汇总博客:MIT6.824 2022
推荐博客:如何的才能更好地学习 MIT6.824 分布式系统课程? SOFAJRaft 日志复制 - pipeline 实现剖析 | SOFAJRaft 实现原理 raft在处理用户请求超时的时候,如何避免重试的请求被多次应用? 一致性模型与共识算法
lab3总体来说比lab2简单很多(至少通过一次全部测试简单很多),简单记录一下实验中遇到的问题。
3A step 1:通过TestBasic3A测试
1 2 3 4 5 6 7 Clerk.PutAppend
step2:处理失败与重复执行问题
1 2 3 4 5 6 7 8 9 Clerk.PutAppend
client在接收到RPC回复leader错误/超时错误后尝试其他server。
One way to do this is for the server to detect that it has lost leadership, by noticing that a different request has appeared at the index returned by Start(), or that Raft’s term has changed. If the ex-leader is partitioned by itself, it won’t know about new leaders; but any client in the same partition won’t be able to talk to a new leader either, so it’s OK in this case for the server and client to wait indefinitely until the partition heals.
wait indefinitely 的前提条件是ex-leader被置于一个分区,且 client也无法与其他server通信。
重复执行问题与及时释放内存实际上可以一起实现,最关键是理解It’s OK to assume that a client will make only one call into a Clerk at a time.的含义。我将它理解成raft已提交日志中一旦出现新的请求,旧的请求结果就不用保存了,重复执行策略只针对一段时间重复出现的请求。
1 2 3 4 commit log只可能出现0 0 0 1 0 0 1 0
client相关的数据结构见raft在处理用户请求超时的时候,如何避免重试的请求被多次应用? ,不过由于client的make only one call前提,就不需要最大成功回复的proposal的序列号了。
1 2 3 4 5 6 type ReqResult struct { int64 string map [int64 ]ReqResult
使用一个map数据结构存放各个客户端最新请求的执行结果,如果接收raft消息后发现相应SequenceNum等于cache的SequenceNum,就不再执行该请求;如果大于则执行相应请求,此时也相当于释放了之前请求结果的内存。
3B 这部分需要回答两个问题:在什么时候检查raftstate大小并生成快照?快照中需要包含什么数据?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func (rf *Raft) int , snapshot []byte ) {defer rf.mu.Unlock()if index <= rf.lastIncludedIndex { "server%v no use snapshot.this index:%v last index:%v\n" , rf.me, rf.lastIncludedIndex, index)return append ([]logEntry{}, rf.log[index-rf.lastIncludedIndex:]...)0 ].Term
在3B测试中打印了一堆no use snapshot,并且两个索引一模一样,故记录上次生成快照时的索引大小,仅仅在commit index大于lastSnapshotIndex时才生成快照。
1 if kv.persister.RaftStateSize() > kv.snapshotThreshold && kv.commitIndex > kv.lastSnapshotIndex
由此又考虑了另外一个问题,快照只能减小由commit log带来的空间开销,如果log中的日志全部为未提交,那么再怎么生成快照也没用。所以存在一种可能,不断进入的client请求可以让raftstate超过maxraftstate,故我在900时就开始生成快照(max是1000),并且在请求加入时判断当前raftstate是否超过maxraftstate,如果超过就等待。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for !kv.killed() {if !isLogFull && isLeader {break if !isLeader {return if isLogFull && time.Since(requestBegin) > TimeoutThreshold {return
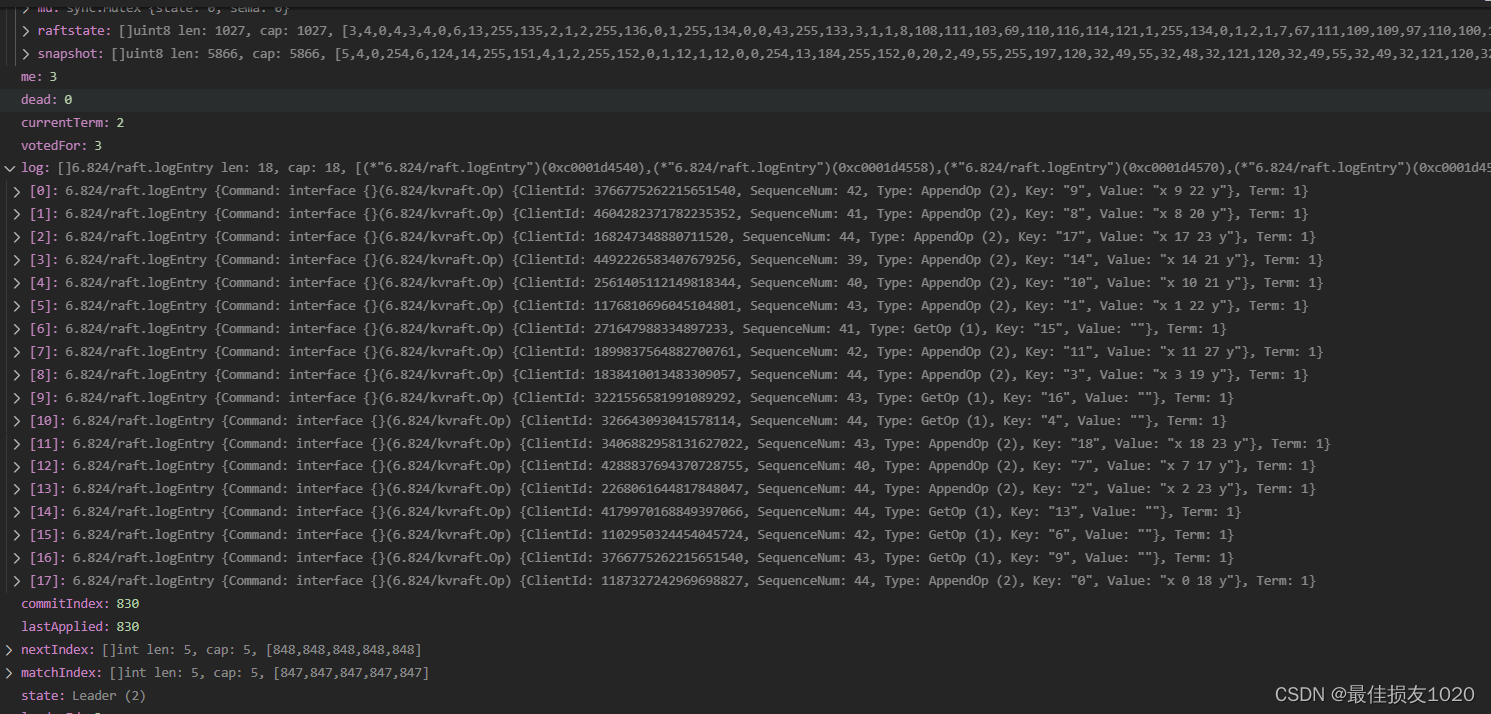
但运行TestPersistConcurrent3A测试卡死了,查看状态后发现leader处于如下状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (cfg *config) int {0 for i := 0 ; i < cfg.n; i++ {if n > logsize {return logsizeif maxraftstate > 0 {if sz > 8 *maxraftstate {"logs were not trimmed (%v > 8*%v)" , sz, maxraftstate)
三:为了避免重复执行请求,在生成快照时需要将client cache编码进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (kv *KVServer) for !kv.killed() {if kv.persister.RaftStateSize() > kv.maxraftstate && kv.commitIndex > kv.lastSnapshotIndex {new (bytes.Buffer)
在整个实验中我都没有用到term,只用了commit index。
复用RPC回复警告
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Test: one client (3 A) ...default variable/field Err may not work15.1 5 7809 722 for i := 0 ; ; i = (i + 1 ) % ck.serverNumber {"KVServer.Get" , &args, &reply)for i := 0 ; ; i = (i + 1 ) % ck.serverNumber {"KVServer.Get" , &args, &reply)"labgob warning: Decoding into a non-default variable/field %v may not work\n" ,
实验结果与speed问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 go test in majority (3A) ...in minority (3A) ...local server snapshot is newer. server id :5 lastIncludedIndex:3484 log len:1local server snapshot is newer. server id :5 lastIncludedIndex:3484 log len:1local server snapshot is newer. server id :5 lastIncludedIndex:3484 log len:1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 go test -racein majority (3A) ...in minority (3A) ...local server snapshot is newer. server id :1 lastIncludedIndex:398 log len:13local server snapshot is newer. server id :4 lastIncludedIndex:1004 log len:15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 for i in {1..10000}; do go test -run TestSpeed3A -race; done
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 for i in {1..10}; do go test -run TestSpeed3A; done
不知道为什么,-race对TestSpeed3A测试影响很大,不加-race就是11s左右,加了-race选项就是25~30s,有时候也能跑到35s,不过正式测试也不加race,也就无所谓了。
参考代码 我一直试图使用select实现超时处理,但使用select就意味着需要使用通道传递返回信息,但如果为每一个请求创建一个通道,如何及时释放这些空间又是一个问题,没想到非常好的解决方案,就还是使用轮询的老方法。
client.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 type Clerk struct {int int64 int64 int func nrand () int64 {int64 (1 ) << 62 )return xfunc MakeClerk (servers []*labrpc.ClientEnd) new (Clerk)len (servers)1 return ckfunc (ck *Clerk) string ) string {1 )}for {for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ { "KVServer.Get" , &args, &reply)if ok && reply.Status == ErrNoKey {return "" if ok && reply.Status == OK {return reply.Value100 * time.Millisecond)func (ck *Clerk) string , value string , op string ) {1 )}for {for i := ck.lastLeader; i < ck.lastLeader+ck.serverNumber; i++ { "KVServer.PutAppend" , &args, &reply)if ok && reply.Status == OK {return 100 * time.Millisecond)func (ck *Clerk) string , value string ) {"Put" )func (ck *Clerk) string , value string ) {"Append" )
common.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 const ( "OK" "ErrNoKey" "ErrWrongLeader" "ErrTimeout" "ErrOldRequest" "ErrLogFull" type Err string type ReqResult struct { int64 string type PutAppendArgs struct {string string string int64 int64 type PutAppendReply struct {type GetArgs struct {string int64 int64 type GetReply struct {string
server.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 const Debug = true func DPrintf (format string , a ...interface {}) int , err error ) {if Debug {return const (10 * time.Millisecond 200 * time.Millisecond 100 * time.Millisecond type KVServer struct {int chan raft.ApplyMsgint32 int map [string ]string map [int64 ]ReqResult int int func (kv *KVServer) if !isLeader { return for {false if cache.SequenceNum < args.SequenceNum { if kv.commitIndex >= index { true else if time.Since(requestBegin) > TimeoutThreshold { true else if cache.SequenceNum == args.SequenceNum { true else if cache.SequenceNum > args.SequenceNum {true if outCycle {return func (kv *KVServer) if !isLeader {return for {false if cache.SequenceNum < args.SequenceNum { if kv.commitIndex >= index { true else if time.Since(requestBegin) > TimeoutThreshold { true else if cache.SequenceNum == args.SequenceNum { true else if cache.SequenceNum > args.SequenceNum {true if outCycle {return func (kv *KVServer) 1 )func (kv *KVServer) bool {return z == 1 func (kv *KVServer) for !kv.killed() {if msg.CommandValid { switch data := msg.Command.(type ) {case GetArgs:if cache.SequenceNum < data.SequenceNum { if !ok { else {case PutAppendArgs:if cache.SequenceNum < data.SequenceNum { if data.Op == "Put" {else {else if msg.SnapshotValid { var commitIndex int var clientCache map [int64 ]ReqResultvar kvData map [string ]string if d.Decode(&commitIndex) != nil || d.Decode(&clientCache) != nil || d.Decode(&kvData) != nil {"snapshot decode error" )else {if kv.maxraftstate > 0 && kv.persister.RaftStateSize() > kv.maxraftstate && kv.commitIndex > kv.lastSnapshotIndex {new (bytes.Buffer)func StartKVServer (servers []*labrpc.ClientEnd, me int , persister *raft.Persister, maxraftstate int ) new (KVServer)make (chan raft.ApplyMsg)make (map [string ]string )map [int64 ]ReqResult{}go kv.receiveTask()return kv