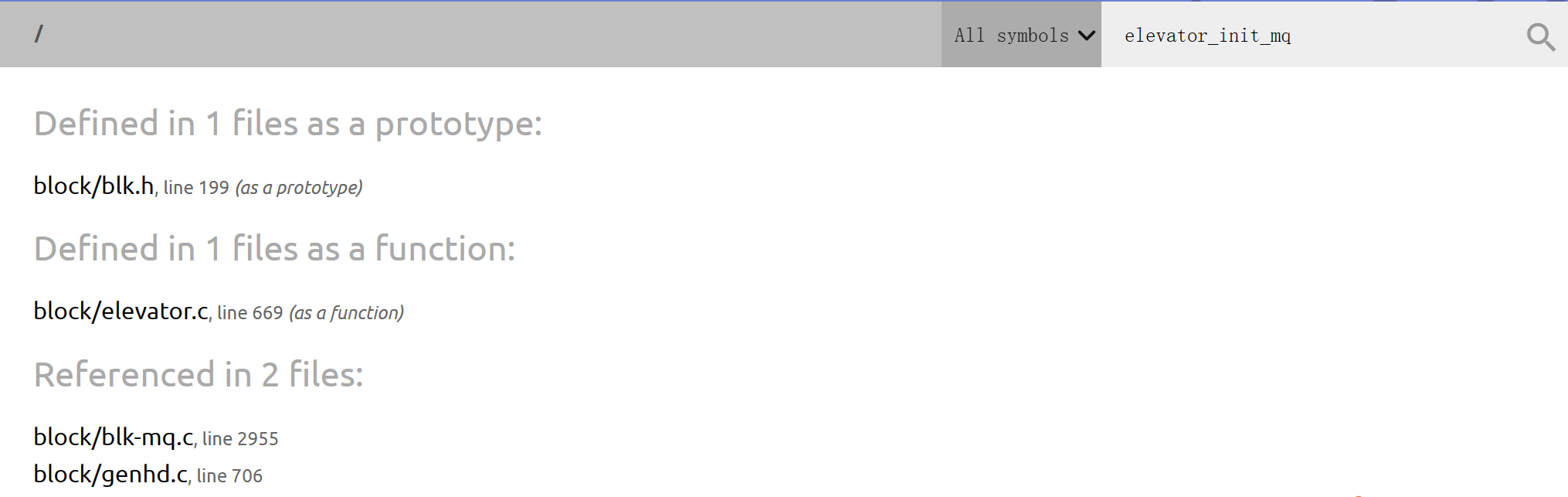
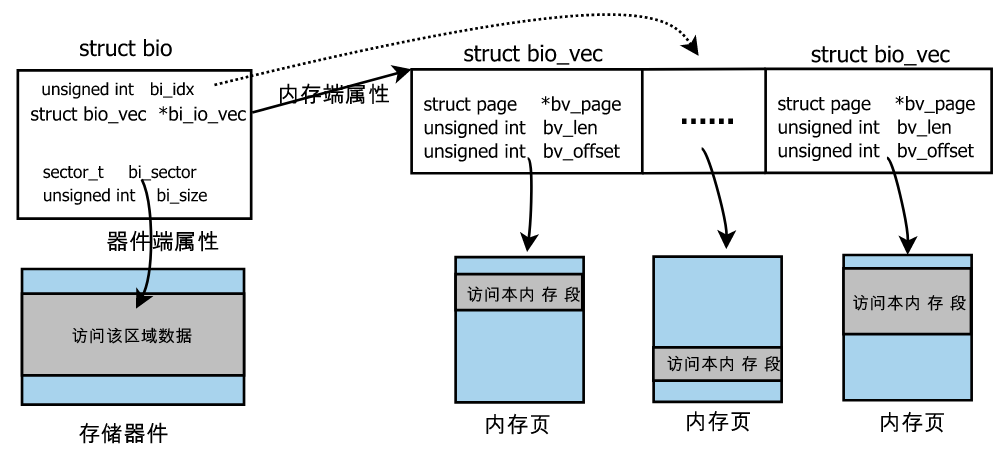
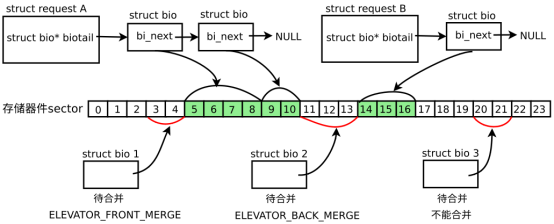
/** * blk_queue_max_segments - set max hw segments for a request for this queue * @q: the request queue for the device * @max_segments: max number of segments * * Description: * Enables a low level driver to set an upper limit on the number of * hw data segments in a request. **/ voidblk_queue_max_segments(struct request_queue *q, unsignedshort max_segments);
/** * blk_queue_virt_boundary - set boundary rules for bio merging * @q: the request queue for the device * @mask: the memory boundary mask **/ voidblk_queue_virt_boundary(struct request_queue *q, unsignedlong mask);
/** * blk_queue_write_cache - configure queue's write cache * @q: the request queue for the device * @wc: write back cache on or off * @fua: device supports FUA writes, if true * * Tell the block layer about the write cache of @q. */ voidblk_queue_write_cache(struct request_queue *q, bool wc, bool fua);
驱动设置前后成员值对比
1 2 3 4 5 6 7 8 9 10 11
PRINT_INFO("before: max sector:%d max seg:%d mask:%d", queue_max_sectors(xxx_dev->queue), queue_max_segments(xxx_dev->queue), queue_virt_boundary(xxx_dev->queue)); blk_queue_max_hw_sectors(xxx_dev->queue, (1 << 20) / (1 << 9)); // 最大1M数据 blk_queue_max_segments(xxx_dev->queue, 127); blk_queue_virt_boundary(xxx_dev->queue, 4096 - 1); blk_queue_write_cache(xxx_dev->queue, 0, 0); PRINT_INFO("after: max sector:%d max seg:%d mask:%d", queue_max_sectors(xxx_dev->queue), queue_max_segments(xxx_dev->queue), queue_virt_boundary(xxx_dev->queue));
[ +0.000073] before: max sector:255 max seg:128 mask:0 [ +0.000002] after: max sector:2048 max seg:127 mask:4095
/* * Returns true if we did some work AND can potentially do more. */ boolblk_mq_dispatch_rq_list(struct request_queue *q, struct list_head *list, bool got_budget) { structblk_mq_hw_ctx *hctx; structrequest *rq, *nxt;
/* * Now process all the entries, sending them to the driver. */ do { structblk_mq_queue_databd;
/* * Flag last if we have no more requests, or if we have more * but can't assign a driver tag to it. */ if (list_empty(list)) bd.last = true; else { nxt = list_first_entry(list, struct request, queuelist); bd.last = !blk_mq_get_driver_tag(nxt); }
ret = q->mq_ops->queue_rq(hctx, &bd); // 调用驱动定义的queue_rq函数
// 看到注释中的scsi很奇怪 /* * Only SCSI implements .get_budget and .put_budget, and SCSI restarts * its queue by itself in its completion handler, so we don't need to * restart queue if .get_budget() fails to get the budget. * * Returns -EAGAIN if hctx->dispatch was found non-empty and run_work has to * be run again. This is necessary to avoid starving flushes. */ staticintblk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx) { structrequest_queue *q = hctx->queue; structelevator_queue *e = q->elevator; LIST_HEAD(rq_list);
do { structrequest *rq;
if (e->type->ops.has_work && !e->type->ops.has_work(hctx)) break;
rq = e->type->ops.dispatch_request(hctx);
/* * Now this rq owns the budget which has to be released * if this rq won't be queued to driver via .queue_rq() * in blk_mq_dispatch_rq_list(). */ list_add(&rq->queuelist, &rq_list); } while (blk_mq_dispatch_rq_list(q, &rq_list, true));
/* * blk_mq_sched_insert_requests() is called from flush plug * context only, and hold one usage counter to prevent queue * from being released. */ percpu_ref_get(&q->q_usage_counter);
e = hctx->queue->elevator; if (e && e->type->ops.insert_requests) e->type->ops.insert_requests(hctx, list, false); else { /* * try to issue requests directly if the hw queue isn't * busy in case of 'none' scheduler, and this way may save * us one extra enqueue & dequeue to sw queue. */ if (!hctx->dispatch_busy && !e && !run_queue_async) { blk_mq_try_issue_list_directly(hctx, list); // nvme驱动 if (list_empty(list)) goto out; } blk_mq_insert_requests(hctx, ctx, list); }
/* * Initialize the queue without an elevator. device_add_disk() will do * the initialization. */ q = blk_mq_init_allocated_queue(set, uninit_q, false);
/** * __device_add_disk - add disk information to kernel list * @parent: parent device for the disk * @disk: per-device partitioning information * @groups: Additional per-device sysfs groups * @register_queue: register the queue if set to true * * This function registers the partitioning information in @disk * with the kernel. * * FIXME: error handling */ staticvoid __device_add_disk(struct device *parent, struct gendisk *disk, conststruct attribute_group **groups, bool register_queue) {
/* * The disk queue should now be all set with enough information about * the device for the elevator code to pick an adequate default * elevator if one is needed, that is, for devices requesting queue * registration. */ if (register_queue) elevator_init_mq(disk->queue); }
/* * For a device queue that has no required features, use the default elevator * settings. Otherwise, use the first elevator available matching the required * features. If no suitable elevator is find or if the chosen elevator * initialization fails, fall back to the "none" elevator (no elevator). */ voidelevator_init_mq(struct request_queue *q) { structelevator_type *e;
if (!elv_support_iosched(q)) return;
if (unlikely(q->elevator)) return;
if (!q->required_elevator_features) e = elevator_get_default(q); else e = elevator_get_by_features(q); }
/* * For single queue devices, default to using mq-deadline. If we have multiple * queues or mq-deadline is not available, default to "none". */ staticstruct elevator_type *elevator_get_default(struct request_queue *q) { if (q->nr_hw_queues != 1) returnNULL;
41/* 42 * These can be higher, but we need to ensure that any command doesn't 43 * require an sg allocation that needs more than a page of data. 44 */ 45#define NVME_MAX_KB_SZ 4096 46#define NVME_MAX_SEGS 127
那么这个参数的含义又是什么呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
staticinlineunsignedshortqueue_max_segments(conststruct request_queue *q) { return q->limits.max_segments; } // 影响bio bi_vcnt(即bvec数目) if (bio->bi_vcnt >= queue_max_segments(q)) // 影响nr_phys_segments参数大小 if (rq->nr_phys_segments > queue_max_segments(q)) { printk(KERN_ERR "%s: over max segments limit. (%hu > %hu)\n", __func__, rq->nr_phys_segments, queue_max_segments(q)); return BLK_STS_IOERR; }
/* * Number of scatter-gather DMA addr+len pairs after * physical address coalescing is performed. */ unsignedshort nr_phys_segments;
/* * We should not need to do this, but we're still using this to * ensure we can drain requests on a dying queue. */ if (unlikely(!test_bit(NVMEQ_ENABLED, &nvmeq->flags))) return BLK_STS_IOERR;
ret = nvme_setup_cmd(ns, req, &cmnd); if (ret) return ret;
if (blk_rq_nr_phys_segments(req)) { ret = nvme_map_data(dev, req, &cmnd); if (ret) goto out_free_cmd; }
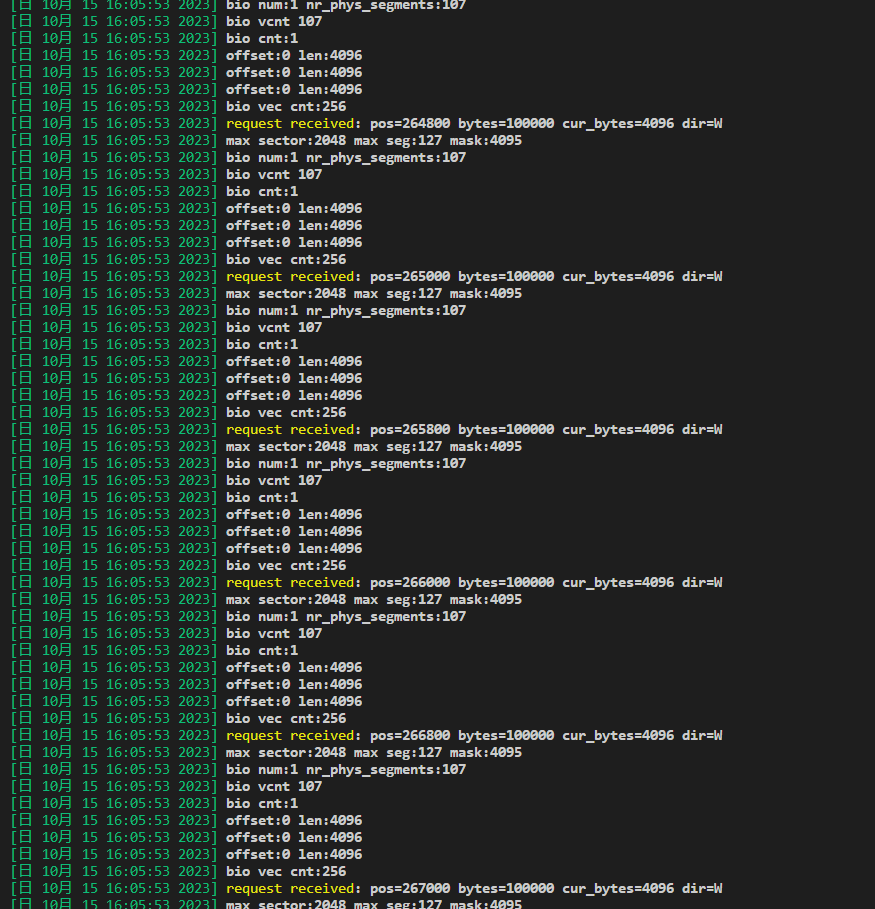
if (blk_integrity_rq(req)) { ret = nvme_map_metadata(dev, req, &cmnd); if (ret) goto out_unmap_data; } printk(KERN_WARNING "request received: pos=%llx bytes=%x " "cur_bytes=%u dir=%c\n", (unsignedlonglong)blk_rq_pos(req), blk_rq_bytes(req), blk_rq_cur_bytes(req), rq_data_dir(req) ? 'W' : 'R');