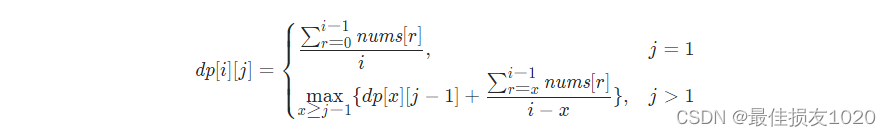推荐博客五大常用算法:分治、动态规划、贪心、回溯和分支界定
代码复制粘贴太多了,编辑起来很卡,再开一个博客:leetcode记录2
合并 K 个升序链表 给你一个链表数组,每个链表都已经按升序排列。
思路:简单的合并链表,刚开始的思路是每次循环找到最小的节点,后面看题解发现可以使用优先队列这种方式辅助找到最小值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {bool IterToEnd (vector <ListNode*>& lists) { for (auto & link_list : lists) {if (link_list != nullptr) {return false ;return true ;mergeKLists (vector <ListNode*>& lists) {while (!IterToEnd(lists)) {int min_val = 1UL << 30 ;int min_index = -1 ;for (int i = 0 ; i < lists.size(); i++) {if (lists[i] != nullptr) {if (min_val > lists[i]->val) {return virt_node.next;
使用优先队列找到最小值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {mergeKLists (vector <ListNode*>& lists) {priority_queue <pair <int , int >, vector <pair <int , int >>, greater<pair <int , int >>> node_queue;for (int i = 0 ; i < lists.size(); i++) {if (lists[i] != nullptr) {while (!node_queue.empty()) {auto [_, min_index] = node_queue.top();if (lists[min_index] != nullptr) { return virt_node.next;
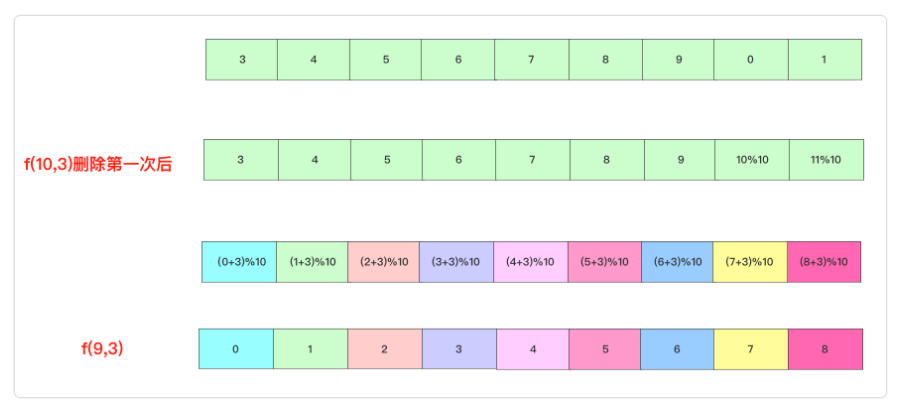
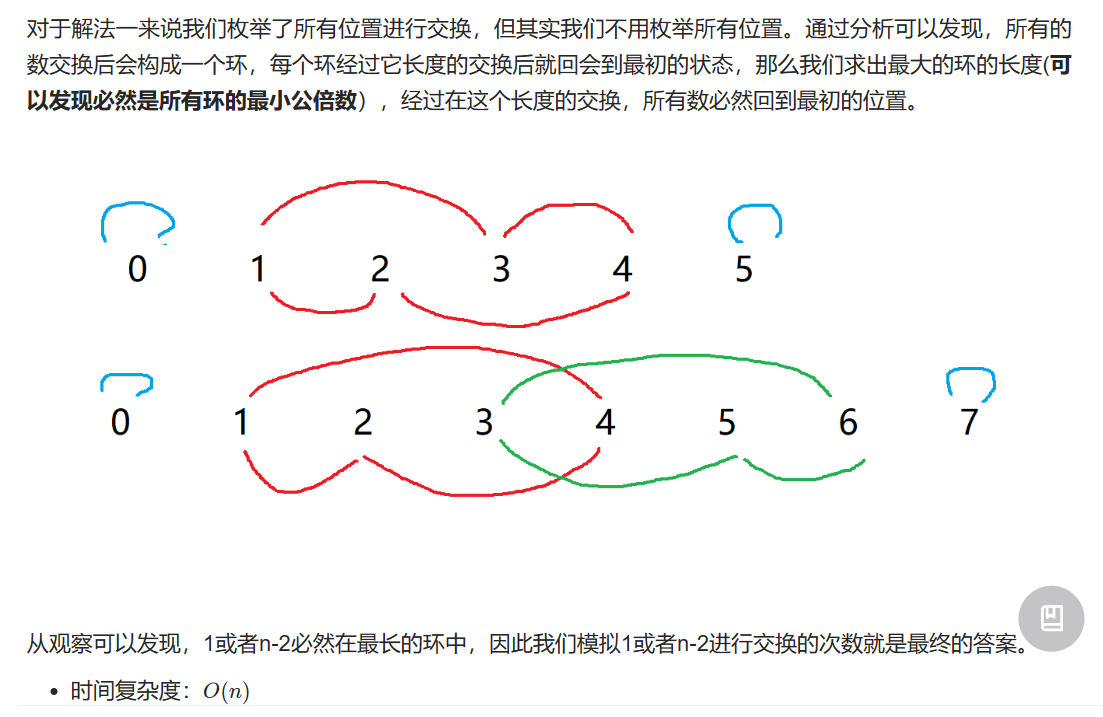
圆圈中最后剩下的数字 0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
记住约瑟夫环的递推公式即可
1 2 3 4 5 6 7 8 9 10 11 class Solution {public :int lastRemaining (int n, int m) int value = 0 ;for (int i = 2 ; i <= n; i++) {return value;
字符串相加 给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
按我之前的写法,我的代码会像这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 string add (string a, string b, int radix) {reverse (a.begin (), a.end ());reverse (b.begin (), b.end ());int len_a = a.length ();int len_b = b.length ();string ((50 - len_a), '0' );string ((50 - len_b), '0' );int flag = 0 ;for (int i = 0 ; i < 50 ; i++) {int sum = a[i] + b[i] - '0' - '0' + flag;0 ;if (sum >= radix) {1 ;'0' ;int len = len_a > len_b ? len_a : len_b;while (a[len] != '0' ) {substr (0 , len);reverse (ans.begin (), ans.end ());return ans;
看了字符串相乘的代码后,我写出来这样的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public :string addStrings (string num1, string num2) {int len1 = num1.size ();int len2 = num2.size ();if (len1 < len2) { swap (num1, num2);swap (len1, len2); vector<int > ans (len1 + 1 , 0 ) ; for (int i = 0 ; i < len2; i++) {1 ] + num2[len2 - i - 1 ] - 2 * '0' ;for (int i = len2; i < len1; i++) {1 ] - '0' ;for (int i = len1; i > 0 ; i--) {1 ] += ans[i] / 10 ; 10 ;int start = (ans[0 ] == 0 ) ? 1 : 0 ;for (int i = start; i <= len1; i++) {push_back (ans[i] + '0' );return ans_str;
而官方的题解仍然是最简洁的,一个循环解决问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public :string addStrings (string num1, string num2) {int i = num1.length () - 1 ;int j = num2.length () - 1 ;int carry = 0 ;while ((i >= 0 ) || (j >= 0 ) || (carry > 0 )) {int x = (i >= 0 ) ? num1[i] - '0' : 0 ;int y = (j >= 0 ) ? num2[j] - '0' : 0 ;int sum = x + y + carry;push_back (sum % 10 + '0' );10 ;reverse (ans.begin (), ans.end ());return ans;
相交链表 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
直接借助set实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public :ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) {while (headA != nullptr ) {emplace (headA);while (headB != nullptr ) {if (se.count (headB) > 0 ) {return headB;return nullptr ;
然后便是官方题解的巧妙解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public :ListNode *getIntersectionNode (ListNode *headA, ListNode *headB) {if (headA == nullptr || headB == nullptr ) {return nullptr ;while (pA != pB) {nullptr ) ? headB : pA->next;nullptr ) ? headA : pB->next;return pA;
环形链表与Floyd判圈算法 141.环形链表
142.环形链表 II
首先,使用最简单的思路,借助set实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public :bool hasCycle (ListNode* head) while (cur != nullptr ) {if (se.count (cur) > 0 ) {return true ;emplace (cur);return false ;class Solution {public :ListNode* detectCycle (ListNode* head) {while (cur != nullptr ) {if (se.count (cur) > 0 ) {return cur;emplace (cur);return nullptr ;
利用Floyd算法,使用快慢指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public :bool hasCycle (ListNode* head) if (head == nullptr || head->next == nullptr ) {return false ;do { if (fast == nullptr || fast->next == nullptr ) { return false ;while (slow != fast);return true ;class Solution {public :ListNode* detectCycle (ListNode* head) {if (head == nullptr || head->next == nullptr ) {return false ;do {if (fast == nullptr || fast->next == nullptr ) {return nullptr ;while (slow != fast);while (cur != slow) {return cur;
反转链表 II 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
分类讨论,是否从最开始进行反转
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {public :ListNode* reverseBetween (ListNode* head, int left, int right) {if (head->next == nullptr ) { return head;if (left == 1 ) { nullptr ;else {for (int i = 1 ; i < left - 1 ; i++) {for (int i = left; i < right; i++) {if (left_node_prev != nullptr ) { return head;return prev;
使用虚拟头结点,合并两种情况,统一处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :ListNode* reverseBetween (ListNode* head, int left, int right) {if (head->next == nullptr ) { return head;ListNode virt_head (-1 , head) ; for (int i = 1 ; i < left; i++) {for (int i = left; i < right; i++) {return virt_head.next;
搜索旋转排序数组 整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
对题目有些误解,并不是一定旋转,将数组分为左半部右半部,若在不同分部,则一定向该方向前进,其他情况照常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Solution {public :int search (vector<int >& nums, int target) if (nums.size () == 1 ) {return nums[0 ] == target ? 0 : -1 ;int left_min = nums[0 ];int right_max = nums[nums.size () - 1 ];if (right_max < left_min) { bool in_left = target >= left_min; bool in_right = target <= right_max; if (!in_left && !in_right) {return -1 ;int high = nums.size () - 1 ;int low = 0 ;while (low <= high) {int mid = (low + high) / 2 ;if (nums[mid] == target) { return mid;else if (in_left && nums[mid] <= right_max) { 1 ;else if (in_right && nums[mid] >= left_min) { 1 ;else if (nums[mid] > target) { 1 ;else if (nums[mid] < target) { 1 ;else { int high = nums.size () - 1 ;int low = 0 ;while (low <= high) {int mid = (low + high) / 2 ;if (nums[mid] == target) { return mid;else if (nums[mid] > target) { 1 ;else if (nums[mid] < target) { 1 ;return -1 ;
使用官方题解的方法,将数组分为有序部分与无序部分,利用有序部分特性与排除法锁定target所在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public :int search (vector<int >& nums, int target) int low = 0 ;int high = nums.size () - 1 ;while (low < high) {int mid = (low + high) / 2 ;if (nums[mid] == target) { return mid;if (nums[low] <= nums[mid]) { if (nums[low] <= target && target < nums[mid]) { 1 ;else {1 ;else { if (nums[mid] < target && target <= nums[high]) { 1 ;else {1 ;return nums[low] == target ? low : -1 ;
格雷编码 n 位格雷码序列 是一个由 2n 个整数组成的序列,其中:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public :vector<int > grayCode (int n) {int > ans;emplace_back (0 );for (int i = 1 ; i <= n; i++) {for (int j = ans.size () - 1 ; j >= 0 ; j--) { emplace_back (ans[j] | (1 << (i - 1 )));return ans;
字符串相乘 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
我的解法是利用字符串相加+字符串乘整数实现字符串乘法,非常繁杂的算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution {public :void add (string& num1, const string& num2) int carry = 0 ;int i;for (i = 0 ; i < num2.size (); i++) {int sum = num1[i] + num2[i] - 2 * '0' + carry;10 + '0' ;10 ;while (carry != 0 ) {int sum = num1[i] - '0' + carry;10 + '0' ;10 ;string simpleMulti (string num1, int x) { int carry = 0 ;for (int i = 0 ; i < num1.size (); i++) {int sum = (num1[i] - '0' ) * x + carry;10 + '0' ;10 ;return num1;string multiply (string num1, string num2) { if (num1 == "0" || num2 == "0" ) { return "0" ;string ans (num1.size() + num2.size() + 3 , '0' ) ; reverse (num1.begin (), num1.end ()); push_back ('0' ); for (int i = 0 ; i < num2.size (); i++) {simpleMulti (num1, num2[i] - '0' ); string prefix (num2.size() - 1 - i, '0' ) ; add (ans, prefix + local_multi); int end = ans.length () - 1 ; while (ans[end] == '0' ) {reverse (ans.begin (), ans.begin () + end + 1 ); return ans.substr (0 , end + 1 );
官方题解使用vector从右往左向乘,结果位数要么为m+n-1,m+n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :string multiply (string num1, string num2) {if (num1 == "0" || num2 == "0" ) {return "0" ;int len1 = num1.length ();int len2 = num2.length ();vector<int > ans_arr (len1 + len2) ; for (int i = len1 - 1 ; i >= 0 ; i--) {for (int j = len2 - 1 ; j >= 0 ; j--) {1 ] += (num1[i] - '0' ) * (num2[j] - '0' );for (int i = len1 + len2 - 1 ; i > 0 ; i--) {1 ] += ans_arr[i] / 10 ; 10 ;int start = (ans_arr[0 ] == 0 ) ? 1 : 0 ;for (int i = start; i < len1 + len2; i++) {push_back (ans_arr[i] + '0' );return ans;
删除有序数组中的重复项 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
我使用的方法是先遍历一遍,标记无效数字,然后再次遍历,将前面的无效数与后面的有效数交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 const int kInvaild = 1 << 20 ;class Solution {public :int removeDuplicates (vector<int >& nums) int last_number = nums[0 ];int invaild_count = 0 ;for (int i = 1 ; i < nums.size (); i++) {if (nums[i] == last_number) { else {if (invaild_count == 0 ) { return nums.size ();int new_len = nums.size () - invaild_count;int start = 0 ;int end = 0 ;while (start < new_len) { while (nums[start] != kInvaild) { if (start == new_len) { break ;while (nums[end] == kInvaild) { swap (nums[start], nums[end]); return new_len;
而官方题解使用快慢指针的方法解决,非常简洁的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public :int removeDuplicates (vector<int >& nums) int fast = 1 ;int slow = 1 ;for (fast = 1 ; fast < nums.size (); fast++) {if (nums[fast] != nums[fast - 1 ]) { return slow;
字符串的排列 输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
一:最简单的方法 dfs+set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public :void dfs (set<string>& result, string& s, int start, int end) if (start == end) {emplace (s);return ;for (int i = start; i < end; i++) {swap (s[i], s[start]);dfs (result, s, start + 1 , end);swap (s[i], s[start]);vector<string> permutation (string s) {dfs (ans, s, 0 , s.length ());return vector <string>(ans.begin (), ans.end ());
二: 有条件的dfs,我自己实现的代码只保证了没有与start重复,要保证该位置没有任何重复字符需利用set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :void dfs (vector<string>& result, string& s, int start, int end) if (start == end) {emplace_back (s);return ;char > se;for (int i = start; i < end; i++) {if (se.count (s[i]) != 0 ) { continue ;emplace (s[i]);swap (s[i], s[start]);dfs (result, s, start + 1 , end);swap (s[i], s[start]);vector<string> permutation (string s) {dfs (ans, s, 0 , s.length ());return ans;
三:巧妙利用下一个排列算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :bool next (string& s) int i;for (i = s.length () - 2 ; i >= 0 ; i--) { if (s[i] < s[i + 1 ]) {break ;if (i < 0 ) {return false ;for (int j = s.length () - 1 ; j >= 0 ; j--) { if (s[j] > s[i]) {swap (s[i], s[j]); break ;reverse (s.begin () + i + 1 , s.end ()); return true ;vector<string> permutation (string s) {sort (s.begin (), s.end ()); do {emplace_back (s);while (next (s));return ans;
用两个栈实现队列 用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
简单题,但我的实现非常慢,因为我解决deleteHead的方法就是立即转移所有数据至另一个栈,没有想到部分数据迁移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class CQueue {public :CQueue () : in_normal_{true } {}void appendTail (int value) if (!in_normal_) { while (!reverse_.empty ()) {emplace (reverse_.top ());pop ();true ;emplace (value);int deleteHead () if (in_normal_) { while (!normal_.empty ()) {emplace (normal_.top ());pop ();false ;if (reverse_.empty ()) {return -1 ;int ans = reverse_.top ();pop ();return ans;private :int > normal_; int > reverse_; bool in_normal_;
官方题解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class CQueue {public :CQueue () {}void appendTail (int value) emplace (value); }int deleteHead () if (out_stack_.empty ()) { if (in_stack_.empty ()) {return -1 ;while (!in_stack_.empty ()) {emplace (in_stack_.top ());pop ();int ans = out_stack_.top (); pop ();return ans;private :int > in_stack_; int > out_stack_;
不同的二叉搜索树 II 给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。
刚开始的时候我一直返回{},而不是{nullptr},有时候将空指针视作一个节点便于理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public :vector<TreeNode *> generate (int start, int end) {if (start > end) {return {nullptr }; if (start == end) {return {new TreeNode (start)};for (int i = start; i <= end; i++) {auto left = generate (start, i - 1 );auto right = generate (i + 1 , end);for (auto left_node : left) {for (auto right_node : right) {new TreeNode (i);emplace_back (root);return ans;vector<TreeNode *> generateTrees (int n) { return generate (1 , n); }
和至少为 K 的最短子数组 给你一个整数数组 nums 和一个整数 k ,找出 nums 中和至少为 k 的 最短非空子数组 ,并返回该子数组的长度。如果不存在这样的 子数组 ,返回 -1 。
子数组 是数组中 连续 的一部分。
我的方法是简单的dp+枚举,但一直超出时间限制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public :int shortestSubarray (vector<int > &nums, int k) vector<int > dp (nums.size()) ; 0 ] = nums[0 ];for (int i = 1 ; i < nums.size (); i++) {max (0 , dp[i - 1 ]); int min_len = nums.size () + 1 ;for (int i = 0 ; i < nums.size (); i++) {if (nums[i] < 0 ) { continue ;if (dp[i] >= k) {int sum = 0 ;int j = i;while (sum < k) { min (min_len, i - j); return min_len <= nums.size () ? min_len : -1 ;
而官方题解采用的是前缀和加双端递增序列的方式两张图秒懂单调队列(Python/Java/C++/Go)
由于优化二保证了数据结构中的 s[i] 会形成一个递增的序列,因此优化一移除的是序列最左侧的若干元素,优化二移除的是序列最右侧的若干元素。我们需要一个数据结构,它支持移除最左端的元素和最右端的元素,以及在最右端添加元素,故选用双端队列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public :int shortestSubarray (vector<int > &nums, int k) vector<long long > prefix (nums.size() + 1 ) ; 0 ] = 0 ;for (int i = 1 ; i <= nums.size (); i++) {1 ] + nums[i - 1 ];int min_len = nums.size () + 1 ;int > q; emplace_front (0 );for (int i = 1 ; i <= nums.size (); i++) {while (!q.empty () && (prefix[i] - prefix[q.front ()] >= k)) { min (min_len, i - q.front ());pop_front ();while (!q.empty () && prefix[i] <= prefix[q.back ()]) { pop_back ();emplace_back (i);return min_len <= nums.size () ? min_len : -1 ;
下一个更大元素 III 给你一个正整数 n ,请你找出符合条件的最小整数,其由重新排列 n 中存在的每位数字组成,并且其值大于 n 。如果不存在这样的正整数,则返回 -1 。
注意 ,返回的整数应当是一个 32 位整数 ,如果存在满足题意的答案,但不是 32 位整数 ,同样返回 -1 。
下一个排列算法的应用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public :int nextGreaterElement (int n) if (n < 10 ) { return -1 ;int > nums;while (n != 0 ) {emplace_back (n % 10 );10 ;reverse (nums.begin (), nums.end ());int i = 0 ;for (i = nums.size () - 2 ; i >= 0 ; i--) {if (nums[i] < nums[i + 1 ]) {break ;if (i < 0 ) { return -1 ;for (int j = nums.size () - 1 ; j >= 0 ; j--) {if (nums[j] > nums[i]) {swap (nums[i], nums[j]);break ;reverse (nums.begin () + i + 1 , nums.end ());long long ans = 0 ;for (int num : nums) {10 + num;return ans > INT_MAX ? -1 : ans;
二:借助string拆解数字n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :int nextGreaterElement (int n) if (n < 10 ) { return -1 ;auto nums = to_string (n);int i = 0 ;for (i = nums.size () - 2 ; i >= 0 ; i--) {if (nums[i] < nums[i + 1 ]) {break ;if (i < 0 ) { return -1 ;for (int j = nums.size () - 1 ; j >= 0 ; j--) {if (nums[j] > nums[i]) {swap (nums[i], nums[j]);break ;reverse (nums.begin () + i + 1 , nums.end ());long long ans = stol (nums);return ans > INT_MAX ? -1 : ans;
下一个排列 整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
例如,arr = [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。
例如,arr = [1,2,3] 的下一个排列是 [1,3,2] 。
必须 原地 修改,只允许使用额外常数空间。相关算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public :void nextPermutation (vector<int >& nums) int i = 0 , j = 0 ;for (i = nums.size () - 2 ; i >= 0 ; i--) { if (nums[i] < nums[i + 1 ]) {break ;if (i >= 0 ) {for (j = nums.size () - 1 ; j > i; j--) { if (nums[j] > nums[i]) {break ;swap (nums[i], nums[j]); reverse (nums.begin () + i + 1 , nums.end ());
分割回文串 II 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
同样是之前没写出来的题目,同样现在也没想出来,动态规划总是看之前啥也想不出来,看之后恍然大悟,代码几行写完。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public :int minCut (string s) int n = s.length ();bool >> g (n, vector <bool >(n, true )); for (int i = n - 2 ; i >= 0 ; i--) {for (int j = i + 1 ; j < n; j++) {1 ][j - 1 ] && (s[i] == s[j]);vector<int > f (n, n) ; for (int i = 0 ; i < n; i++) {if (g[0 ][i]) { 0 ;else {for (int j = 0 ; j < i; j++) {if (g[j + 1 ][i]) { min (f[i], f[j] + 1 );return f[n - 1 ];
我发现动态规划的解要不然就是聚合所有子问题的解(f[0…i-1]),要么就是聚合满足特定条件子问题的解(s[j+1…i]为回文字符串,f[i] = min(f[i], f[j] + 1))
两数相除 给你两个整数,被除数 dividend 和除数 divisor。将两数相除,要求 不使用 乘法、除法和取余运算。
整数除法应该向零截断,也就是截去(truncate)其小数部分。例如,8.345 将被截断为 8 ,-2.7335 将被截断至 -2 。
返回被除数 dividend 除以除数 divisor 得到的 商 。
注意:假设我们的环境只能存储 32 位 有符号整数,其数值范围是 [−231, 231 − 1] 。本题中,如果商 严格大于 231 − 1 ,则返回 231 − 1 ;如果商 严格小于 -231 ,则返回 -231 。
同样是2019年没写出来的题目,现在同样也没写出来。官方题解使用快速乘+二分查找解决函数实现时最好首先把特殊情况排除 ,然后再实现通用功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class Solution {public :bool check (int x, int y, int z) int cum = 0 ; int add = y; while (z) {if (z & 1 ) {if (cum < x - add) {return false ;if (z != 1 ) {if (add < x - add) {return false ;1 ;return true ;int divide (int dividend, int divisor) if (dividend == INT_MIN && divisor == 1 ) {return INT_MIN;if (dividend == INT_MIN && divisor == -1 ) {return INT_MAX;if (divisor == INT_MIN) {return dividend == INT_MIN ? 1 : 0 ;if (dividend == 0 ) {return 0 ;bool rev = false ; if (dividend > 0 ) {if (divisor > 0 ) {int left = 1 ;int right = INT_MAX;int ans = 0 ;while (left <= right) {int mid = left + ((right - left) >> 1 );bool ret = check (dividend, divisor, mid); if (ret) {if (mid == INT_MAX) {break ;1 ; else {1 ; return rev ? -ans : ans;
K 站中转内最便宜的航班 有 n 个城市通过一些航班连接。给你一个数组 flights ,其中 flights[i] = [fromi, toi, pricei] ,表示该航班都从城市 fromi 开始,以价格 pricei 抵达 toi。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到出一条最多经过 k 站中转的路线,使得从 src 到 dst 的 价格最便宜 ,并返回该价格。 如果不存在这样的路线,则输出 -1。
这个题我2019年一直没做出来,我隐隐约约觉得是用BFS什么的做的,可我写了半天,越写越复杂,我就知道这一次我又做不出来了。看了看题解,动态规划,几行代码搞定,蚌!
当代码越来越复杂的时候,就可以想想是不是思路不正确了,而且这个时候大概率要用动态规划了。当题目中这种最多经过K个这种条件出现时,如果很容易放入最短路径的放缩条件,则照常使用最短路径算法,否则将其依次拆分为恰好为[0-k]时到达dst的路径长度,最终结果取其最值,很多的状态转移方程都是这种拆分+最值的思想。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public :const int kMaxLen = (1 << 30 );int findCheapestPrice (int n, vector<vector<int >>& flights, int src, int dst, int k) int >> f (2 , vector <int >(n, kMaxLen));int pre = 0 ;int cur = 1 ;0 ][src] = 0 ;1 ][src] = 1 ;int ans = kMaxLen;for (int t = 1 ; t <= k + 1 ; t++) {for (auto & flight : flights) { 1 ]] = min (f[cur][flight[1 ]], f[pre][flight[0 ]] + flight[2 ]); min (ans, f[cur][dst]);1 ) % 2 ;1 ) % 2 ;return ans == kMaxLen ? -1 : ans;
定义无穷值时最好不要定义为INT_MAX,这样就无法进行相加操作
N 字形变换 将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
1 2 3 P A H N
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:”PAHNAPLSIIGYIR”。
我的解法就是简单的分成两端,向下的序列和向上的序列,而后用两个for循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public :string convert (string s, int numRows) {int index = 0 ;vector<string> zigstr (numRows, "" ) ;while (index < s.length ()) {for (int i = 0 ; i < numRows && index < s.length (); i++) { push_back (s[index]);for (int i = numRows - 2 ; i > 0 && index < s.length (); i--) { push_back (s[index]);"" ;for (string& str : zigstr) {append (str);return ans;
官方则简洁一点,将两个for循环合并在一起,且以index为下标递增,注意numRows = 1的特殊情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public :string convert (string s, int numRows) {if (numRows == 1 || numRows >= s.length ()) { return s;vector<string> zigstr (numRows, "" ) ;int row = 0 ;int period = 2 * numRows - 2 ;for (int i = 0 ; i < s.length (); i++) {push_back (s[i]);if (i % period < numRows - 1 ) {else {"" ;for (string& str : zigstr) {append (str);return ans;
无重复字符的最长子串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
刚开始我想的方法也是官方题解一样的使用set然后加入删除,但觉得这有点费劲,而且是字符,最大才255,就使用数组来存储,并分别记录每个位置的前一个相同字符位置和后一个相同字符,这样就能快速移动左右指针。右指针移动失败一定因为遇到相同字符或字符串末尾,而左指针可以直接跳转至该失败位置的前一个相同字符位置后+1 ,因为在其前面的位置都会在右指针位置失败,而长度均小于该次长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public :int lengthOfLongestSubstring (string s) vector<int > last_occur_index (256 , -1 ) ; vector<int > next_same_index (s.length(), s.length()) ; vector<int > pre_same_index (s.length(), s.length()) ; for (int i = 0 ; i < s.length (); i++) {if (last_occur_index[s[i]] != -1 ) {int start = 0 ;int max_substr_len = 0 ;while (start < s.length ()) {int possible_bound = s.length ();int end = start;while (end < possible_bound) { min (possible_bound, next_same_index[end]); max (max_substr_len, end - start);if (end >= s.length ()) {return max_substr_len;1 ;return max_substr_len;
最接近的三数之和 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。
返回这三个数的和。
假定每组输入只存在恰好一个解。
我的思路比较简单,把一个数固定,解决最接近的两数之和,但在枚举时我采用的方法是将固定数置为无效,两数之和函数中还需对无效坐标进行特殊处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Solution {public :int twoSumClosest (const vector<int >& nums, int invaild_index, int target) int i = 0 ;int j = nums.size () - 1 ;int closest_sum = 0 ;int min_abs = INT32_MAX;while (i < j) {if (i == invaild_index) {else if (j == invaild_index) {if (i >= j) { return closest_sum;int sum = nums[i] + nums[j];int abs_val = abs (sum - target);if (abs_val < min_abs) {if (sum > target) {else if (sum < target) {else {return target;return closest_sum;int threeSumClosest (vector<int >& nums, int target) sort (nums.begin (), nums.end ());int three_closest_sum = 0 ;int min_abs = INT32_MAX;for (int i = 0 ; i < nums.size (); i++) {int two_closest_sum = twoSumClosest (nums, i, target - nums[i]);int abs_val = abs (two_closest_sum + nums[i] - target);if (abs_val < min_abs) {return three_closest_sum;
而官方题解比我的代码改进的点就在于每次只需枚举固定数后面的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {public :int twoSumClosest (const vector<int >& nums, int start_index, int target) int i = start_index;int j = nums.size () - 1 ;int closest_sum = 0 ;int min_abs = INT32_MAX;while (i < j) {int sum = nums[i] + nums[j];int abs_val = abs (sum - target);if (abs_val < min_abs) {if (sum > target) {else if (sum < target) {else {return target;return closest_sum;int threeSumClosest (vector<int >& nums, int target) sort (nums.begin (), nums.end ());int three_closest_sum = 0 ;int min_abs = INT32_MAX;for (int i = 0 ; i < nums.size () - 2 ; i++) {int two_closest_sum = twoSumClosest (nums, i + 1 , target - nums[i]); int abs_val = abs (two_closest_sum + nums[i] - target);if (abs_val < min_abs) {return three_closest_sum;
合并两个有序数组 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
我的解法,经典的双指针合并,用了额外空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :void merge (vector<int >& nums1, int m, vector<int >& nums2, int n) vector<int > nums1_copy (nums1.begin(), nums1.begin() + m) ;int i = 0 ;int j = 0 ;int k = 0 ;while (i < m && j < n) {if (nums1_copy[i] < nums2[j]) {else {while (i < m) {while (j < n) {
官方题解,同样使用双指针,但是逆向遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public :void merge (vector<int >& nums1, int m, vector<int >& nums2, int n) int i = m - 1 ;int j = n - 1 ;int k = m + n - 1 ;while (i >= 0 && j >= 0 ) {if (nums1[i] > nums2[j]) {else {while (i >= 0 ) {while (j >= 0 ) {
二叉树的最大深度 给定一个二叉树,找出其最大深度。
我的解法,朴素的dfs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public :void dfs (TreeNode *node, int level, int *max_level) if (node->left == nullptr && node->right == nullptr ) {max (*max_level, level);return ;if (node->left != nullptr ) {dfs (node->left, level + 1 , max_level);if (node->right != nullptr ) {dfs (node->right, level + 1 , max_level);int maxDepth (TreeNode *root) if (root == nullptr ) {return 0 ;int ans = 0 ;dfs (root, 1 , &ans);return ans;
简洁的官方题解,两行实现
1 2 3 4 5 6 7 class Solution {public :int maxDepth (TreeNode *root) if (root == nullptr ) return 0 ;return max (maxDepth (root->left), maxDepth (root->right)) + 1 ;
连续子数组的最大和 输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
看到是简单题,就没想啥高深的方法,遍历一遍数组,维护局部最大连续和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :int maxSubArray (vector<int >& nums) int max_val = nums[0 ];int sum = 0 ; bool vaild = false ; for (int num : nums) {if (num < 0 ) { if (vaild) {max (max_val, sum);else {max (max_val, num);true ;if (sum < 0 ) { 0 ;false ;if (vaild) { max (max_val, sum);return max_val;
没想到官方题解竟然用到了动态规划的思想,虽然代码非常简单
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public :int maxSubArray (vector<int >& nums) int max_val = nums[0 ];int pre = 0 ;for (int num : nums) {max (pre + num, num);max (max_val, pre);return max_val;
二叉树中的最长交错路径 给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下:
选择二叉树中 任意 节点和一个方向(左或者右)。
交错路径的长度定义为:访问过的节点数目 - 1(单个节点的路径长度为 0 )。
没写出来,没理解题意,交错路径的末尾不一定是叶子节点,自己写的dfs超时了,抄的官方题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {public :void dfs (TreeNode *node, int dir, int len) max (max_len_, len); if (dir == 0 ) {if (node->left != nullptr ) { dfs (node->left, 1 , len + 1 );if (node->right != nullptr ) { dfs (node->right, 0 , 1 );if (dir == 1 ) {if (node->left != nullptr ) { dfs (node->left, 1 , 1 );if (node->right != nullptr ) { dfs (node->right, 0 , len + 1 );int longestZigZag (TreeNode *root) if (root == nullptr ) {return 0 ;0 ;dfs (root, 0 , 0 );dfs (root, 1 , 0 );return max_len_;private :int max_len_;
验证二叉树的前序序列化 序列化二叉树的一种方法是使用 前序遍历 。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
利用前序遍历的特点,叶子节点的两个空节点一定紧紧挨着该叶子节点,所以可以将x # #格式的数据等价为#,即该叶子节点为空的序列,逆序遍历序列并一直利用这种方法消除节点,最终合法的前序遍历序列会归约到一个空节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public :bool isValidSerialization (string preorder) int empty_node_cnt = 0 ; for (int i = preorder.length () - 1 ; i >= 0 ; i--) {if (preorder[i] == '#' ) {else if (preorder[i] != ',' ) {if (empty_node_cnt < 2 ) { return false ;while (i >= 0 && preorder[i] != ',' ) { return empty_node_cnt == 1 ;
两句话中的不常见单词 句子 是一串由空格分隔的单词。每个 单词 仅由小写字母组成。
简单题,明显是分割字符串后加入哈希表,我采用的方法是使用find substr分割出单词,而官方题解利用stringstream 来分割句子中的单词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public :vector<string> uncommonFromSentences (string s1, string s2) {push_back (' ' ); push_back (' ' );string_view view1 (s1) ;string_view view2 (s2) ;int > count; int last_pos = 0 ;int pos;while ((pos = view1.find (' ' , last_pos)) != string::npos) { substr (last_pos, pos - last_pos)]++;1 ;0 ;while ((pos = view2.find (' ' , last_pos)) != string::npos) { substr (last_pos, pos - last_pos)]++;1 ;for (auto & kv : count) {if (kv.second == 1 ) { emplace_back (string (kv.first));return res;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public :vector<string> uncommonFromSentences (string s1, string s2) {int > freq;auto insert = [&](const string& s) {ss (s);while (ss >> word) {move (word)];insert (s1);insert (s2);for (const auto & [word, occ]: freq) {if (occ == 1 ) {push_back (word);return ans;
二叉树最底层最左边的值 给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
这个题很容易想到使用BFS或DFS,不过感觉BFS适合一点,实现时我将层级信息一并存储,并保证左子节点先加入队列,后通过比较当前层级信息来得到该层的第一个叶子节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public :int findBottomLeftValue (TreeNode *root) int >> q; emplace (root, 1 ); int max_level = 0 ;int left_value = 0 ;while (!q.empty ()) {auto [node, level] = q.front ();pop ();if (level > max_level && node->left == nullptr && node->right == nullptr ) { if (node->left != nullptr ) { emplace (node->left, level + 1 ); if (node->right != nullptr ) {emplace (node->right, level + 1 );return left_value;
而官方题解则直接让右边的子节点先加入队列 ,省去大段的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public :int findBottomLeftValue (TreeNode* root) int ret;push (root);while (!q.empty ()) {auto p = q.front ();pop ();if (p->right) {push (p->right);if (p->left) {push (p->left);return ret;
删除子文件夹 你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。
没想到啥高深的方法,就直接对数组进行排序,而后依次判断各个文件夹是否为前面最后一个独立文件夹(即不是其他文件夹的子文件夹)的子文件夹。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :bool isSubFolder (const string& s1, const string& s2) if (s1.length () >= s2.length ()) { return false ;int s1_len = s1.length ();for (int i = 0 ; i < s1_len; i++) {if (s1[i] != s2[i]) {return false ;return s2[s1_len] == '/' ; vector<string> removeSubfolders (vector<string>& folder) {int folder_size = folder.size ();sort (folder.begin (), folder.end ()); emplace_back (move (folder[0 ])); for (int i = 1 ; i < folder_size; i++) {if (!isSubFolder (res.back (), folder[i])) { emplace_back (move (folder[i]));return res;
官方题解给出了一种字典树的解法
字符串的好分割数目 题目简要
看到是求数目,就排除了动态规划(一般是最优解问题),一时间没想到啥好方法,就直接顺序逆序两次遍历,然后利用集合的特性,得到不同字符的数目,最后进行一次比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public :int numSplits (string s) int len = s.length ();vector<int > left (len) ;vector<int > right (len) ;char > left_set;char > right_set;for (int i = 0 ; i < len; i++) {size ();emplace (s[i]);for (int i = len - 1 ; i >= 0 ; i--) {emplace (s[i]);size ();int num = 0 ;for (int i = 0 ; i < len; i++) {if (left[i] > right[i]) {return num;else if (left[i] == right[i]) {return num;
而官方题解则使用递推公式,利用了上一次的信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public :int numSplits (string s) int len = s.length ();vector<int > left (len) ;vector<int > right (len) ;vector<bool > left_occur (26 , false ) ;vector<bool > right_occur (26 , false ) ;0 ] = 1 ; 0 ] - 'a' ] = true ;for (int i = 1 ; i < len; i++) { if (left_occur[s[i] - 'a' ] == true ) {1 ];else {'a' ] = true ;1 ] + 1 ;1 ] = 1 ; 1 ] - 'a' ] = true ;for (int i = len - 2 ; i >= 0 ; i--) { if (right_occur[s[i] - 'a' ] == true ) {1 ];else {'a' ] = true ;1 ] + 1 ;int num = 0 ;for (int i = 0 ; i < len - 1 ; i++) {if (left[i] > right[i + 1 ]) {return num;else if (left[i] == right[i + 1 ]) {return num;
最接近目标价格的甜点成本 最接近目标价格的甜点成本 题目简要: 你打算做甜点,现在需要购买配料。目前共有 n 种冰激凌基料和 m 种配料可供选购。而制作甜点需要遵循以下几条规则:
必须选择 一种 冰激凌基料。
可以添加 一种或多种 配料,也可以不添加任何配料。
每种类型的配料 最多两份 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public :void comparePrice (int cost) int diff = abs (cost - target_price);if (diff < min_target_diff || (diff == min_target_diff && cost < suit_price)) {void findCloseCost (vector<int >& toppingCosts, int start, int end, int cur_cost) if (cur_cost > target_price || start > end) { comparePrice (cur_cost);return ;if (target_price - cur_cost < toppingCosts[start]) { comparePrice (cur_cost); else if (target_price - cur_cost < toppingCosts[start] * 2 ) { comparePrice (cur_cost + toppingCosts[start]); findCloseCost (toppingCosts, start + 1 , end, cur_cost); findCloseCost (toppingCosts, start + 1 , end, cur_cost + toppingCosts[start]); findCloseCost (toppingCosts, start + 1 , end, cur_cost + toppingCosts[start] * 2 ); int closestCost (vector<int >& baseCosts, vector<int >& toppingCosts, int target) abs (baseCosts[0 ] - target); 0 ];int top_size = toppingCosts.size ();for (int base : baseCosts) {findCloseCost (toppingCosts, 0 , top_size - 1 , base); return suit_price;private :int min_target_diff; int suit_price; int target_price;
不是所有的深度搜索都需要for循环
考虑边界条件,都大于或都小于
字符串中不同整数的数目 给你一个字符串 word ,该字符串由数字和小写英文字母组成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <bits/stdc++.h> using namespace std;class Solution {public :int numDifferentIntegers (string word) int status = 0 ; int number_start;int number_end;char c;push_back ('a' ); int len = word.length ();for (int i = 0 ; i < len; i++) {if (status == 0 && (c >= '0' && c <= '9' )) { 1 ;else if (status == 1 && !(c >= '0' && c <= '9' )) { 1 ;0 ;while (number_start <= number_end && word[number_start] == '0' ) { if (number_start > number_end) { emplace ("0" );else { emplace (word.substr (number_start, number_end - number_start + 1 ));return numbers.size ();
注意整数溢出
通过最少操作次数使数组的和相等 题目简要
我的解法(不咋行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 const int kInf = 0x7fffffff ;class Solution {public :int minOperations (vector<int >& nums1, vector<int >& nums2) int size1 = nums1.size ();int size2 = nums2.size ();int max_size = max (size1, size2);int min_size = min (size1, size2);int possible_value_start = max_size;int possible_value_end = min_size * 6 ;if (possible_value_start > possible_value_end) { return -1 ;int sum1 = 0 ;int sum2 = 0 ;for (int num : nums1) {for (int num : nums2) {if (sum1 == sum2) { return 0 ;max (min (sum1, sum2), possible_value_start);min (max (sum1, sum2), possible_value_end);sort (nums1.begin (), nums1.end ());sort (nums2.begin (), nums2.end ());vector<int > dist1 (size1 * 6 + 1 ) ;vector<int > dist2 (size2 * 6 + 1 ) ;0 ;0 ;int index, next_index;if (sum1 <= possible_value_start) { 1 ;for (int i = 1 ; i <= size1; i++) { 6 - nums1[i - 1 ];for (int j = index; j < next_index; j++) {if (index > possible_value_end) { break ;1 ;for (int i = 1 ; i <= size2; i++) { 1 ;for (int j = index; j > next_index; j--) {if (index < possible_value_start) { break ;else { 1 ;for (int i = 1 ; i <= size2; i++) {6 - nums2[i - 1 ];for (int j = index; j < next_index; j++) {if (index > possible_value_end) {break ;1 ;for (int i = 1 ; i <= size1; i++) {1 ;for (int j = index; j > next_index; j--) {if (index < possible_value_start) {break ;int min_times = size1 + size2;for (int i = possible_value_start; i <= possible_value_end; i++) { min (min_times, dist1[i] + dist2[i]);return min_times;
参考解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution {public :int minOperations (vector<int >& nums1, vector<int >& nums2) int size1 = nums1.size ();int size2 = nums2.size ();int max_size = max (size1, size2);int min_size = min (size1, size2);int possible_value_start = max_size;int possible_value_end = min_size * 6 ;if (possible_value_start > possible_value_end) { return -1 ;int sum1 = accumulate (nums1.begin (), nums1.end (), 0 );int sum2 = accumulate (nums2.begin (), nums2.end (), 0 );int diff = sum1 - sum2;if (diff == 0 ) {return 0 ;if (diff < 0 ) { swap (nums1, nums2);int cnt[6 ] = {0 };for (int num : nums1) { 1 ]++;for (int num : nums2) { 6 - num]++;int times = 0 ;for (int i = 5 ; i >= 1 ; i--) { if (diff - i * cnt[i] <= 0 ) { 1 ) / i; return times;return -1 ;
参考解法比我的解法简洁的点在于:
还原排列的最少操作步数 题目简要
一步操作中,你将创建一个新数组 arr ,对于每个 i :
要想使 perm 回到排列初始值,至少需要执行多少步操作?返回最小的 非零 操作步数。
我开始想找规律,但看了看没找到,就直接模拟了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public :bool check (const vector<int >& vec) int size = vec.size ();for (int i = 0 ; i < size; i++) {if (vec[i] != i) {return false ;return true ;int reinitializePermutation (int n) int >> arr (2 , vector <int >(n));for (int i = 0 ; i < n; i++) {0 ][i] = i;int times = 0 ;int src = 1 ;int des = 0 ;do {swap (src, des);for (int i = 0 ; i < n; i++) {2 == 0 ) ? arr[src][i / 2 ] : arr[src][n / 2 + (i - 1 ) / 2 ];while (!check (arr[des]));return times;
参考解法
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public :int reinitializePermutation (int n) int times = 0 ;int i = 1 ;do {2 == 0 ? i / 2 : (n + i - 1 ) / 2 ;while (i != 1 );return times;
句子相似性 III 题目简要
如果两个句子 sentence1 和 sentence2 ,可以通过往其中一个句子插入一个任意的句子(可以是空句子)而得到另一个句子,那么我们称这两个句子是 相似的 。比方说,sentence1 = “Hello my name is Jane” 且 sentence2 = “Hello Jane” ,我们可以往 sentence2 中 “Hello” 和 “Jane” 之间插入 “my name is” 得到 sentence1 。
给你两个句子 sentence1 和 sentence2 ,如果 sentence1 和 sentence2 是相似的,请你返回 true ,否则返回 false 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class Solution {public :vector<string> split (string& s) {' ' ; size_t last_pos = 0 ;size_t pos = 0 ;while (pos != string::npos) {find (' ' , last_pos);if (pos != string::npos) {emplace_back (s.substr (last_pos, pos - last_pos)); 1 ;return res;bool areSentencesSimilar (string sentence1, string sentence2) if (sentence1.length () > sentence2.length ()) { swap (sentence1, sentence2);split (sentence1);split (sentence2);int i = 0 ;int j = strs1.size () - 1 ;int k = strs2.size () - 1 ;while (i < strs1.size () && strs1[i] == strs2[i]) {while (j >= 0 && strs1[j] == strs2[k]) {return i > j;class Solution {public :vector<string_view> split (string& str) {' ' ; string_view s (str) ;size_t last_pos = 0 ;size_t pos = 0 ;while (pos != string::npos) {find (' ' , last_pos);if (pos != string::npos) {emplace_back (s.substr (last_pos, pos - last_pos)); 1 ;return res;bool areSentencesSimilar (string sentence1, string sentence2) if (sentence1.length () > sentence2.length ()) { swap (sentence1, sentence2);split (sentence1);split (sentence2);int i = 0 ;int j = strs1.size () - 1 ;int k = strs2.size () - 1 ;while (i < strs1.size () && strs1[i] == strs2[i]) {while (j >= 0 && strs1[j] == strs2[k]) {return i > j;
与官方题解相比运行时间有较大差距,主要在于对string_view类型的应用
std::string_view类的成员变量只包含两个:字符串指针和字符串长度。字符串指针可能是某个连续字符串的其中一段的指针,而字符串长度也不一定是整个字符串长度,也有可能是某个字符串的一部分长度。std::string_view所实现的接口中,完全包含了std::string的所有只读的接口,所以在很多场合可以轻易使用std::string_view代替std::string。一个通常的用法是,生成一个std::string后,如果后续的操作不再对其进行修改,那么可以考虑把std::string转换成为std::string_view,后续操作全部使用std::string_view来进行,这样字符串的传递变得轻量级。
C++17剖析:string_view的实现,以及性能
统计网格图中没有被保卫的格子数 题目简要
暴力枚举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public :int countUnguarded (int m, int n, vector<vector<int >>& guards, vector<vector<int >>& walls) int >> arr (m, vector <int >(n, 0 )); for (auto & guard : guards) {0 ]][guard[1 ]] = -1 ;for (auto & wall : walls) {0 ]][wall[1 ]] = -2 ;int dir[4 ][2 ] = {{0 , 1 }, {1 , 0 }, {0 , -1 }, {-1 , 0 }};int protected_block = 0 ;for (auto & guard : guards) {for (int i = 0 ; i < 4 ; i++) {int x = guard[0 ];int y = guard[1 ];int next_x = x + dir[i][0 ];int next_y = y + dir[i][1 ];while (next_x >= 0 && next_x < m && next_y >= 0 && next_y < n && arr[next_x][next_y] >= 0 ) { if (arr[next_x][next_y] == 0 ) {1 ; 0 ];1 ];int unprotected_num = m * n - guards.size () - walls.size () - protected_block;return unprotected_num;
官方题解——广度优先遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public :int countUnguarded (int m, int n, vector<vector<int >>& guards, vector<vector<int >>& walls) int >> arr (m, vector <int >(n, 0 )); int , int , int >> q;for (auto & guard : guards) {0 ]][guard[1 ]] = -1 ;for (int dir = 0 ; dir < 4 ; ++dir) {emplace (guard[0 ], guard[1 ], dir);for (auto & wall : walls) {0 ]][wall[1 ]] = -2 ;int directions[4 ][2 ] = {{0 , 1 }, {1 , 0 }, {0 , -1 }, {-1 , 0 }};int protected_block = 0 ;while (!q.empty ()) {auto [x, y, dir] = q.front ();pop ();int nx = x + directions[dir][0 ];int ny = y + directions[dir][1 ];if (nx >= 0 && nx < m && ny >= 0 && ny < n && arr[nx][ny] >= 0 && (arr[nx][ny] & (1 << dir)) == 0 ) { if (arr[nx][ny] == 0 ) { 1 << dir);emplace (nx, ny, dir);int unprotected_num = m * n - guards.size () - walls.size () - protected_block;return unprotected_num;
非常漂亮的思路,另外注意& ==的运算符优先级
最大二叉树与单调栈 题目简要
创建一个根节点,其值为 nums 中的最大值。思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public :TreeNode *impl (vector<int > &nums, vector<int >::iterator begin, vector<int >::iterator end) {if (begin >= end) {return nullptr ;int >::iterator max_pos = max_element (begin, end);new TreeNode (*max_pos);impl (nums, begin, max_pos); impl (nums, max_pos + 1 , end);return node;TreeNode *constructMaximumBinaryTree (vector<int > &nums) { return impl (nums, nums.begin (), nums.end ()); }
看完官方题解,竟然还能用所谓的单调栈求解,阅读一篇相关博客特殊数据结构:单调栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class Solution {public :vector<int > nextGreaterElement (vector<int >& nums1, vector<int >& nums2) {int > s;int , int > next; for (int i = nums2.size () - 1 ; i >= 0 ; i--) {while (!s.empty () && s.top () < nums2[i]) { pop ();int next_value = s.empty () ? -1 : s.top (); insert ({nums2[i], next_value});emplace (nums2[i]);vector<int > ans (nums1.size()) ;for (int i = 0 ; i < nums1.size (); i++) {return ans;class Solution {public :vector<int > nextGreaterElements (vector<int >& nums) {vector<int > ans (nums.size()) ;int > st;for (int i = nums.size () - 1 ; i >= 0 ; --i) {while (!st.empty () && st.top () <= nums[i]) {pop ();emplace (nums[i]);for (int i = nums.size () - 1 ; i >= 0 ; --i) {while (!st.empty () && st.top () <= nums[i]) {pop ();empty () ? -1 : st.top ();emplace (nums[i]);return ans;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution {public :TreeNode *constructMaximumBinaryTree (vector<int > &nums) {int n = nums.size ();int > st;vector<int > left (n, -1 ) , right (n, -1 ) ; vector<TreeNode *> tree (n) ; for (int i = 0 ; i < n; ++i) {new TreeNode (nums[i]); while (!st.empty () && nums[i] > nums[st.top ()]) { top ()] = i; pop (); if (!st.empty ()) { top ();emplace (i);nullptr ;for (int i = 0 ; i < n; ++i) {if (left[i] == -1 && right[i] == -1 ) { else if (right[i] == -1 || (left[i] != -1 && nums[left[i]] < nums[right[i]])) { else { return root;
和为s的连续正数序列 题目简要
思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public :int >> findContinuousSequence (int target) {int >> res;const int max_begin = target / 2 ;for (int i = 1 ; i <= max_begin; i++) {int num = i;int sum = target;while (sum > 0 ) { if (sum == 0 ) { int > arr;reserve (num - i); for (int j = i; j < num; j++) {emplace_back (j);emplace_back (move (arr)); return res;
看到官方题解双指针/滑动窗口解题,mark一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public :int >> findContinuousSequence (int target) {int >> vec;int > res;for (int l = 1 , r = 2 ; l < r;) {int sum = (l + r) * (r - l + 1 ) / 2 ;if (sum == target) {clear ();for (int i = l; i <= r; ++i) {emplace_back (i);emplace_back (res);else if (sum < target) {else {return vec;
LFU 缓存 题目简要
实现 LFUCache 类:
LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象
当一个键首次插入到缓存中时,它的使用计数器被设置为 1 (由于 put 操作)。对缓存中的键执行 get 或 put 操作,使用计数器的值将会递增。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 struct DataNode { int key_;int value_;int count_;DataNode (int key, int value, int count) : key_ (key), value_ (value), count_ (count) {}class LFUCache {public :LFUCache (int capacity) : size_ (0 ), capacity_ (capacity) {}int get (int key) if (capacity_ <= 0 ) {return -1 ;auto iter = speed_map_.find (key);if (iter == speed_map_.end ()) {return -1 ;auto new_pos = data_.erase (pos); while (new_pos != data_.end () && new_pos->count_ <= new_node.count_) {insert (new_pos, new_node);return new_node.value_;void put (int key, int value) if (capacity_ <= 0 ) {return ;auto iter = speed_map_.find (key);if (iter == speed_map_.end ()) {if (size_ == capacity_) { erase (data_.front ().key_);pop_front ();DataNode node (key, value, 1 ) ;auto pos = data_.begin ();while (pos != data_.end () && pos->count_ <= 1 ) {insert ({key, data_.insert (pos, node)});else {auto new_pos = data_.erase (pos);while (new_pos != data_.end () && new_pos->count_ <= new_node.count_) {insert (new_pos, new_node);private :int size_;int capacity_;int , list<DataNode>::iterator> speed_map_;
LFU与LRU不同的是,它并不是每次都会插入至队首或队尾,故更新节点位置时需要进行遍历,为此,就不能用链表作为存放数据的数据结构,而是平衡二叉树(set)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 struct DataNode { int key_;int value_;int count_; int insert_time_; DataNode (int key, int value, int count, int insert_time) : key_ (key), value_ (value), count_ (count), insert_time_ (insert_time) {}bool operator <(const DataNode& node) const { return count_ < node.count_ || (count_ == node.count_ && insert_time_ < node.insert_time_); } class LFUCache {public :LFUCache (int capacity) : capacity_ (capacity), timer_ (0 ) {}int get (int key) if (capacity_ <= 0 ) {return -1 ;auto iter = position_.find (key);if (iter == position_.end ()) { return -1 ;auto pos = iter->second;DataNode new_node (key, pos->value_, pos->count_ + 1 , timer_++) ;erase (pos);emplace (new_node).first;return new_node.value_;void put (int key, int value) if (capacity_ <= 0 ) {return ;auto iter = position_.find (key);if (iter == position_.end ()) { if (data_.size () == capacity_) { auto evict_pos = data_.begin ();erase (evict_pos->key_);erase (evict_pos);DataNode new_node (key, value, 1 , timer_++) ;insert ({key, data_.emplace (new_node).first});else { auto pos = iter->second;DataNode new_node (key, value, pos->count_ + 1 , timer_++) ;erase (pos);emplace (new_node).first;private :int capacity_;int timer_; int , set<DataNode>::iterator> position_;
DataNode包含key是为了淘汰时删除map中的数据。虽然题解1可以通过测试,但复杂度在对数级。题解2则使用两个哈希表,将复杂度降到了常数级。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 struct Node {int key, val, freq;Node (int _key, int _val, int _freq) : key (_key), val (_val), freq (_freq) {}class LFUCache {int minfreq, capacity;int , list<Node>::iterator> key_table;int , list<Node>> freq_table;public :LFUCache (int _capacity) {0 ;clear ();clear ();int get (int key) if (capacity == 0 ) return -1 ;auto it = key_table.find (key);if (it == key_table.end ()) return -1 ;int val = node->val, freq = node->freq;erase (node);if (freq_table[freq].size () == 0 ) {erase (freq);if (minfreq == freq) minfreq += 1 ;1 ].emplace_front (Node (key, val, freq + 1 ));1 ].begin ();return val;void put (int key, int value) if (capacity == 0 ) return ;auto it = key_table.find (key);if (it == key_table.end ()) {if (key_table.size () == capacity) {auto it2 = freq_table[minfreq].back ();erase (it2.key);pop_back ();if (freq_table[minfreq].size () == 0 ) {erase (minfreq);1 ].emplace_front (Node (key, value, 1 ));1 ].begin ();1 ;else {int freq = node->freq;erase (node);if (freq_table[freq].size () == 0 ) {erase (freq);if (minfreq == freq) minfreq += 1 ;1 ].emplace_front (Node (key, value, freq + 1 ));1 ].begin ();
螺旋矩阵 II 题目简要
开始想找规律,找到坐标与值的关系,没找到就直接模拟,刚开始用递归实现,先赋值外圈,再赋值内圈,后面直接改成非递归实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 const int dir[4 ][2 ] = {{0 , 1 }, {1 , 0 }, {0 , -1 }, {-1 , 0 }};class Solution {public :void computeNumber (vector<vector<int >>& vec, int start_x, int start_y, int start_value, int dim) if (dim == 0 ) {return ;if (dim == 1 ) {return ;int i = start_x;int j = start_y;int x = start_value;int times = dim * dim - (dim - 2 ) * (dim - 2 ) - 1 ; int cur_dir = 0 ;while (times--) {0 ];1 ];if (i == start_x && j == start_y + dim - 1 ) {1 ;else if (i == start_x + dim - 1 && j == start_y + dim - 1 ) {2 ;else if (i == start_x + dim - 1 && j == start_y) {3 ;computeNumber (vec, start_x + 1 , start_y + 1 , x, dim - 2 );int >> generateMatrix (int n) {int >> arr (n, vector <int >(n));computeNumber (arr, 0 , 0 , 1 , n);return arr;const int dir[4 ][2 ] = {{0 , 1 }, {1 , 0 }, {0 , -1 }, {-1 , 0 }};class Solution {public :int >> generateMatrix (int n) {int >> vec (n, vector <int >(n));int dim = n;int start_x = 0 ;int start_y = 0 ;int i = 0 ;int j = 0 ;int x = 1 ;int cur_dir = 0 ;int times = dim * dim - 1 ;while (times--) {0 ];1 ];if (i == start_x && j == start_y + dim - 1 ) {1 ;else if (i == start_x + dim - 1 && j == start_y + dim - 1 ) {2 ;else if (i == start_x + dim - 1 && j == start_y) {3 ;else if (i == start_x + 1 && j == start_y) {0 ;2 ;return vec;
官方题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public :int >> generateMatrix (int n) {int maxNum = n * n;int curNum = 1 ;int >> matrix (n, vector <int >(n));int row = 0 , column = 0 ;int >> directions = {{0 , 1 }, {1 , 0 }, {0 , -1 }, {-1 , 0 }}; int directionIndex = 0 ;while (curNum <= maxNum) {int nextRow = row + directions[directionIndex][0 ], nextColumn = column + directions[directionIndex][1 ];if (nextRow < 0 || nextRow >= n || nextColumn < 0 || nextColumn >= n || matrix[nextRow][nextColumn] != 0 ) {1 ) % 4 ; 0 ];1 ];return matrix;
我的解法远没有官方题解简洁,关键在于官方题解抓住了若不为 0,则说明已经访问过此位置。 的性质,减去了四角边界的检查。
最大整除子集 题目简要:
这个题目很容易看出是要使用动态规划解决,状态转移方程也比较容易看出,比较简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public :vector<int > largestDivisibleSubset (vector<int >& nums) {int nums_size = nums.size ();vector<int > dp (nums_size, 1 ) ; 0 ] = 1 ;sort (nums.begin (), nums.end ()); for (int i = 1 ; i < nums_size; i++) {for (int j = 0 ; j < i; j++) {if (nums[i] % nums[j] == 0 ) { max (dp[i], dp[j] + 1 );auto max_iter = max_element (dp.begin (), dp.end ()); if (*max_iter == 1 ) { return {nums[0 ]};int end = max_iter - dp.begin ();int count = *max_iter; int cur_multiple = nums[end]; int > ans;for (int i = end; i >= 0 ; i--) {if (cur_multiple % nums[i] == 0 && dp[i] == count) { emplace_back (nums[i]);if (count == 0 ) {return ans;return ans;
非重叠矩形中的随机点 题目简要:
在给定的矩形覆盖的空间内的任何整数点都有可能被返回。
我刚开始就直接用点数组存储所有矩阵中的点,对于每个矩阵都进行两层循环遍历,但提交后显示超时,故计算矩阵总面积,或者说将所有整数点抽象成一条直线,先计算直线的总长度,在直线范围内随机选择一点,而后找到与其相对应的点坐标。虽然我刚开始使用了矩阵面积的前缀和辅助计算,但由于不怎么熟悉c++二分查找的相关函数,没有使用二分查找的方法加速查找。最终代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :Solution (vector<vector<int >>& rects) {int rect_size = rects.size ();vector <int >(rect_size);0 ] = (rects[0 ][2 ] - rects[0 ][0 ] + 1 ) * (rects[0 ][3 ] - rects[0 ][1 ] + 1 );for (int i = 1 ; i < rect_size; i++) {int area = (rects[i][2 ] - rects[i][0 ] + 1 ) * (rects[i][3 ] - rects[i][1 ] + 1 );1 ] + area;1 ];this ->rects = move (rects);vector<int > pick () {int index = rand () % area_sum;int i = upper_bound (area_cusum.begin (), area_cusum.end (), index) - area_cusum.begin ();int rect_index = (i == 0 ) ? index : index - area_cusum[i - 1 ];int x = rect_index % (rects[i][2 ] - rects[i][0 ] + 1 ) + rects[i][0 ];int y = rect_index / (rects[i][2 ] - rects[i][0 ] + 1 ) + rects[i][1 ];return {x, y};private :int >> rects;int > area_cusum; int area_sum;
C++ 语言基础 —— STL —— 算法 —— 二分查找算法
模拟行走机器人 题目简要:
我的解法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 class Solution {public :int robotSim (vector<int >& commands, vector<vector<int >>& obstacles) int , set<int >> obstacle_x; int , set<int >> obstacle_y; for (auto & obstacle : obstacles) {if (obstacle_x.count (obstacle[0 ]) == 0 ) {0 ]] = {obstacle[1 ]};else {0 ]].emplace (obstacle[1 ]);if (obstacle_y.count (obstacle[1 ]) == 0 ) {1 ]] = {obstacle[0 ]};else {1 ]].emplace (obstacle[0 ]);int dir[4 ][2 ] = {{1 , 0 }, {0 , -1 }, {-1 , 0 }, {0 , 1 }}; int index = 3 ;int x = 0 ;int y = 0 ;int max_dist = 0 ;int next_x;int next_y;for (int cmd : commands) {switch (cmd) {case -1 :1 ) % 4 ; break ;case -2 :3 ) % 4 ; break ;default :0 ] * cmd;1 ] * cmd;switch (index) {case 0 : if (obstacle_y.count (y) != 0 ) {for (auto iter = obstacle_y[y].begin (); iter != obstacle_y[y].end (); ++iter) {if (*iter > x && *iter <= next_x) { 1 ;break ;break ;case 1 : if (obstacle_x.count (x) != 0 ) {for (auto iter = obstacle_x[x].rbegin (); iter != obstacle_x[x].rend (); ++iter) {if (*iter < y && *iter >= next_y) { 1 ;break ;break ;case 2 : if (obstacle_y.count (y) != 0 ) {for (auto iter = obstacle_y[y].rbegin (); iter != obstacle_y[y].rend (); ++iter) {if (*iter < x && *iter >= next_x) { 1 ;break ;break ;case 3 : if (obstacle_x.count (x) != 0 ) {for (auto iter = obstacle_x[x].begin (); iter != obstacle_x[x].end (); ++iter) {if (*iter > y && *iter <= next_y) { 1 ;break ;break ;break ;default :break ;max (max_dist, x * x + y * y);break ;return max_dist;
官方题解(修改后)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 using Coord = pair<int , int >;struct CoordHash {size_t operator () (const Coord& c) const auto fn = hash <int >();return fn (c.first) ^ fn (c.second);class Solution {public :int robotSim (vector<int >& commands, vector<vector<int >>& obstacles) for (auto & obstacle : obstacles) { emplace (Coord{obstacle[0 ], obstacle[1 ]});int dir[4 ][2 ] = {{1 , 0 }, {0 , -1 }, {-1 , 0 }, {0 , 1 }}; int index = 3 ;int x = 0 ;int y = 0 ;int max_dist = 0 ;int next_x;int next_y;for (int cmd : commands) {switch (cmd) {case -1 :1 ) % 4 ; break ;case -2 :3 ) % 4 ; break ;default :0 ] * cmd;1 ] * cmd;for (int k = 1 ; k <= cmd; k++) {if (obstacle_set.count ({x + dir[index][0 ] * k, y + dir[index][1 ] * k}) != 0 ) { 0 ] * (k - 1 );1 ] * (k - 1 );break ;max (max_dist, x * x + y * y);break ;return max_dist;
我的解法比官方题解多很多代码的点在于没有很好利用dir[index][0]和dir[index][1],而是对index进行分类(东南西北),另外想利用机器人走直线的特点,x全部相等或y全部相等,但遍历时不能直接跳转到出发点,仍需从头或从尾开始遍历,效率很低,不如直接一个一个坐标判断是否在障碍点集合中。在 C++ 中用 lambda 函数自定义 unordered_set 时,为什么赋值运算符失效了?
从给定原材料中找到所有可以做出的菜 题目简要:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <bits/stdc++.h> using namespace std;class Solution {public :vector<string> findAllRecipes (vector<string>& recipes, vector<vector<string>>& ingredients, vector<string>& supplies) {int > recipe_map;int recipe_size = recipes.size ();int >> adjacency_list (recipe_size); vector<int > induity (recipe_size, 0 ) ; vector<int > result (recipe_size, -1 ) ; for (int i = 0 ; i < recipe_size; i++) {for (string& supply : supplies) {emplace (supply);for (int i = 0 ; i < recipe_size; i++) {bool include_all_ingredient = true ;for (string& ingredient : ingredients[i]) {if (supply_set.count (ingredient) == 0 ) { false ;auto iter = recipe_map.find (ingredient);if (iter == recipe_map.end ()) { 0 ; 0 ;break ;else { emplace_back (i);if (include_all_ingredient) { 1 ;int > in_queue;for (int i = 0 ; i < recipe_size; i++) { if (induity[i] == 0 ) {emplace (i);while (!in_queue.empty ()) {int i = in_queue.front ();pop ();for (int j : adjacency_list[i]) {if (induity[j] == 0 ) { emplace (j);if (result[i] == 0 ) { 0 ;else if (result[j] != 0 ) { 1 ;for (int i = 0 ; i < recipe_size; i++) {if (result[i] == 1 && induity[i] == 0 ) { emplace_back (recipes[i]);return ans;
最后再次判断入度以解决环问题官方题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public :vector<string> findAllRecipes (vector<string>& recipes, vector<vector<string>>& ingredients, vector<string>& supplies) {int n = recipes.size ();int > cnt;for (int i = 0 ; i < n; ++i) {for (const string& ing: ingredients[i]) {push_back (recipes[i]);size ();for (const string& sup: supplies) {push (sup);while (!q.empty ()) {front ();pop ();if (depend.count (cur)) {for (const string& rec: depend[cur]) {if (cnt[rec] == 0 ) {push_back (rec);push (rec);return ans;
评论:
有鸡蛋,可以用来做煎蛋,煮蛋,鸡蛋羹,鸡蛋布丁
有煎蛋,可以拿来做三明治,汉堡,夹心煎饼
但是用菜肴找菜,就会存在套娃问题。
我想要鸡蛋,需要先获得母鸡
想要母鸡,需要先获得鸡蛋
翻转卡片游戏 题目简要:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <bits/stdc++.h> using namespace std;class Solution {public :int flipgame (vector<int >& fronts, vector<int >& backs) const int n = fronts.size ();int , int > number_map;for (int i = 0 ; i < n; i++) {if (fronts[i] == backs[i]) { 1 ;else {for (auto & kv : number_map) { if (kv.second <= n) { return kv.first;return 0 ;
多使用哈希表与集合,把它们当做树 图一样的解题数据结构
元音拼写检查器 题目简要
当查询完全匹配单词列表中的某个单词(区分大小写)时,应返回相同的单词。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <bits/stdc++.h> using namespace std;class Solution {public :string modifyError (const string& origin, bool vowel_option) { int len = origin.length ();resize (len);const string vowel = "aeiouAEIOU" ;for (int i = 0 ; i < len; i++) {if (vowel_option && vowel.find (origin[i]) != string::npos) { 'a' ;else if (origin[i] <= 'Z' ) { 'a' - 'A' );else {return feature;vector<string> spellchecker (vector<string>& wordlist, vector<string>& queries) {int word_size = wordlist.size ();int > right_map;int > case_error_map;int > vowel_error_map;for (int i = word_size - 1 ; i >= 0 ; i--) { modifyError (wordlist[i], false )] = i;modifyError (wordlist[i], true )] = i;for (string& query : queries) {auto iter = right_map.find (query); if (iter != right_map.end ()) {emplace_back (wordlist[iter->second]);continue ;find (modifyError (query, false )); if (iter != case_error_map.end ()) {emplace_back (wordlist[iter->second]);continue ;find (modifyError (query, true )); if (iter != case_error_map.end ()) {emplace_back (wordlist[iter->second]);continue ;emplace_back ("" ); return result;
使用map/set加速查找,用空间换时间未使用map直接查找的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <bits/stdc++.h> using namespace std;class Solution {public :string modifyError (const string& origin, bool vowel_option) {int len = origin.length ();resize (len);const string vowel = "aeiouAEIOU" ;for (int i = 0 ; i < len; i++) {if (vowel_option && vowel.find (origin[i]) != string::npos) {'a' ;else if (origin[i] <= 'Z' ) {'a' - 'A' );else {return feature;vector<string> spellchecker (vector<string>& wordlist, vector<string>& queries) {int word_size = wordlist.size ();for (string& word : wordlist) {emplace_back (modifyError (word, false ));emplace_back (modifyError (word, true ));for (string& query : queries) {bool find = false ;for (int i = 0 ; i < word_size; i++) {if (wordlist[i] == query) {emplace_back (wordlist[i]);true ;break ;if (find == false ) {modifyError (query, false );for (int i = 0 ; i < word_size; i++) {if (case_error[i] == case_query) {emplace_back (wordlist[i]);true ;break ;if (find == false ) {modifyError (query, true );for (int i = 0 ; i < word_size; i++) {if (vowel_error[i] == vowel_query) {emplace_back (wordlist[i]);true ;break ;if (find == false ) {emplace_back ("" );return result;
信物传送 题目简要: 结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 const int kInf = 0x7fffffff ;struct Node {Node () {}Node (int x, int y, int value) {this ->x = x;this ->y = y;this ->value = value;bool operator <(const Node& node) const { return this ->value > node.value; } int x;int y;int value;class Solution {public :bool check (int x, int y, int n, int m) if (x >= 0 && x < n && y >= 0 && y < m) {return true ;return false ;int conveyorBelt (vector<string>& matrix, vector<int >& start, vector<int >& end) int row = matrix.size ();int col = matrix[0 ].size ();int >> dist (row, vector <int >(col, kInf));bool >> marked (row, vector <bool >(col, false ));int dir[4 ][2 ] = {0 , 1 , 1 , 0 , 0 , -1 , -1 , 0 };char , int > symbol = {{'>' , 0 }, {'v' , 1 }, {'<' , 2 }, {'^' , 3 }}; 0 ]][start[1 ]] = 0 ;emplace (Node{start[0 ], start[1 ], 0 }); while (!small_heap.empty ()) {auto node = small_heap.top ();pop ();true ; if (node.x == end[0 ] && node.y == end[1 ]) {return node.value;for (int i = 0 ; i < 4 ; i++) { int next_x = node.x + dir[i][0 ];int next_y = node.y + dir[i][1 ];if (check (next_x, next_y, row, col) && !marked[next_x][next_y]) { if (i == symbol[matrix[node.x][node.y]]) { min (dist[next_x][next_y], node.value);else { min (dist[next_x][next_y], node.value + 1 );emplace (Node{next_x, next_y, dist[next_x][next_y]});return dist[end[0 ]][end[1 ]];
lambda表达式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 const int kInf = 0x7fffffff ;using Node = tuple<int , int , int >;class Solution {public :bool check (int x, int y, int n, int m) if (x >= 0 && x < n && y >= 0 && y < m) {return true ;return false ;int conveyorBelt (vector<string>& matrix, vector<int >& start, vector<int >& end) int row = matrix.size ();int col = matrix[0 ].size ();int >> dist (row, vector <int >(col, kInf));bool >> marked (row, vector <bool >(col, false ));auto compare = [](const Node& node1, const Node& node2) -> bool { return get <0 >(node1) > get <0 >(node2); }; decltype (compare)> small_heap (compare);int dir[4 ][2 ] = {0 , 1 , 1 , 0 , 0 , -1 , -1 , 0 };char , int > symbol = {{'>' , 0 }, {'v' , 1 }, {'<' , 2 }, {'^' , 3 }}; 0 ]][start[1 ]] = 0 ;emplace (Node{0 , start[0 ], start[1 ]}); while (!small_heap.empty ()) {auto [val, x, y] = small_heap.top ();pop ();true ; if (x == end[0 ] && y == end[1 ]) {return val;for (int i = 0 ; i < 4 ; i++) { int next_x = x + dir[i][0 ];int next_y = y + dir[i][1 ];if (check (next_x, next_y, row, col) && !marked[next_x][next_y]) { if (i == symbol[matrix[x][y]]) { min (dist[next_x][next_y], val);else { min (dist[next_x][next_y], val + 1 );emplace (Node{dist[next_x][next_y], next_x, next_y});return dist[end[0 ]][end[1 ]];
使用方向数组简化处理流程c++优先队列priority_queue(自定义比较函数) C++函数指针、函数对象与C++11 function对象对比分析 【C++深陷】之“decltype”
引爆最多的炸弹 题目简要 :给你一个炸弹列表。一个炸弹的 爆炸范围 定义为以炸弹为圆心的一个圆。
邻接矩阵实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <bits/stdc++.h> using namespace std;using ll = long long ;class Solution {public :bool inRadius (vector<int > start, vector<int > end) 0 ] - end[0 ]) * (start[0 ] - end[0 ]) + (ll)(start[1 ] - end[1 ]) * (start[1 ] - end[1 ]);return (ll)(start[2 ]) * start[2 ] >= dist;int maximumDetonation (vector<vector<int >>& bombs) int bomb_number = bombs.size ();bool >> connected (bomb_number, vector <bool >(bomb_number)); for (int i = 0 ; i < bomb_number; i++) {for (int j = 0 ; j < bomb_number; j++) {if (i != j) { inRadius (bombs[i], bombs[j]);int visit_node;int visit_node_num;int max_visit_node_num = 1 ;int > visit_queue;vector<bool > marked (bomb_number, false ) ; vector<int > trace (bomb_number, -1 ) ; for (int i = 0 ; i < bomb_number; i++) {if (marked[i] == false ) {0 ;emplace (i); while (!visit_queue.empty ()) {front ();pop ();true ;for (int j = 0 ; j < bomb_number; j++) {if (trace[j] != i && connected[visit_node][j] == true ) {emplace (j);max (max_visit_node_num, visit_node_num);return max_visit_node_num;
邻接表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <bits/stdc++.h> using namespace std;using ll = long long ;class Solution {public :bool inRadius (vector<int > start, vector<int > end) 0 ] - end[0 ]) * (start[0 ] - end[0 ]) + (ll)(start[1 ] - end[1 ]) * (start[1 ] - end[1 ]);return (ll)(start[2 ]) * start[2 ] >= dist;int maximumDetonation (vector<vector<int >>& bombs) int bomb_number = bombs.size ();int >> connected (bomb_number); for (int i = 0 ; i < bomb_number; i++) {for (int j = 0 ; j < bomb_number; j++) {if (i != j && inRadius (bombs[i], bombs[j])) {emplace_back (j);int > visit_queue;int visit_node;int visit_node_num;int max_visit_node_num = 1 ;vector<bool > marked (bomb_number, false ) ; vector<int > trace (bomb_number, -1 ) ; for (int i = 0 ; i < bomb_number; i++) {if (marked[i] == false ) {0 ;emplace (i); while (!visit_queue.empty ()) {front ();pop ();true ;for (int j : connected[visit_node]) {if (trace[j] != i) {emplace (j);max (max_visit_node_num, visit_node_num);return max_visit_node_num;
使用trace避免环问题,使用marked去除没必要的节点遍历
从二叉树一个节点到另一个节点每一步的方向 题目简要:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution {public :bool findValue (TreeNode *node, int target_value, vector<int > &trace) if (node->val == target_value) { return true ;if (node->left != nullptr ) {if (findValue (node->left, target_value, trace)) { emplace_back (-1 );return true ;if (node->right != nullptr ) {if (findValue (node->right, target_value, trace)) { emplace_back (1 );return true ;return false ;string getDirections (TreeNode *root, int startValue, int destValue) {int > trace1, trace2;findValue (root, startValue, trace1); findValue (root, destValue, trace2); int i = trace1.size () - 1 ;int j = trace2.size () - 1 ;while (i >= 0 && j >= 0 && trace1[i] == trace2[j]) { string (i + 1 , 'U' ); while (j >= 0 ) { if (trace2[j] == 1 ) {push_back ('R' );else {push_back ('L' );return ans;
回溯法得到逆序轨迹
最长回文子串 使用备忘录的递归方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const int kNotInitialized = -1 ;class Solution {public :string longestPalindrome (string s) {int len = s.length ();int >>(len, vector <int >(len, kNotInitialized)); for (int j = len; j >= 1 ; j--) { for (int i = 0 ; i < len - j + 1 ; i++) { if (isPalindrome (s, i, i + j - 1 )) {return s.substr (i, j);return "" ;bool isPalindrome (string& s, int i, int j) if (memo[i][j] != kNotInitialized) { return memo[i][j] == 1 ;if (i >= j) { 1 ;return true ;if (s[i] == s[j]) {isPalindrome (s, i + 1 , j - 1 ) ? 1 : 0 ; return memo[i][j] == 1 ;else {0 ;return false ;private :int >> memo;
动态规划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public :string longestPalindrome (string s) {int len = s.length ();int >> dp (len, vector <int >(len)); for (int i = 0 ; i < len - 1 ; i++) { 1 ;int longest_palindrome_length = 1 ;int longest_palindrome_start = 0 ;int end;for (int palindrome_length = 2 ; palindrome_length <= len; palindrome_length++) { for (int start = 0 ; start < len - palindrome_length + 1 ; start++) { 1 ; if (s[start] == s[end]) {if (end - start < 3 ) { 1 ;else {1 ][end - 1 ]; else {0 ;if (dp[start][end] == 1 && palindrome_length > longest_palindrome_length) { return s.substr (longest_palindrome_start, longest_palindrome_length);
1.递归方法自顶向下,动态规划自底向上
只出现一次的数字 只出现一次的数字 题目简要 :给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
1 2 3 4 5 6 7 8 9 10 class Solution {public :int singleNumber (vector<int >& nums) int ans =0 ;for (int num:nums){return ans;
异或运算性质
其他数字出现三次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public :int singleNumber (vector<int >& nums) int ans = 0 ;int bit_num = 0 ;for (int i = 0 ; i < 32 ; i++) { 0 ;for (int num : nums) {1 ); if (bit_num % 3 != 0 ) { 1 << i;return ans;
位运算
二叉搜索树中两个节点之和 剑指 Offer II 056. 二叉搜索树中两个节点之和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :void preOrderTraversal (TreeNode *node, vector<int > &sort_list) if (node == nullptr ) { return ;preOrderTraversal (node->left, sort_list); emplace_back (node->val); preOrderTraversal (node->right, sort_list); bool findTarget (TreeNode *root, int k) int > sort_list;preOrderTraversal (root, sort_list);int p = 0 ;int q = sort_list.size () - 1 ;int sum;while (p < q) {if (sum > k) { else if (sum < k) { else { return true ;return false ;
中序遍历+双指针
多次求和构造目标数组 多次求和构造目标数组
给你一个整数数组 target 。一开始,你有一个数组 A ,它的所有元素均为 1 ,你可以执行以下操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <bits/stdc++.h> using namespace std;using ll = long long ;class Solution {public :bool isPossible (vector<int >& target) if (target.size () == 1 ) { return target[0 ] == 1 ;0 , other_number_sum = 0 ;int > max_queue;int max_value, divisor_number;for (int n : target) { emplace (n);while (true ) {top ();pop ();if (max_value == 1 || other_number_sum == 1 ) { return true ;if (max_value <= other_number_sum || max_value % other_number_sum == 0 ) { return false ;emplace (max_value); return false ;
解题关键:
全排列 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :void backtrack (const vector<int >& nums, vector<vector<int >>& res, vector<int >& output, vector<bool >& mark, int first, int len) if (first == len) {emplace_back (output);return ;for (int i = 0 ; i < len; i++) {if (!mark[i]) {true ;emplace_back (nums[i]);backtrack (nums, res, output, mark, first + 1 , len);false ;pop_back ();int >> permute (vector<int >& nums) { int n = static_cast <int >(nums.size ());int >> res;vector<bool > mark (n, false ) ;int > output;backtrack (nums, res, output, mark, 0 , n); return res;
官方题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public :void backtrack (vector<int >& nums, vector<vector<int >>& res, int first, int len) if (first == len) {emplace_back (nums);return ;for (int i = first; i < len; i++) { swap (nums[i], nums[first]);backtrack (nums, res, first + 1 , len);swap (nums[i], nums[first]);int >> permute (vector<int >& nums) { int n = static_cast <int >(nums.size ());int >> res;backtrack (nums, res, 0 , n);return res;
电话号码的字母组合 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public :void traverse (const vector<string>& source, string combine, int start, int end, vector<string>& res) if (start == end) { emplace_back (combine);return ;for (auto letter : source[start]) { traverse (source, combine + letter, start + 1 , end, res);vector<string> letterCombinations (string digits) {if (digits.empty ()) {return {};static vector<string> dig2str = {"abc" , "def" , "ghi" , "jkl" , "mno" , "pqrs" , "tuv" , "wxyz" }; int idx;for (auto digit : digits) { static_cast <int >(digit - '2' );emplace_back (dig2str[idx]);int digit_len = static_cast <int >(digits.size ());traverse (strs, "" , 0 , digit_len, res); return res;
两个列表的最小索引总和 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class Solution {public :vector<string> findRestaurant (vector<string>& list1, vector<string>& list2) {int len1 = static_cast <int >(list1.size ());int len2 = static_cast <int >(list2.size ());int max_idx_sum = len1 + len2 - 2 ;bool flag = false ;int low_bound;int high_bound;for (int k = 0 ; k <= max_idx_sum; k++) { max (0 , k + 1 - len2);min (k, len1 - 1 );for (int i = low_bound; i <= high_bound; i++) {if (list1[i] == list2[k - i]) {emplace_back (list1[i]);true ;if (flag) {break ;return res;vector<string> findRestaurant (vector<string>& list1, vector<string>& list2) {int len1 = static_cast <int >(list1.size ());int len2 = static_cast <int >(list2.size ());int > index;for (int i = 0 ; i < len1; i++) { insert ({list1[i], i});int min_index_sum = len1 + len2 + 1 ;int index_sum;for (int i = 0 ; i < len2; i++) {if (index.count (list2[i]) > 0 ) { if (index_sum < min_index_sum) {clear ();emplace_back (list2[i]);else if (index_sum == min_index_sum) {emplace_back (list2[i]);if (i > min_index_sum) { break ;return res;
IP 地址无效化 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public :string defangIPaddr (string address) {size_t last_pos = 0 ;size_t cur_pos;while ((cur_pos = address.find ('.' , last_pos)) != address.npos) {append (address, last_pos, cur_pos - last_pos); append ("[.]" ); 1 ; append (address, last_pos, address.length () - last_pos); return new_address;
一个图中连通三元组的最小度数 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public :const int kInf = 0x7fffffff ;int minTrioDegree (int n, vector<vector<int >>& edges) int >> matrix (n + 1 , vector <int >(n + 1 , 0 ));vector<int > degree (n + 1 , 0 ) ;for (auto edge : edges) { 0 ]][edge[1 ]] = 1 ;1 ]][edge[0 ]] = 1 ;0 ]]++; 1 ]]++;int min_degree = kInf;int triple_degree;for (int i = 1 ; i <= n - 2 ; i++) {if (min_degree == 0 ) { break ;for (int j = i + 1 ; j <= n - 1 ; j++) {if (matrix[i][j] == 1 ) { for (int k = j + 1 ; k <= n; k++) {if (matrix[i][k] == 1 && matrix[j][k] == 1 ) { 6 ;min (min_degree, triple_degree);if (min_degree == kInf) {return -1 ;return min_degree;
最短公共超序列 题目链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 class Solution {public :string shortestCommonSupersequence (string str1, string str2) {int m = static_cast <int >(str1.size ());int n = static_cast <int >(str2.size ());int >> dp (m + 1 , vector <int >(n + 1 , 0 ));for (int i = 1 ; i <= m; i++) { for (int j = 1 ; j <= n; j++) {if (str1[i - 1 ] == str2[j - 1 ]) {1 ][j - 1 ] + 1 ;else {max (dp[i][j - 1 ], dp[i - 1 ][j]);int i = m;int j = n;while (i >= 1 && j >= 1 ) { if (str1[i - 1 ] == str2[j - 1 ]) {push_back (str1[i - 1 ]);else {if (dp[i - 1 ][j] > dp[i][j - 1 ]) { else { 0 ;0 ;for (auto iter = lcs.rbegin (); iter != lcs.rend (); iter++) { while (i < m && str1[i] != *iter) { push_back (str1[i]);while (j < n && str2[j] != *iter) { push_back (str2[j]);push_back (*iter); while (i < m) {push_back (str1[i]);while (j < n) {push_back (str2[j]);return ans;
对照题解简单打一下,加深印象
有效的括号字符串 题目简要
回溯+剪枝
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <bits/stdc++.h> using namespace std;class Solution {public :void backtrace (const string& s, int left_bracket_number, int start, bool & find_result, int bracket_diff, int wildcard_num) if (find_result || left_bracket_number < 0 || abs (bracket_diff) > wildcard_num) { return ;if (start == s.length ()) {if (left_bracket_number == 0 ) { true ;return ;switch (s[start]) {case '(' :backtrace (s, left_bracket_number + 1 , start + 1 , find_result, bracket_diff, wildcard_num);break ;case ')' :backtrace (s, left_bracket_number - 1 , start + 1 , find_result, bracket_diff, wildcard_num);break ;case '*' :backtrace (s, left_bracket_number + 1 , start + 1 , find_result, bracket_diff + 1 , wildcard_num - 1 ); backtrace (s, left_bracket_number, start + 1 , find_result, bracket_diff, wildcard_num - 1 ); backtrace (s, left_bracket_number - 1 , start + 1 , find_result, bracket_diff - 1 , wildcard_num - 1 ); break ;default :break ;bool checkValidString (string s) bool res = false ;int wildcard_num = 0 ; int left_bracket = 0 ; int right_bracket = 0 ; for (char c : s) { switch (c) {case '(' :break ;case ')' :break ;case '*' :break ;backtrace (s, 0 , 0 , res, left_bracket - right_bracket, wildcard_num);return res;
无法通过最后一个测试用例,超时
1 "*************************************************************************************************((*"
这是因为该样例太多通配符,且无法找到合法表达式,故可能情况接近3的100次方。官方动态规划
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;class Solution {public :bool checkValidString (string s) int len = s.length ();bool >> dp (len, vector <bool >(len, false )); for (int i = 0 ; i < len; i++) { if (s[i] == '*' ) {true ;for (int k = 2 ; k <= len; k++) { for (int i = 0 ; i <= len - k; i++) { int j = i + k - 1 ; if ((s[i] == '(' || s[i] == '*' ) && (s[j] == ')' || s[j] == '*' )) { if (k == 2 ) {true ;else {1 ][j - 1 ];for (int x = i; x < j && dp[i][j] == false ; x++) { 1 ][j];return dp[0 ][len - 1 ];
效率也低,但无所谓,只是用来熟悉动态规划的。
每个小孩最多能分到多少糖果 每个小孩最多能分到多少糖果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :int maximumCandies (vector<int >& candies, long long k) auto check = [&](int i) -> bool { long long sum = 0 ;for (int candy : candies) {return sum >= k;int low = 1 ;int high = *max_element (candies.begin (), candies.end ()) + 1 ;int mid;while (low < high) {2 ;if (check (mid)) {1 ; else {return low - 1 ;
不是所有题目都是动态规划。
最大平均值和的分组 最大平均值和的分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <bits/stdc++.h> using namespace std;class Solution {public :double largestSumOfAverages (vector<int > &nums, int k) int size = nums.size ();if (size <= k) { double ans = 0 ;for (int num : nums) {return ans;vector<double > prefix (size + 1 ) ; 0 ] = 0 ;for (int i = 1 ; i <= size; i++) {1 ] + nums[i - 1 ];double >> dp (size + 1 , vector <double >(k + 1 )); for (int i = 1 ; i <= size; i++) { 1 ] = prefix[i] / i;for (int j = 2 ; j <= k; j++) {for (int i = j; i <= size; i++) {for (int x = j - 1 ; x < i; x++) { max (dp[i][j], dp[x][j - 1 ] + (prefix[i] - prefix[x]) / (i - x));return dp[size][k];double simple (vector<int > &nums, int k) int size = nums.size ();if (size <= k) { double ans = 0 ;for (int num : nums) {return ans;vector<double > prefix (size + 1 ) ; 0 ] = 0 ;for (int i = 1 ; i <= size; i++) {1 ] + nums[i - 1 ];vector<double > dp (size + 1 ) ; for (int i = 1 ; i <= size; i++) { for (int j = 2 ; j <= k; j++) {for (int i = size; i >= j; i--) { for (int x = j - 1 ; x < i; x++) { max (dp[i], dp[x] + (prefix[i] - prefix[x]) / (i - x));return dp[size];
动态规划有可能与前面任意一位有关,不一定是n-1位
牛客网 【2021】阿里巴巴编程题(2星) 【2021】阿里巴巴编程题(2星)
第一题 完美对
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <bits/stdc++.h> using namespace std;vector<int > Another (const vector<int >& v) {vector<int > another (v.size()) ;for (int i = 0 ; i < v.size (); i++) {return another;int main () int n, k;while (cin >> n >> k) {int >> arr (n, vector <int >(k));for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < k; j++) {int >, int > ma;for (int i = 0 ; i < n; i++) {for (int j = k - 1 ; j >= 0 ; j--) {0 ];int ans = 0 ;for (auto iter = ma.begin (); iter != ma.end (); ++iter) {if (iter->second == -1 ) { continue ;auto another_iter = ma.find (Another (iter->first)); if (another_iter == iter) { 1 ) / 2 ;else if (another_iter != ma.end ()) { -1 ;
第二题 选择物品
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bits/stdc++.h> using namespace std;void dfs (vector<int >& vec, int start, int m) if (start == m) { for (int i = 0 ; i < m; i++) {" " ;else {for (int i = start; i < vec.size (); i++) {if (start == 0 || vec[i] > vec[start - 1 ]) { swap (vec[i], vec[start]);dfs (vec, start + 1 , m);swap (vec[i], vec[start]);int main () int n, m;while (cin >> n >> m) {vector<int > arr (n) ;for (int i = 0 ; i < n; i++) { 1 ;dfs (arr, 0 , m);
第三题 小强去春游
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <bits/stdc++.h> #include <new> using namespace std;int main () int T, n;for (int i = 0 ; i < T; i++) {vector<int > vec (n) ;for (int j = 0 ; j < n; j++) {sort (vec.begin (), vec.end ());if (n == 1 ) {0 ] << endl;continue ;if (n == 2 ) {1 ] << endl;continue ;int first = vec[0 ];int second = vec[1 ];int three;for (int i = 2 ; i < n; i++) {min (second + vec[0 ] + vec[i], first + vec[i] + vec[0 ] + vec[1 ] * 2 );
第四题 比例问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <bits/stdc++.h> using namespace std;int main () long long A, B, a, b; while (cin >> A >> B >> a >> b) {if (A > B * a / b) { bool find = false ;for (long long i = A; i >= 1 ; i--) { if ((i * b) % a == 0 ) {" " << i * b / a << endl;true ;break ;if (!find) { 0 << " " << 0 << endl;
第五题 小强修水渠
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <bits/stdc++.h> using namespace std;int main () int n;while (cin >> n) {int x, y;vector<long long > vec (n) ;for (int i = 0 ; i < n; i++) {sort (vec.begin (), vec.end ());long long left = 0 ; long long right = accumulate (vec.begin (), vec.end (), -n * vec[0 ]); long long min_len = left + right;for (int i = 1 ; i < n; i++) {1 ]);1 ]);min (min_len, left + right);
后面发现最小距离和是中位数的性质,直接求中位数即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <bits/stdc++.h> using namespace std;int main () int n;while (cin >> n) {int x, y;vector<long long > vec (n) ;for (int i = 0 ; i < n; i++) {sort (vec.begin (), vec.end ());long long x = (vec[n / 2 ] + vec[(n - 1 ) / 2 ]) / 2 ; int sum_len = 0 ;for (int xi : vec) {abs (x - xi);
第六题 国际交流会 最近小强主办了一场国际交流会,大家在会上以一个圆桌围坐在一起。由于大会的目的就是让不同国家的人感受一下不同的异域气息,为了更好地达到这个目的,小强希望最大化邻座两人之间的差异程度和。为此,他找到了你,希望你能给他安排一下座位,达到邻座之间的差异之和最大。
输入总共两行。
思路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std;int main () int n;while (cin >> n) {vector<int > nums (n) ;for (int i = 0 ; i < n; i++) {sort (nums.begin (), nums.end ()); vector<int > ans (n) ;for (int i = 0 ; i < n / 2 ; i++) { 2 * i] = nums[i];2 * i + 1 ] = nums[n - i - 1 ];1 ] = nums[n / 2 ]; long long diff = 0 ; for (int i = 0 ; i < n; i++) {abs (ans[i] - ans[(i + 1 ) % n]);for (int num : ans) {" " ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> using namespace std;int main () int n;while (cin >> n) {vector<int > nums (n) ;for (int i = 0 ; i < n; i++) {sort (nums.begin (), nums.end ()); vector<int > ans (n) ;int low = 0 ;int high = n - 1 ;for (int i = 0 ; i < n; i++) {if (i % 2 == 0 ) {else {long long diff = 0 ; for (int i = 0 ; i < n; i++) {abs (ans[i] - ans[(i + 1 ) % n]);for (int num : ans) {" " ;
2021】阿里巴巴编程题(4星) 2021】阿里巴巴编程题(4星)
第一题 子集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;int main () int T;for (int k = 0 ; k < T; k++) {int n, x, y;int , int >> item (n);for (int i = 0 ; i < n; i++) {for (int i = 0 ; i < n; i++) {auto cmp = [](const pair<int , int >& p1, const pair<int , int >& p2) -> bool { return p1.first < p2.first || (p1.first == p2.first && p1.second > p2.second); };sort (item.begin (), item.end (), cmp); vector<int > dp (n, 1 ) ; for (int i = 1 ; i < n; i++) {for (int j = 0 ; j < i; j++) {if (item[i].second > item[j].second) { max (dp[i], dp[j] + 1 );int ans = *max_element (dp.begin (), dp.end ());
超时,过不了,只能使用二分查找解法了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <bits/stdc++.h> using namespace std;int main () int T;for (int k = 0 ; k < T; k++) {int n, x, y;int , int >> item (n);for (int i = 0 ; i < n; i++) {for (int i = 0 ; i < n; i++) {auto cmp = [](const pair<int , int >& p1, const pair<int , int >& p2) -> bool { return p1.first < p2.first || (p1.first == p2.first && p1.second > p2.second); };sort (item.begin (), item.end (), cmp); int piles = 0 ; for (int i = 0 ; i < n; i++) {int left = 0 ;int right = piles;int poker = item[i].second; while (left < right) {int mid = (left + right) / 2 ;if (item[mid].second >= poker) {else {1 ;if (left == piles) {
第二题 小强爱数学 但表达式的组成元素类型全部为int,故仍然会发生溢出 。
1 2 int A,B;long long x = A * A - 2 * B;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <bits/stdc++.h> using namespace std;const int kMod = 1e9 + 7 ;using ll = long long ;int main () int T;for (int k = 0 ; k < T; k++) {vector<ll> dp (n + 3 ) ;0 ] = 2 ;1 ] = A;for (int i = 2 ; i <= n; i++) { 1 ] * A % kMod - dp[i - 2 ] * B % kMod + kMod) % kMod;