
599 __le64 addr;
600 };
|
sk_buff结构体结构体示意图如下:
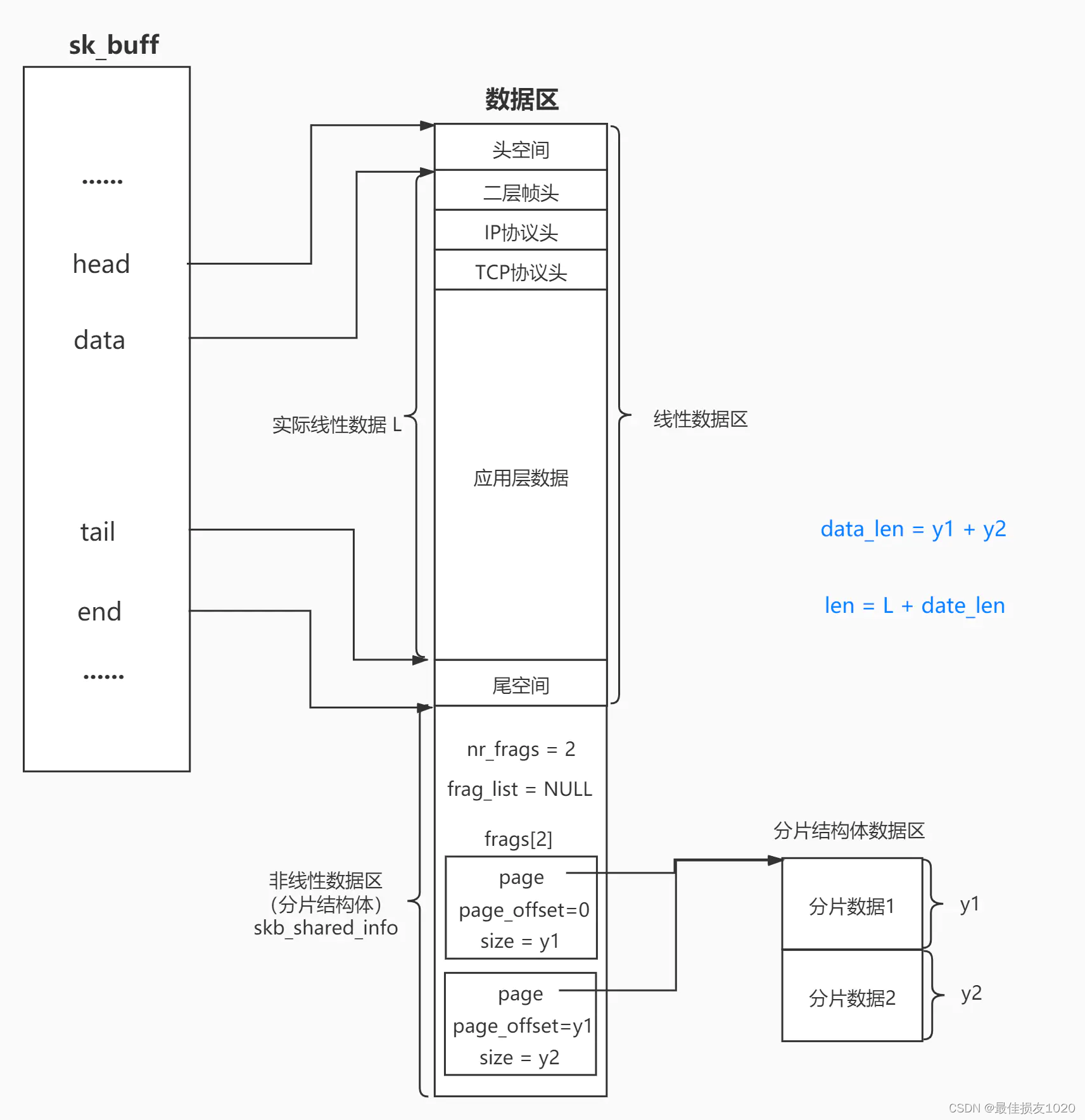
Linux内核中sk_buff结构详解
描述符状态定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
532 enum rtl_desc_bit {
533
534 DescOwn = (1 << 31),
535 RingEnd = (1 << 30),
536 FirstFrag = (1 << 29),
537 LastFrag = (1 << 28),
538 };
541 enum rtl_tx_desc_bit {
542
543 TD_LSO = (1 << 27),
544 #define TD_MSS_MAX 0x07ffu
545
546
547 TxVlanTag = (1 << 17),
548 };
549
550
551 enum rtl_tx_desc_bit_0 {
552
553 #define TD0_MSS_SHIFT 16
554 TD0_TCP_CS = (1 << 16),
555 TD0_UDP_CS = (1 << 17),
556 TD0_IP_CS = (1 << 18),
557 };
558
559
560 enum rtl_tx_desc_bit_1 {
561
562 TD1_GTSENV4 = (1 << 26),
563 TD1_GTSENV6 = (1 << 25),
564 #define GTTCPHO_SHIFT 18
565 #define GTTCPHO_MAX 0x7fU
566
567
568 #define TCPHO_SHIFT 18
569 #define TCPHO_MAX 0x3ffU
570 #define TD1_MSS_SHIFT 18
571 TD1_IPv6_CS = (1 << 28),
572 TD1_IPv4_CS = (1 << 29),
573 TD1_TCP_CS = (1 << 30),
574 TD1_UDP_CS = (1 << 31),
575 };
|
对照手册上的描述符定义图看
rtl8169_start_xmit函数涉及到的一些函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| 60 #define TX_SLOTS_AVAIL(tp) \
61 (tp->dirty_tx + NUM_TX_DESC - tp->cur_tx)
63
64 #define TX_FRAGS_READY_FOR(tp,nr_frags) \
65 (TX_SLOTS_AVAIL(tp) >= (nr_frags + 1))
1944 static inline unsigned int skb_headlen(const struct sk_buff *skb)
1945 {
1946 return skb->len - skb->data_len;
1947 }
6059 static int rtl8169_xmit_frags(struct rtl8169_private *tp, struct sk_buff *skb,
6060 u32 *opts)
6061 {
6062 struct skb_shared_info *info = skb_shinfo(skb);
6063 unsigned int cur_frag, entry;
6064 struct TxDesc *uninitialized_var(txd);
6065 struct device *d = tp_to_dev(tp);
6066
6067 entry = tp->cur_tx;
6068 for (cur_frag = 0; cur_frag < info->nr_frags; cur_frag++) {
6069 const skb_frag_t *frag = info->frags + cur_frag;
6070 dma_addr_t mapping;
6071 u32 status, len;
6072 void *addr;
6073
6074 entry = (entry + 1) % NUM_TX_DESC;
6075
6076 txd = tp->TxDescArray + entry;
6077 len = skb_frag_size(frag);
6078 addr = skb_frag_address(frag);
6079 mapping = dma_map_single(d, addr, len, DMA_TO_DEVICE);
6087
6088 status = opts[0] | len |
6089 (RingEnd * !((entry + 1) % NUM_TX_DESC));
6090
6091 txd->opts1 = cpu_to_le32(status);
6092 txd->opts2 = cpu_to_le32(opts[1]);
6093 txd->addr = cpu_to_le64(mapping);
6094
6095 tp->tx_skb[entry].len = len;
6096 }
6097
6098 if (cur_frag) {
6099 tp->tx_skb[entry].skb = skb;
6100 txd->opts1 |= cpu_to_le32(LastFrag);
6101 }
6102
6103 return cur_frag;
6108 }
|
收包
在阅读收包代码之前简要了解代码中时不时出现的缩写
TSO(TCP Segmentation Offload),是利用网卡对TCP数据包分片,减轻CPU负荷的一种技术,也有人叫 LSO (Large segment offload) ,TSO是针对TCP的,UFO是针对UDP的。如果硬件支持 TSO功能,同时也需要硬件支持的TCP校验计算和分散/聚集 (Scatter Gather) 功能。如果网卡支持TSO/GSO,可以把最多64K大小的TCP payload直接往下传给协议栈,此时IP层也不会进行segmentation,网卡会生成TCP/IP包头和帧头,这样可以offload很多协议栈上的内存操作,节省CPU资源,当然如果都是小包,那么功能基本就没啥用了。
GSO(Generic Segmentation Offload),GSO是TSO的增强 ,GSO不只针对TCP,对任意协议。比TSO更通用,推迟数据分片直至发送到网卡驱动之前,此时会检查网卡是否支持分片功能(如TSO、UFO),如果支持直接发送到网卡,如果不支持就进行分片后再发往网卡。
LRO(Large Receive Offload),通过将接收到的多个TCP数据聚合成一个大的数据包,然后传递给网络协议栈处理,以减少上层协议栈处理 开销,提高系统接收TCP数据包的能力。
GRO(Generic Receive Offload),跟LRO类似,克服了LRO的一些缺点,更通用。后续的驱动都使用GRO的接口,而不是LRO。
简要了解一下NAPI机制,它的核心概念就是不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收的服务程序,然后 POLL 的方法来轮询数据。

其中poll函数的budget参数用于控制软中断处理的时间
在net_rx_action()函数中还对每一次软中断处理的时间做了限制,这是由两个变量来控制的:
- time_limit = jiffies + 2,如果当前时间超过了time_limit,就强制终止此次软中断处理。即时间不能超过2个jiffies。
- budget = netdev_budget,每次poll函数返回,budget就减去此次收包数,当budget减到0时,就强制终止此次软中断处理。netdev_budget设置的值为300。
详见以下博客:
数据包接收系列 — NAPI的原理和实现
napi
Linux网络协议栈:NAPI机制与处理流程分析(图解)
由中断函数出发,分析其收包过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 6884 retval = pci_request_irq(pdev, 0, rtl8169_interrupt, NULL, tp,
6885 dev->name);
7592 netif_napi_add(dev, &tp->napi, rtl8169_poll, NAPI_POLL_WEIGHT);
6620 static irqreturn_t rtl8169_interrupt(int irq, void *dev_instance)
6621 {
6622 struct rtl8169_private *tp = dev_instance;
6623 u16 status = rtl_get_events(tp);
6624
6625 if (status == 0xffff || !(status & (RTL_EVENT_NAPI | tp->event_slow)))
6626 return IRQ_NONE;
6627
6628 rtl_irq_disable(tp);
6629 napi_schedule_irqoff(&tp->napi);
6630
6631 return IRQ_HANDLED;
6632 }
|
代码涉及到的寄存器介绍如下
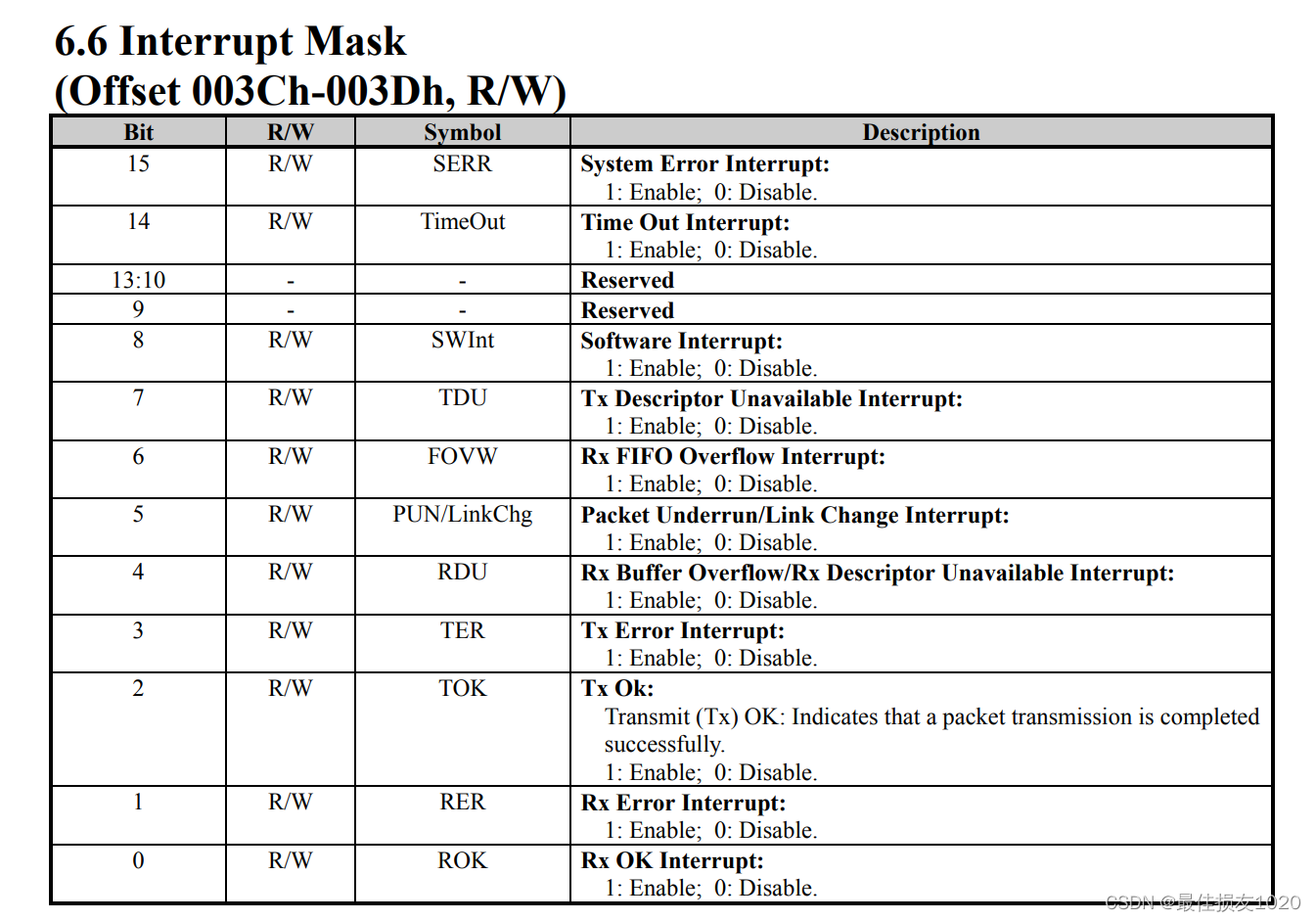
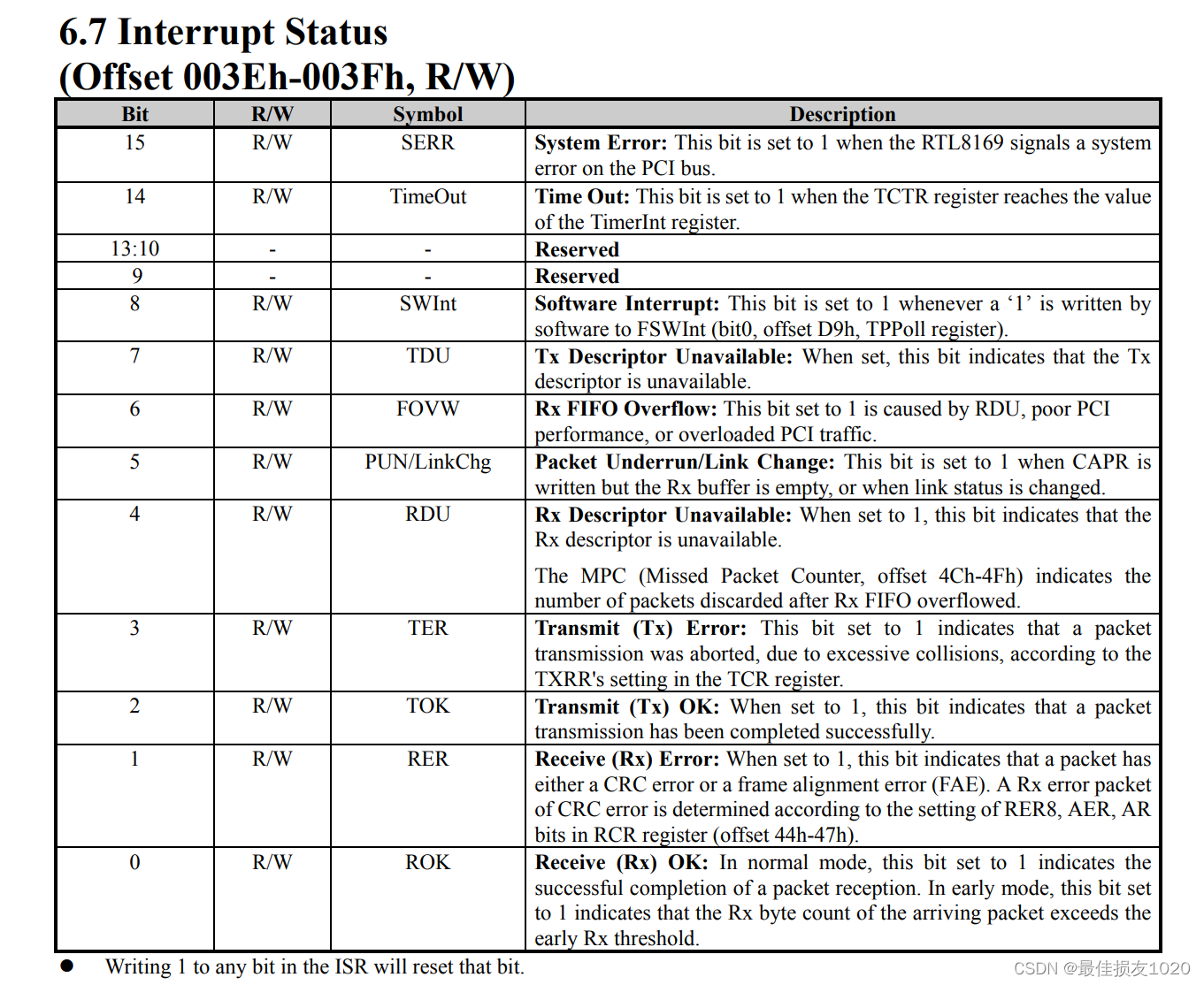
一些函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 1331 static u16 rtl_get_events(struct rtl8169_private *tp)
1332 {
1333 return RTL_R16(tp, IntrStatus);
1334 }
1342 static void rtl_irq_disable(struct rtl8169_private *tp)
1343 {
1344 RTL_W16(tp, IntrMask, 0);
1345 mmiowb();
1346 }
447
453 static inline void napi_schedule_irqoff(struct napi_struct *n)
454 {
455 if (napi_schedule_prep(n))
456 __napi_schedule_irqoff(n);
457 }
|
中断上半部做的事情较少,分析下半部的轮询函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| 6699 static int rtl8169_poll(struct napi_struct *napi, int budget)
6700 {
6701 struct rtl8169_private *tp = container_of(napi, struct rtl8169_private, napi);
6702 struct net_device *dev = tp->dev;
6703 u16 enable_mask = RTL_EVENT_NAPI | tp->event_slow;
6704 int work_done;
6705 u16 status;
6706
6707 status = rtl_get_events(tp);
6708 rtl_ack_events(tp, status & ~tp->event_slow);
6709
6710 work_done = rtl_rx(dev, tp, (u32) budget);
6711
6712 rtl_tx(dev, tp);
6713
6714 if (status & tp->event_slow) {
6715 enable_mask &= ~tp->event_slow;
6716
6717 rtl_schedule_task(tp, RTL_FLAG_TASK_SLOW_PENDING);
6718 }
6719
6720 if (work_done < budget) {
6721 napi_complete_done(napi, work_done);
6722
6723 rtl_irq_enable(tp, enable_mask);
6724 mmiowb();
6725 }
6726
6727 return work_done;
6728 }
|
其中tp->event_slow成员的初始化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| 7212 static const struct rtl_cfg_info {
7213 void (*hw_start)(struct rtl8169_private *tp);
7214 u16 event_slow;
7215 unsigned int has_gmii:1;
7216 const struct rtl_coalesce_info *coalesce_info;
7217 u8 default_ver;
7218 } rtl_cfg_infos [] = {
7219 [RTL_CFG_0] = {
7220 .hw_start = rtl_hw_start_8169,
7221 .event_slow = SYSErr | LinkChg | RxOverflow | RxFIFOOver,
7222 .has_gmii = 1,
7223 .coalesce_info = rtl_coalesce_info_8169,
7224 .default_ver = RTL_GIGA_MAC_VER_01,
7225 },
7226 [RTL_CFG_1] = {
7227 .hw_start = rtl_hw_start_8168,
7228 .event_slow = SYSErr | LinkChg | RxOverflow,
7229 .has_gmii = 1,
7230 .coalesce_info = rtl_coalesce_info_8168_8136,
7231 .default_ver = RTL_GIGA_MAC_VER_11,
7232 },
7233 [RTL_CFG_2] = {
7234 .hw_start = rtl_hw_start_8101,
7235 .event_slow = SYSErr | LinkChg | RxOverflow | RxFIFOOver |
7236 PCSTimeout,
7237 .coalesce_info = rtl_coalesce_info_8168_8136,
7238 .default_ver = RTL_GIGA_MAC_VER_13,
7239 }
7240 };
7430 const struct rtl_cfg_info *cfg = rtl_cfg_infos + ent->driver_data;
7632 tp->event_slow = cfg->event_slow;
|
tp->wk.flags成员赋值代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 650 struct rtl8169_private {
687 struct {
688 DECLARE_BITMAP(flags, RTL_FLAG_MAX);
689 struct mutex mutex;
690 struct work_struct work;
691 } wk;
715 };
6852 static int rtl_open(struct net_device *dev)
set_bit(RTL_FLAG_TASK_ENABLED, tp->wk.flags);
6808 static int rtl8169_close(struct net_device *dev)
bitmap_zero(tp->wk.flags, RTL_FLAG_MAX);
4044 static void rtl_schedule_task(struct rtl8169_private *tp, enum rtl_flag flag)
4045 {
4046 if (!test_and_set_bit(flag, tp->wk.flags))
4047 schedule_work(&tp->wk.work);
4048 }
4049
|
接下来分析关键的两个函数:rtl_rx和rtl_tx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| 6523 static int rtl_rx(struct net_device *dev, struct rtl8169_private *tp, u32 budget)
6524 {
6525 unsigned int cur_rx, rx_left;
6526 unsigned int count;
6527
6528 cur_rx = tp->cur_rx;
6529
6530 for (rx_left = min(budget, NUM_RX_DESC); rx_left > 0; rx_left--, cur_rx++) {
6531 unsigned int entry = cur_rx % NUM_RX_DESC;
6532 struct RxDesc *desc = tp->RxDescArray + entry;
6533 u32 status;
6534
6535 status = le32_to_cpu(desc->opts1);
6536 if (status & DescOwn)
6537 break;
6538
6539
6543 dma_rmb();
6564 struct sk_buff *skb;
6565 dma_addr_t addr;
6566 int pkt_size;
6567
6568 process_pkt:
6569 addr = le64_to_cpu(desc->addr);
6570 if (likely(!(dev->features & NETIF_F_RXFCS)))
6571 pkt_size = (status & 0x00003fff) - 4;
6572 else
6573 pkt_size = status & 0x00003fff;
6574
6586 skb = rtl8169_try_rx_copy(tp->Rx_databuff[entry],
6587 tp, pkt_size, addr);
6592
6593 rtl8169_rx_csum(skb, status);
6594 skb_put(skb, pkt_size);
6595 skb->protocol = eth_type_trans(skb, dev);
6596
6597 rtl8169_rx_vlan_tag(desc, skb);
6598
6599 if (skb->pkt_type == PACKET_MULTICAST)
6600 dev->stats.multicast++;
6601
6602 napi_gro_receive(&tp->napi, skb);
6603
6604 u64_stats_update_begin(&tp->rx_stats.syncp);
6605 tp->rx_stats.packets++;
6606 tp->rx_stats.bytes += pkt_size;
6607 u64_stats_update_end(&tp->rx_stats.syncp);
6608 }
6609 release_descriptor:
6610 desc->opts2 = 0;
6611 rtl8169_mark_to_asic(desc);
6612 }
6613
6614 count = cur_rx - tp->cur_rx;
6615 tp->cur_rx = cur_rx;
6616
6617 return count;
6618 }
6504 static struct sk_buff *rtl8169_try_rx_copy(void *data,
6505 struct rtl8169_private *tp,
6506 int pkt_size,
6507 dma_addr_t addr)
6508 {
6509 struct sk_buff *skb;
6510 struct device *d = tp_to_dev(tp);
6511
6512 data = rtl8169_align(data);
6513 dma_sync_single_for_cpu(d, addr, pkt_size, DMA_FROM_DEVICE);
6514 prefetch(data);
6515 skb = napi_alloc_skb(&tp->napi, pkt_size);
6516 if (skb)
6517 skb_copy_to_linear_data(skb, data, pkt_size);
6518 dma_sync_single_for_device(d, addr, pkt_size, DMA_FROM_DEVICE);
6519
6520 return skb;
6521 }
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| 6426 static void rtl_tx(struct net_device *dev, struct rtl8169_private *tp)
6427 {
6428 unsigned int dirty_tx, tx_left;
6429
6430 dirty_tx = tp->dirty_tx;
6431 smp_rmb();
6432 tx_left = tp->cur_tx - dirty_tx;
6433
6434 while (tx_left > 0) {
6435 unsigned int entry = dirty_tx % NUM_TX_DESC;
6436 struct ring_info *tx_skb = tp->tx_skb + entry;
6437 u32 status;
6438
6439 status = le32_to_cpu(tp->TxDescArray[entry].opts1);
6440 if (status & DescOwn)
6441 break;
6442
6443
6447 dma_rmb();
6448
6449 rtl8169_unmap_tx_skb(tp_to_dev(tp), tx_skb,
6450 tp->TxDescArray + entry);
6451 if (status & LastFrag) {
6452 u64_stats_update_begin(&tp->tx_stats.syncp);
6453 tp->tx_stats.packets++;
6454 tp->tx_stats.bytes += tx_skb->skb->len;
6455 u64_stats_update_end(&tp->tx_stats.syncp);
6456 dev_consume_skb_any(tx_skb->skb);
6457 tx_skb->skb = NULL;
6458 }
6459 dirty_tx++;
6460 tx_left--;
6461 }
6462
6463 if (tp->dirty_tx != dirty_tx) {
6464 tp->dirty_tx = dirty_tx;
6465
6472 smp_mb();
6473 if (netif_queue_stopped(dev) &&
6474 TX_FRAGS_READY_FOR(tp, MAX_SKB_FRAGS)) {
6475 netif_wake_queue(dev);
6476 }
6477
6483 if (tp->cur_tx != dirty_tx)
6484 RTL_W8(tp, TxPoll, NPQ);
6485 }
6486 }
5988 static void rtl8169_unmap_tx_skb(struct device *d, struct ring_info *tx_skb,
5989 struct TxDesc *desc)
5990 {
5991 unsigned int len = tx_skb->len;
5992
5993 dma_unmap_single(d, le64_to_cpu(desc->addr), len, DMA_TO_DEVICE);
5994
5995 desc->opts1 = 0x00;
5996 desc->opts2 = 0x00;
5997 desc->addr = 0x00;
5998 tx_skb->len = 0;
5999 }
3527 static inline void dev_consume_skb_any(struct sk_buff *skb)
3528 {
3529 __dev_kfree_skb_any(skb, SKB_REASON_CONSUMED);
3530 }
|
描述符更改
主要关注描述符中DescOwn位的变更,1代表描述符为网卡所拥有,0表示描述符为驱动所拥有
发送描述符
结构体定义
1
2
3
4
5
| 596 struct TxDesc {
597 __le32 opts1;
598 __le32 opts2;
599 __le64 addr;
600 };
|
初始化
没看见清零的代码,不知道dma_alloc_coherent默认分配的内存是否清零,但按照rtl8169_unmap_tx_skb的代码,初始状态应该为全0
发包
网卡驱动进行发包操作,填充发送描述符, 此时将DescOwn位置位,将所有权转移至网卡
1
2
3
4
5
|
struct TxDesc *txd = tp->TxDescArray + entry;
txd->addr = cpu_to_le64(mapping);
txd->opts2 = cpu_to_le32(opts[1]);
txd->opts1 = cpu_to_le32(status);
|
网卡
当网卡成功发送相应数据包后,DMA修改发送描述符,将DescOwn位清零,将所有权转移至驱动
发包成功
相应数据包已发送,重置描述符,此时发送描述符的DescOwn位为0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
5988 static void rtl8169_unmap_tx_skb(struct device *d, struct ring_info *tx_skb,
5989 struct TxDesc *desc)
5990 {
5991 unsigned int len = tx_skb->len;
5992
5993 dma_unmap_single(d, le64_to_cpu(desc->addr), len, DMA_TO_DEVICE);
5994
5995 desc->opts1 = 0x00;
5996 desc->opts2 = 0x00;
5997 desc->addr = 0x00;
5998 tx_skb->len = 0;
5999 }
6000
|
接收描述符
结构体定义
1
2
3
4
5
| 602 struct RxDesc {
603 __le32 opts1;
604 __le32 opts2;
605 __le64 addr;
606 };
|
初始化
将DescOwn置位,表示网卡拥有该描述符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
desc->addr = cpu_to_le64(mapping);
5887 static inline void rtl8169_mark_to_asic(struct RxDesc *desc)
5888 {
5889 u32 eor = le32_to_cpu(desc->opts1) & RingEnd;
5890
5891
5892 dma_wmb();
5893
5894 desc->opts1 = cpu_to_le32(DescOwn | eor | R8169_RX_BUF_SIZE);
5895 }
rtl8169_mark_as_last_descriptor(tp->RxDescArray + NUM_RX_DESC - 1);
5950 static inline void rtl8169_mark_as_last_descriptor(struct RxDesc *desc)
5951 {
5952 desc->opts1 |= cpu_to_le32(RingEnd);
5953 }
|
网卡
网卡接收到数据包,DMA修改接收描述符,将DescOwn清零,将所有权转移至驱动
收包
处理数据包完成网卡驱动重置接收描述符,继续将DescOwn置位,所有权移交网卡
1
2
3
4
|
6609 release_descriptor:
6610 desc->opts2 = 0;
6611 rtl8169_mark_to_asic(desc);
|
参考博客
网卡驱动的收发包流程 推荐
轻松记住大端小端的含义(附对大端和小端的解释)
一致性DMA映射与流式DMA映射
dma_addr_t与流式映射和一致性映射
linux驱动 关于资源resource
Linux内核中sk_buff结构详解
Linux 网络子系统
关于网卡特性TSO、UFO、GSO、LRO、GRO
数据包接收系列 — NAPI的原理和实现
napi
Linux网络协议栈:NAPI机制与处理流程分析(图解)