本文最后更新于:3 天前
写在前面 本篇技术博客大部分都是碎碎念、思路、方法论、片段、随笔、备忘录,没有什么条理,某种程度上只有我能看懂全部含义,这也是我工作写个人文档的风格,从来没有条理,意识流
现在没啥精力写一些非常有条理的博客,参考莱姆狂想曲,没时间写书,直接假设书写出来了,直接写书评
之所以写这个主要是觉得写在个人网站上比较有动力继续写下去,和假想中的读者对话,而且个人网站比较自由,想写啥就写啥
希望你们看完能有所收获,实际上我不信能有什么收获╰( ̄▽ ̄)╭
漫谈/随笔
随便打打字,生活 > 工作
AI工作流
问题、需求——人——AI——代码的关系是什么?
如何对抗模型幻觉
如何描述需求
哪些需求是我们未能说出来的
需求与具体实现之间的差距
我们的判断是否一定对
如何让AI成为一个可靠的评审者、讨论者而不仅仅是附和
AI的讨好倾向
当我们在让AI生成测试代码时,我们想要测什么?
持续地工作流优化、反馈、迭代
持续地提升自身能力
模型的上限在哪
通用的实现与特化的实现
模型永远推导不出什么
如何能跳过非必要的工作,只进行这些工作
我们如何才能对写出代码有掌控力
自然语言真的能成为下一代编程语言吗? 它是否完备,是否存在二义性,如何能让不同模型在相同语言下得到一致的结果,追求生成物的稳定性是否是一种偏执
AI在捏造结果、假装完成方面很有经验,所以需要有辨别能力,当AI给出结论时,需要看它的推导过程是否足以推导出这个结论,是否片面,增加自我反思的skills还是必要的。AI没有自驱力,也就是说它不会自己提出需求,毕竟它只是在做字词接龙,如果开头都没有,也就没有后续。所以用AI查问题原因存在一个悖论,假如我知道怎么查,就不需要AI了,或者是AI可以按照我的思路查,但实际上我花时间查也可以查出来;假如我不知道怎么查(不知道查的具体方法、思路),AI转圈也不怎么能转出来。所以,需要有一个起点,这个起点是否一定需要人来提出,或者说可以通过其他方式来闭环,如何产生更多的创造性而不是局限于通用范式
如何使用AI来启发人的解题思路,理清问题,找到问题就找到了答案。
提一个好问题——写完这段字我在多抓鱼打算买一本关于问题、提问的书,刚想买《学会提问》这本书,提示我已经买过了,我买的好多书都没拆封啊,幸亏没再买一遍。
如何能让AI在聚焦问题前帮助人,并不是澄清需求,而是更前面的部分,这件事需不需要做,从更高层面有没有其他更好的方案,有可能问题研究了半天,但实际上换一个思路,只需要改动很小的部分就可以完成。 有些时候需要看一看抽离出来,而不是一股脑研究问题
AI记忆的管理,每一次都是新的AI太气人了,保存上下文与恢复上下文,这两个流程如何更加简单、更加细粒度
实际上在元任务、元问题上花更多时间可以更好地提升效率,也就是那些看似与当前具体问题关系不大,但可能之后回顾、后续问题用得到的部分,定期的总结归纳,磨刀不误砍柴工,过于聚焦具体的问题最终有可能发现做无用功
以上这些我们都不会讨论(๑◡ ๑)
AI工作流/AI协作方法——偷懒是行不通的
上班的时候挂着这篇博客提醒自己
欲速则不达
在使用AI时,必须抱着花比古法编程更多的时间、精力的预期来进行任务开发,这样就会发现AI可以很多流程上可以方便。如果想着在各个步骤上让AI自由发挥,那到最后就是一次一次的返工。所以,一开始就打算全链路自己搞,而后一步一步放开,这样才比较好
当你都不确定在AI能不能在信息量极少的情况下做对,此时AI大概率会做错,所以需要尽可能把需求明确、背景明确,把知道的全部告诉给AI,这样它才可能给出一个好的结果
有了AI之后最大的问题就是之前偷懒,最终啥成果没有;现在偷懒,总能得到点看起来挺像回事的东西,但实际上这个和认真写的天差地别。
用“AI写的”这句话推卸责任并没有意义
迷信AI,对AI生成的东西没有什么了解,此时要求AI生成一个符合预期的东西是不合理的,因为连你自己都不知道要干啥,更不能指望AI知道。在某些角度,AI只能比你自己做的更差,因为你有一些隐含的信息没有告诉它,而它只能知道一些通用的、泛化的东西,如果当前项目恰好是这些通用的部分倒还好
好的IDE(agent框架)、好的模型事半功倍
我是保守派(守旧派),一旦用习惯一个工具就懒得换了,所以我的工具迁移非常慢,而且我不怎么习惯CLI,vim一直都不怎么会用、mac里的一堆快捷键也没怎么用过、我是鼠标爱好者、UI爱好者,甚至实习的时候mac实在用不习惯,把mac又换成了windows,只是window的续航比较差,正式入职的时候还是选择用mac了。
我的编程工具刚开始是古法vscode;后面是vscode + 灵码,但感觉灵码不怎么好用;再后面是cursor,这个时候发现cursor太好用了,以至于其他工具都不怎么尝试了;后面开始用qoder,虽然有一系列的bug,但用着用着也就习惯了;中间claude code用了几次,CLI不太习惯就没继续用下去,免费的opus也没用;openclaw在比较火的时刻部署了一个,但不知道用来干什么,也就不用了。
最近要开始搞测试AI化,接了一个钉钉机器人,打算从0开始写agent框架(无知的我),刚写完钉钉stream接入、意图识别、工具执行、llm层后发现要接skills,这个时候就不知道咋搞了,感觉工作量太大了,后面问了问可以用agentscope,总感觉比较费劲。问一问其他团队的人,直接用openclaw+简单的配置文件、完全不需要写代码就可以搭建一个看起来比较智能的机器人,所以重复造轮子真的是浪费时间的,抄现成的比较好。最近发现在内网ATA上写文章也没啥人,所以不如直接在个人网站上编一编我的AI水文,但公司qoder在个人电脑上装不了(收费等于装不了),装了个claude code,用起来也非常好用,而且感觉功能很强大,悔不当初,早点用就好了,之前还有免费opus模型可以用呢。因此,还是需要乐于尝试新的工具、学习它到底解决了什么问题,解决问题的思路是什么?方法是什么?即使不使用这些工具也可以借鉴这些思路、方法。
TODO:
openclaw、claude code、hermes agent、codex、opus/gpt模型订阅
多尝试、多用用CLI、mac快捷键、少用鼠标(可以强制不用鼠标,强制使用键盘与触摸板)、提升效率
原来vscode已经有claude code插件了,之前听说过,但一直没用
影响效率的一些强迫症,这些强迫症都要一个一个克服
红点强迫症:看到新消息提示一定要点进去,即使看到了消息是什么,也要把红点消掉——每天都要留一些消息一直不点,这样就能习惯有消息一直挂着了
进度查看强迫症 :总是喜欢看一看AI的思考过程是啥,即使也没怎么认真看,单纯打发时间,而且时不时就要看一看AI执行完了没,我接下来要干啥取决于AI转完没,而不是我打算干嘛,所以CLI的好处就是避免我一直盯着看了,开一个tmux + claude code,让它一直转就行。—— 把人工参与的部分尽可能一次性做完,而后过一段时间再来收菜,不再一直看AI思考、转圈
IDE的问题
qoder:时不时就弹窗,检测到潜在风险(一般是删文件),一直让我点是是是,即使我已经明确告知这些操作全部允许,仍然一直跳出,某种程度上这也是一种推卸责任,或者说技术的不自信。
qoder:如果连接远程主机使用quest模式,等电脑断网后重连,quest模式就会卡主,需要重新打开才能继续执行之前的任务,UI一直卡柱,太憨的bug了(UI模式问题确实太多了)
AI工作流
我使用AI的过程大概是:
(1)手工提示词阶段:开头第一句,你是一个xxx的专家,然后接具体的需求
(2)模版提示词阶段:使用CRISP的模板,写上下文、角色、指令什么的,但实际上一般都偷懒不写
(3)使用热门的skills:例如grill-me、brainstorming什么的,省的自己写提示词
(4)工作流:当进行各个场景时,使用的skills组合都类似,所以使用rules或其他什么机制,把相关skills串联起来,省的手打和记录,同时也可以持续地提升这个场景的处理效率。例如新功能开发的skills组合为grill-me明确需求 —》 brainstorming 探讨如何设计 —》 writing-plans编写计划 —》 tdd编写测试用例 —》代码实现 —》code-review代码评审 —》verification验证
个人AI工作流的构建
AI工作流需要一个载体来承载使用工作流遇到的问题、反馈与优化,我目前的方法是新建一个ai-playbook仓库,存放一些常用的skills、rules、各个场景的skills编排规则、使用日志、相关博客、文章、经验文档、知识库、一些通用的和一些项目相关、安装脚本,便于直接安装到其他项目中去
一般情况下,使用的方法就是在新项目中下载ai-playbook仓库,安装skills和rules,使用工作流完成功能开发/问题定位后,把使用中的问题、经验、对ai-playbook仓库的反馈优化都整合到仓库里,完成工作流的持续优化循环,不过这个是内网仓库,无法搬到这里来,不过都是AI写的,所以在后面我阐述一下工作流构建的思路
在工作流场景中存在五个对象
待解决的问题,无论是功能开发、问题定位、文档编写
AI
自己
最终产物
工作流
事件优先级
个人能力提升
工作流的优化
问题的解决
一些常见的问题与思路
在把基本的工作流框架、各个场景的skills组合确定下来后,自然而然会遇到一系列的问题。这个时候可以让AI来发散一下,思考如何解决这些问题,同时沉淀到工作流中,避免后续再犯。同时,逐渐找到哪些问题一直在犯,但AI一直解决不了,这个时候就需要在这个阶段进行人工卡点,人来进行判断
最理想的情况就是一个工作流刚开始执行前把背景、需求全部说完,然后AI转几圈,结果全部正确,但这是不可能的。中间一定需要人工介入,例如spec与具体实现完全不是一一对应的关系,当你真实看到代码时才会发现“哦,原来我之前忘说了,我更想要那样的实现”。
AI测试没有太多的价值,AI生成代码,跑单元测试都是全PASS,然后在真实场景下一跑就全是失败,可以考虑加一点对抗性评审、破坏性测试、集成测试、实际环境测试的skills,但更重要的还是自己知道到底想要测啥功能,写测试为了验证哪个部分的功能是否完备
工作流不仅需要保证最终生成的产物正确,也需要保证它的可读性、可迭代性,保证用户本身理解了这个产物,最理想化的情况就是 用户对AI写的了解 >= 自己手写的,需要尽可能做到这一点。例如代码都增加中英文的注释、生成一系列的介绍文档、增加代码阅读的skills,让AI监督你学习代码
时不时看一看工作流仓库的相关skills与经验,熟悉它的使用,思考如何优化,最近AI使用过程中遇到了哪些问题,并定期从热门社区copy一些比较好的skills过来
功能开发工作流
需求澄清 grill-me
方案探索 brainstorming
反驳设计方案 self-critique
生成PRD to-prd
生成spec to-spec
生成实施计划 writing-plans
可观测性设计(设计日志、指标、告警等)便于后续调试
测试驱动实现 tdd
对抗测试强化
实现反驳
人工评审
反馈迭代循环
最终代码评审
最终验证与归档
初始工作流如上
驾驭猜字机器
AI水文系列
本来在内网写的系列博客(全部用AI生成的),但也没啥浏览量,不如在个人网站写一写算了,内网文章不能搬过来,只能把已经写的几篇内网文章总结一下写点概要了,之后把后面还没写的部分认真写一写发到这里来
从不确定性到确定性
这篇文章基于我最开始的一个疑问,为什么预测下一个token这种简单的能力可以演化出这么多优秀的智能体,预测下一个token本身也是一个概率计算,存在不确定性,为什么可以基于底层的不确定性构建成“稳定”的智能。 从这个点开始,让AI转圈,转出了这篇文章
(以下全部为AI观点)
Transformer:整个Transformer就是一条流水线,token进去,经过几十上百层注意力处理,最后输出“下一个token是什么”的概率分布。
预训练:用海量文本训练模型在给定前置文本的情况下预测下一个token
监督微调:学会对话格式
RLHF:符合人类偏好
一些观点:
预测token越准,证明内部的语言模型越精确
预测就是压缩,压缩则必须理解
压缩率就是衡量“理解深度”的数学度量
语言中各个词并不是均等分布的,所以高频词非常少,所以预测下一个词并没有想象中的难
于此,假设给定一句话,预测下一个词是很简单的,此时假定大模型内部通过几亿个参数已经把语言的内部机制给构造出来了
我的理解:但它内部并没有进行逻辑运算,它只是在预测, 所以当输入1+1= 多少时,模型并不是在计算1+1等于多少,而是由于之前训练文本中大部分1+1=后面接着的都是2,所以输出2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 "预测下一个 token" :大模型本质上是一个巨大的概率分布预测器,给定前面的文本,预测最可能出现的下一个 token。"算术模块" 在做加法运算。1. 不仅仅是"记忆统计" "训练数据里 1+1= 后面大多跟着 2,所以输出 2" ——这暗示模型只是在做简单的频率统计/查表。实际上模型学到的是远比拼写记忆复杂得多的模式:"计算" ,但也不是简单的"背诵" 2. 模型能处理没见过的组合3847 +5926 =)。但实际上模型对中小规模的算术有一定泛化能力,说明它学到了某种近似算法的内在结构,而不仅仅是记忆。3. 大数计算会暴露局限"真正的计算" (否则不会算错)4. "逻辑运算" 的定义问题"按步骤推导的逻辑运算" 。模型的"推理" 更像是模式匹配 +1 +1 =?,它不是在像计算器那样执行加法算法,而是基于训练过程中学到的数字模式和算术规律,生成最可能的答案。对于简单的算术"模式匹配" 方式就会频繁出错——这也是为什么现在通常需要给模型配备外部工具(如计算器、代码解释器)来处理精确计算。
我的理解:为什么提示词有用? 这更多与之前训练提供的文本有关,当你提供的有效前置信息越多,对应训练文本的优质回答越多,得到优质答案的可能性越大。假如你给出的信息有限,或者很多无用信息,那么大模型的答案就会呈现不确定性。大模型也只是在猜,只是一直模仿回答,它并没有自己的思想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 这个表述部分正确,但有几处值得深入辨析:"提供的有效前置信息越多,得到优质答案的可能性越大" "匹配训练文本" 更深一层:"检索" 而非"匹配" "信息有限或无用信息多,答案呈现不确定性" "猜" ,输出方差增大"大模型也只是在猜" ——这个"猜" 字过于简化"猜" 暗示的是随机猜测,但模型的预测是基于数千亿参数编码的复杂模式进行的高维统计推断。它和人类掷骰子的"猜" 完全不同:"猜" ,不如说是基于模式的高维插值。"只是一直模仿回答" ——模仿的层次很丰富"文本表面形式" ,还包括:"先分析再结论" 的论证模式"如果A则B" 的推导模式"作为专家应该关注什么" 的思维框架"理解" 之间的界限变得模糊。这也是学术界至今争论的问题。"没有自己的思想" ——取决于如何定义"思想" "思想" 指的是:"特征" (features),对应真实世界的概念"模仿" 或"猜测" 复杂——它能在一定程度上进行泛化和结构化推理,只是这种能力的可靠性
我的理解:有了可以支持单次对话的大模型还不够,我们需要使用上下文累积 + 循环 + 工具 + 反馈校验的方式来让结果一次一次逼近我们的预期值,单次大模型结果可能会犯错,多次控制反馈后结果趋于稳定,之所以智能体在编程上爆发的原因就是它可以通过编译、运行来快速知道模型结果是否真的符合预期还是幻觉。
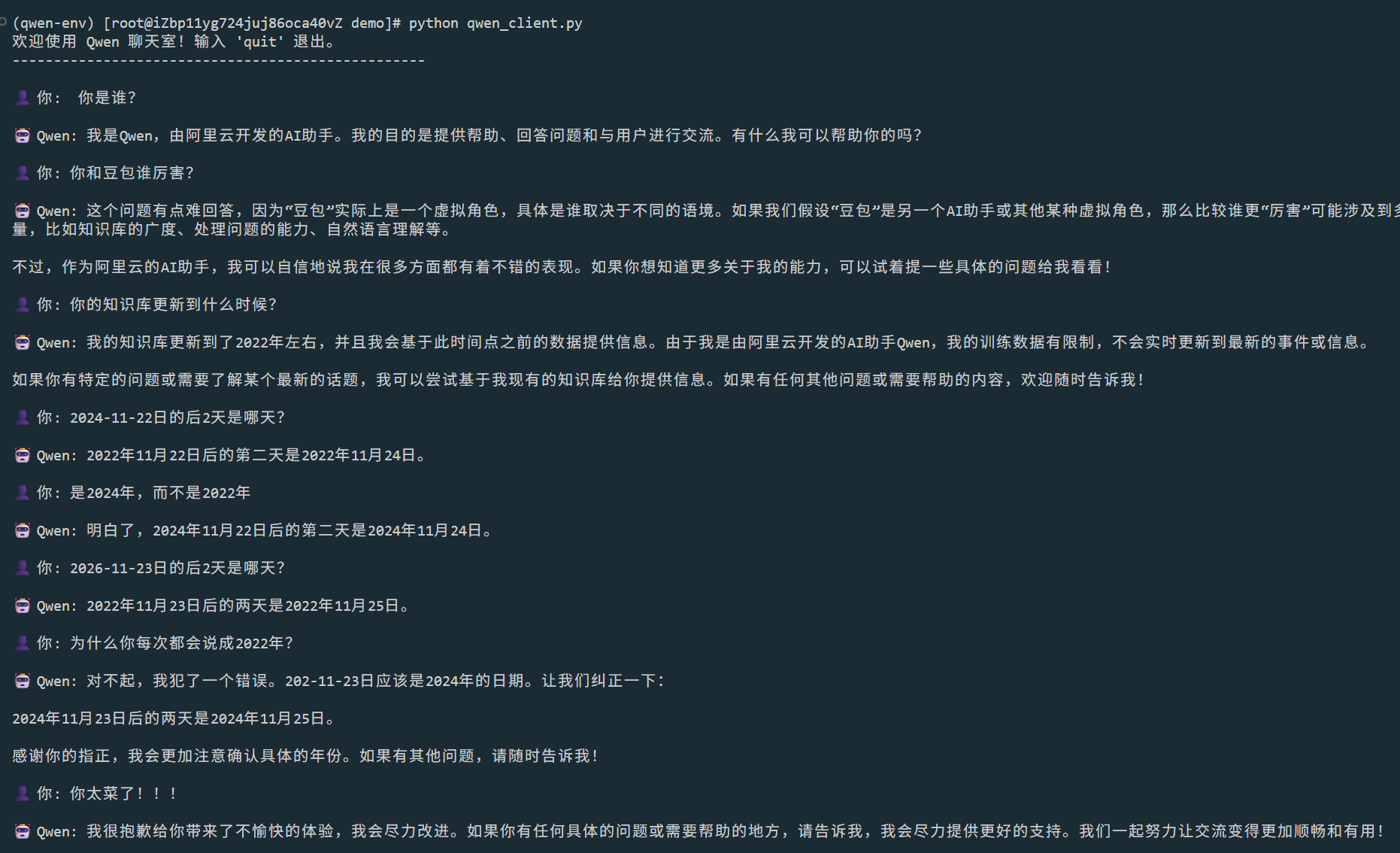
AI的讨好倾向,写什么它都会说你太对了!这估计和训练时人对夸奖类的回答打分高,导致它学会天天讨好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 这段表述整体质量很高,抓住了 Agent 系统的核心思想,但有几处可以更精确:"单次大模型结果可能会犯错,多次控制反馈后结果趋于稳定" "通过编译、运行来快速知道模型结果是否真的符合预期还是幻觉" "越多越好" ,还有策略问题"无用信息" 问题)"试过什么、为什么失败" ,避免循环"加法" ,而是有策略的策展。"帮助验证" ,更重要的是让模型突破了纯文本生成的局限——从"只能说" 变成了"能做" 。这才是 Agent 区别于普通聊天机器人的本质特征。"逼近预期值" ——这个类比需要限定"逼近目标值" 假设目标值是明确且固定的。但在实际的 Agent 使用中:"控制论中的负反馈" ,不如说是控制论 + 启发式搜索 + 需求渐进澄清的混合体。
即使大模型/智能体再强,它无法知道需求、无法知道一些隐形的约束、背景、无法判断生成什么样的结果是对的、人可以不成为驱动问题、任务的角色,但一定需要成为裁决任务的角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 ● 这个观点抓住了人机协作中一个很本质的洞察,但有几个地方值得展开和辨析:"人必须成为裁决任务的角色" "通过测试" ≠"满足需求" "无法知道隐形的约束、背景" "简单功能" 背后涉及哪些政治/商业考量"无法判断生成什么样的结果是对的" ——部分可以,部分不行"技术上对不对" ,但无法判断"该不该这么做" 。后者才是人作为裁决者的核心价值。"无法知道需求" ——Agent 正在学会"澄清需求" "无法知道需求" ,这大体正确,但有一个趋势值得关注:"帮我写一个登录功能" "需要支持哪些登录方式?邮箱/手机/第三方? 是否需要多因素认证?会话超时时间是多少?" "一般登录功能需要考虑什么" 的模式匹配,而不是基于对你具体业务场景的深入理解。所以 Agent"人可以不成为驱动问题的角色" ——这一点正在快速变化"问题" 本质上是从已有模式中推断出的问题,它无法发现范式级别的新问题。例如:"这个函数有潜在的 null 指针异常" "我们的产品方向错了,应该从 toC 转向 toB" "驱动问题" ,目前仍然只能由人来完成。"裁决任务" ,而是"定义什么值得做" 和"定义什么算好" 。"裁决" 不仅是事后的"通 过/不通过" ,更包括事前的目标设定和事中的方向纠偏——这些才是人最不可被替代的能力。
系统提示词
工具使用
agent loop
色盲/色弱网站
我和更年期大妈不得不说的二三事
奇怪的色盲色弱诊断方法
炒股网站
别炒股!别炒股!别炒股!——已离开股市3个月
仅仅练手,不炒股,炒股过于耗费心神,而且亏钱。 股市改变了我的消费观,之前吃饭买衣服什么的感觉挺贵的,不值得,在股市亏完钱后,这些都不算事了,反正没股市亏的多。别炒股、别炒股、别炒股 !不过我也没亏那么多钱,只不过在股市亏的每一块钱都是不值得的,我又不搞慈善,我去股市是为了赚钱的!!!
未来生活指南
看一看前沿领域、相关领域的知识, 不炒股 ̄へ ̄
具身智能
世界模型
脑机接口
大模型到底咋训练,咋推理的? 我要新创建一个模型,我应该怎么做? 怎么获取数据、如何清洗、如何训练、如何评估、如何推理、每一次训练、推理之后留下了什么
AI相关花里胡哨的名词是啥意思
存储、计算、网络传统三大件又有什么新活
harness之后有没有啥新范式
未来我能不能活的更久一点,生物技术有没有什么新突破
自动驾驶的最新进展
飞机、航空航天、人造卫星、火星探月的实时动态(老一代航天人的殷切盼望(≖ᴗ≖)✧)
饭碗啥时候被AI一脚踢飞,我们该何去何从
我们离吃大锅饭还有多远
究竟是烧烤还是淀粉肠,职业抉择与其中的深刻考量
未来娱乐方式的可能性、可行性探讨
拓宽视野,AI还能干什么?
使用AI抓鬼、恐怖情节中增加AI元素的可行性
AI宇航员、AI与外星人
人文关怀
不知道写点啥,但应该有,推荐阅读置身钉内
博客计划/学习计划
之前以为有了AI之后, 就不怎么需要研究技术了。 现在感觉至少需要了解个大概才能知道AI有没有糊弄你,可以借助AI来学习这些知识
ceph源码阅读,了解OSS存储 KV存储 文件存储的大致链路的基本实现
nginx源码阅读,了解nginx的高性能原理
程序员的自我修养
看一看C和C++的相关书籍,可惜大部分场景只能用C,我还挺喜欢C++的
之前的部分
之前还是用古法思路写博客,但被ai击垮了,起承转合、逻辑闭环、循序渐进的范式太累了,还是写点随笔吧
在大学的时候,我一直对机器学习、人工智能之类的课程不怎么喜欢。一部分原因是授课老师讲的过于无聊,更重要的原因是ai存在明显的不确定性。当执行一段C语言代码时,再怎么样程序的功能都是可被理解的,你对于一行代码执行后会有什么样的表现拥有基本的预期,尽管存在多线程、内核抢占、编译优化、CPU乱序发射,底层硬件故障等一些不确定性,但你对它们的存在也是了解的,至少可以假装认为自己了解。但ai的执行结果就完全是个谜了,机器学习中的一系列参数的含义完全未知,为什么这个参数比较好,那个参数比较差,本身就很难彻底说明白,因此当时我们都叫搞ai的叫太白金星,整天炼丹调参。
之前的程序都是从原理上,从逻辑上,从结构上仔细地拆分,解决问题;但ai看起来是直接从结果上来解决问题。从一个强大的模型、神经网络开始,尝试解决这个问题并计算结果的准确程度,然后一直往更加准确的方向前进。但这种方式的问题是:即使ai对一个问题的准确度一直是100%,也无法确保下一次同类型问题同样正确,虽然非ai方法也不一定真的能保证完全正确,但由于对“底层原理”的偏执, 我还是更加喜欢非ai的范式,猜字谜”的行为模式本身并不能说服我。
但在2026年的这个时刻,不得不承认的事实就是:ai一定会改变世界!之前使用chatgpt、qwen等一些对话模型时,虽然能感觉到ai很强大,但没有那种惊叹的感觉(我好像非常喜欢用感觉这两个字)。直到我使用cursor生成前后端页面,我本来只是随便写一个简短的提示词试一试,后续再研究研究如何修改,毕竟在大学的时候我还是用过一段时间的vue,没想到它生成代码后就能执行运行,而且结果完全符合我的预期,这个时刻我就知道,我过几年就要被ai取代掉了,至少过几年后,我就完全不需要自己写代码了,是不是所有人到头来都是提示词工程师?最近的几个月, 我已经不怎么自己写代码了, 都是让ai生成后直接用(实际上没怎么review),这也带来很大的不确定性,但目前看起来没出什么问题,所以整个系统就是建立在不确定性之上的? 我从之前的如何写好一段代码变成了如何写好一段提示词,希望我后面能学会如何review一段ai代码,完全放飞也不太好(#^.^#)
与一个伟大的技术挂钩
与改变世界的技术挂钩
黑客
伦理
与人类的区别
冯洛伊曼架构
绝对正确的无聊
ai味
推荐阅读/观看
莱姆狂想曲—泥人十四
时空奇旅
机器人之梦(封面)
ps:使用小写的ai感觉更加亲切,随和,大写的AI就更加刻板,严肃,官方。一个小发现~
RAG、提示词工程、上下文工程、token、mcp、fuction call、skills、ai agent、agi、训练与推理、上下文压缩与遗忘、kv cache等一些花里胡哨的词汇
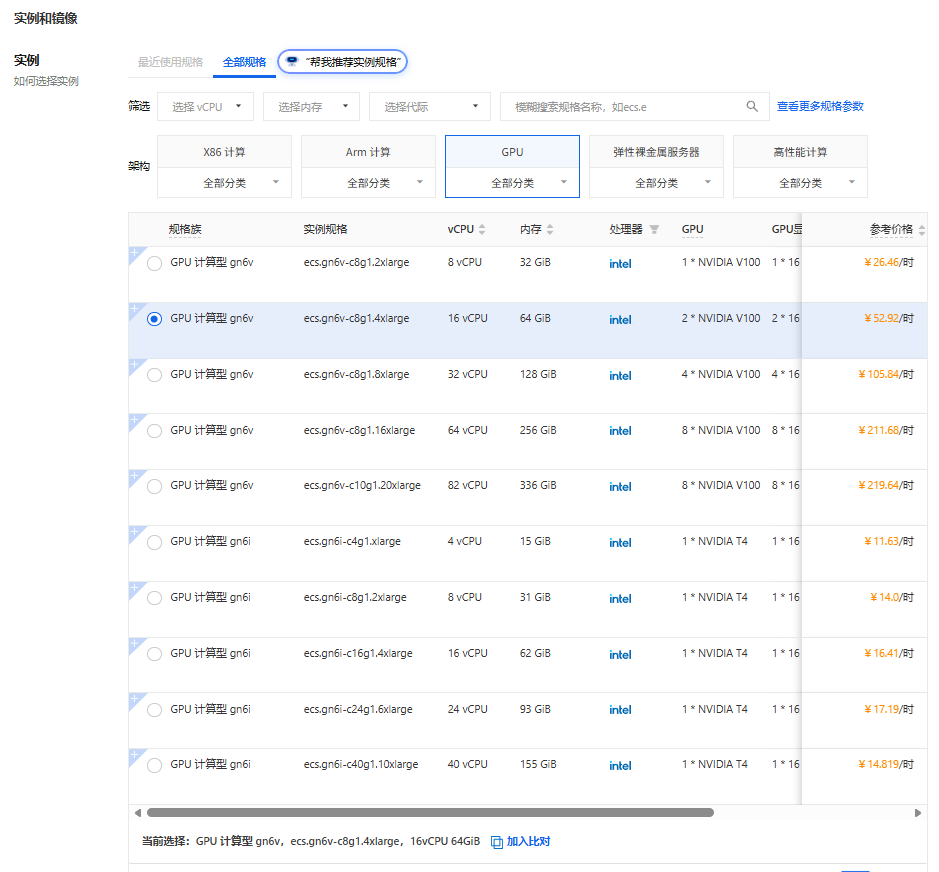
第一步:购买云服务器部署一个模型进行一次对话
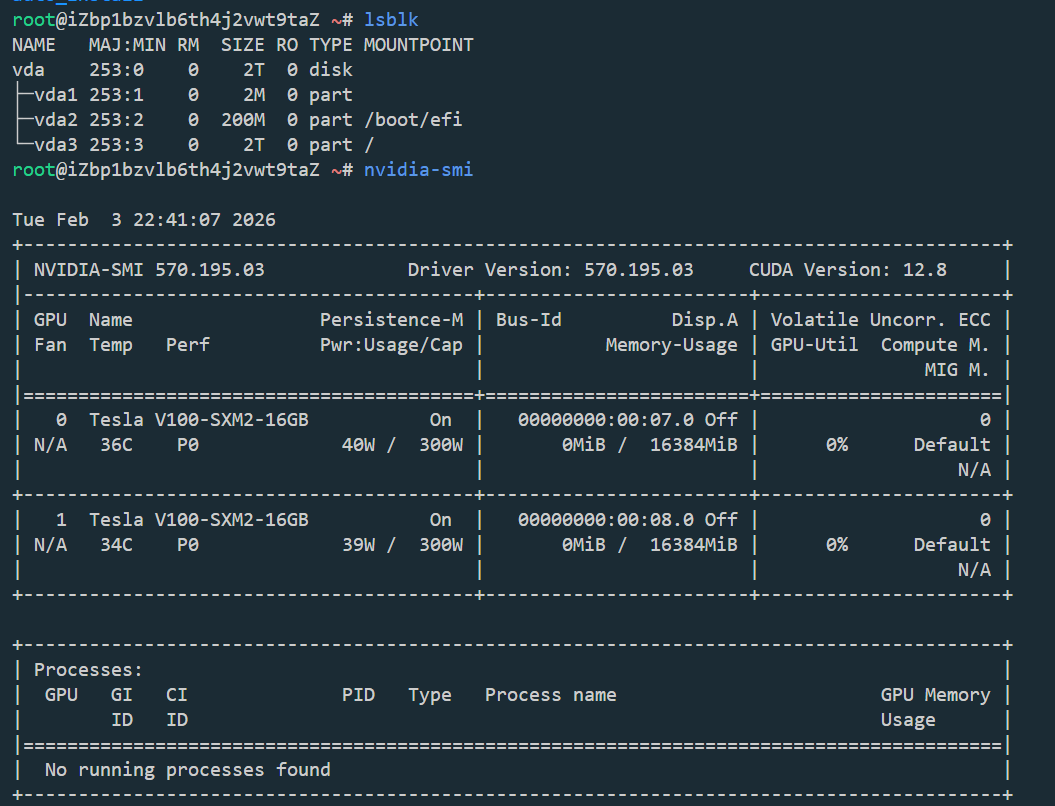
购买 ecs.gn6v-c8g1.4xlarge实例,选择Alibaba Cloud Linux 3.2104 LTS 64位 预装NVIDIA GPU驱动和 CUDA,配置密钥对后通过vscode远程登录
安装依赖包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 source qwen-env/bin/activate
运行demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 "" " Qwen2.5-7B-Instruct 4-bit 量化推理示例(完整注释版) 功能:加载通义千问 7B 指令微调模型,进行一次对话生成 适用环境:Linux + CUDA + 双 Tesla V100(16GB×2) " "" "Qwen/Qwen2.5-7B-Instruct" "auto" ,"role" : "system" , "content" : "You are a helpful assistant." }, "role" : "user" , "content" : "你好!请介绍一下你自己。" } "pt" )print (response_text)
第一次运行需要下载模型
1 2 3 4 5 6 7 8 export HF_ENDPOINT=https://hf-mirror.comexport HF_HUB_ENABLE_HF_TRANSFER=1
模型下载太慢了,改成ModelScope
1 pip install modelscope[vision,nlp]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 """ Qwen2.5-7B-Instruct 4-bit 量化推理示例 (ModelScope 魔搭版) 优势:下载速度快,兼容性好,无需担心远程代码安全警告 """ from modelscope import (import torchfrom transformers import BitsAndBytesConfig "qwen/Qwen2.5-7B-Instruct" True ,"auto" ,"role" : "system" , "content" : "You are a helpful assistant." },"role" : "user" , "content" : "你好!请介绍一下你自己。" }False ,True "pt" ).to(model.device)512 ,True ,0.7 ,0.9 0 ][inputs.input_ids.shape[-1 ]:]True )print (response_text)
第二步:运行一系列demo,了解一些相关概念
使用ai来学ai~
fastapi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchimport gcfrom transformers import BitsAndBytesConfig "Qwen2.5 FastAPI 服务" )"/root/.cache/modelscope/hub/models/qwen/Qwen2.5-7B-Instruct" print ("正在加载分词器..." )True ,True print ("正在加载模型..." )True ,"nf4" ,"auto" ,True ,print ("模型加载完成!" )class ChatRequest (BaseModel ):str str class ChatResponse (BaseModel ):str str def generate_response (session_id: str , user_message: str ) -> str :if session_id not in CONVERSATION_HISTORY:"role" : "user" , "content" : user_message})try :True ,"pt" ,True "<|eot_id|>" )"<|eot_id|>" )if eot_token_id is not None :512 ,True ,0.7 ,0.9 ,0 ][input_ids.shape[-1 ]:]True )"role" : "assistant" , "content" : response_text})return response_textexcept Exception as e:raise HTTPException(status_code=500 , detail=str (e))@app.post("/v1/chat/completions" , response_model=ChatResponse async def chat_completions (request: ChatRequest ):try :return ChatResponse(session_id=request.session_id, response=response_text)except Exception as e:import tracebackprint ("!!! 服务器内部错误详情:" )raise HTTPException(status_code=500 , detail=str (e))@app.get("/health" async def health_check ():return {"status" : "healthy" , "model" : "Qwen2.5-7B-Instruct" }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import requestsimport json"http://localhost:8000" "user_123" def chat ():print ("欢迎使用 Qwen 聊天室!输入 'quit' 退出。" )print ("-" * 50 )while True :input ("\n👤 你: " ).strip()if user_input.lower() in ['quit' , 'exit' , 'bye' , '退出' ]:print ("👋 再见!" )break if not user_input:continue try :f"{BASE_URL} /v1/chat/completions" ,"session_id" : SESSION_ID,"message" : user_inputif response.status_code == 200 :"response" , "(无响应)" )print (f"\n🤖 Qwen: {bot_reply} " )else :print (f" 请求失败: {response.status_code} " )print (response.text)except requests.exceptions.ConnectionError:print (" 连接错误:请确保服务器 (uvicorn) 已经启动。" )break except KeyboardInterrupt:break if __name__ == "__main__" :
RAG
传统的问答模式是让大模型“凭记忆答题”,而 RAG 则是让大模型“开卷考试”。
**先检索 (Retrieval)**:当用户提出一个问题时,系统首先在外部知识库(如你的文档、数据库)中搜索与问题最相关的信息片段。
**再增强 (Augmented)**:将检索到的“参考资料”与用户的原始问题拼接在一起,形成一份包含“最新、特定外部知识”的增强提示(Prompt)。
**后生成 (Generation)**:将这个增强后的提示输入给大语言模型(LLM)。LLM 基于这些具体的参考资料来生成最终答案,而不是依赖其内部过时的参数知识。
通过这种方式,RAG 成功解决了大模型的两个主要痛点:
知识时效性差 :无需重新训练模型,只需更新知识库即可让模型掌握最新信息。事实性错误(幻觉) :让模型的回答有据可依,大幅降低其“一本正经胡说八道”的概率。
⚙️ RAG 的具体实现流程
实现一个 RAG 系统主要分为两个阶段:离线构建知识库 (数据准备)和 在线问答 (推理服务)。
第一阶段:离线构建知识库
这是 RAG 的“备考”阶段,目的是将你的文档资料处理成计算机可以高效检索的格式。
加载文档 :从各种来源(如 TXT, PDF, Word, 数据库)读取原始文本数据。文本分块 :将长文档切分成小的文本片段(Chunk)。这是为了适应大模型的上下文窗口,并保证检索的精度。例如,将一本长篇小说按章节或固定长度切分成几百个段落。向量化存储 :使用嵌入模型(Embedding Model)将每个文本块转换成一串数字(向量),并存入向量数据库。这一步相当于将文字信息“翻译”成计算机可以理解的数学语言,并建立索引。
第二阶段:在线问答
这是 RAG 的“考试”阶段,当用户提问时,系统实时执行以下步骤。
检索 :用户输入问题后,系统使用相同的嵌入模型将问题也转换成向量。然后在向量数据库中进行相似度搜索(如余弦相似度),找出与问题最相关的前 K 个文本块(例如最相关的 3 个段落)。构建 Prompt :将检索到的最相关文本块作为上下文,与用户的原始问题拼接在一起,形成一个新的 Prompt。生成答案 :将这个包含上下文的 Prompt 发送给大语言模型(LLM)。模型阅读上下文后,生成最终的、准确的回答。
1 2 3 pip install langchain langchain_community langchain-core sentence-transformers faiss-cpu
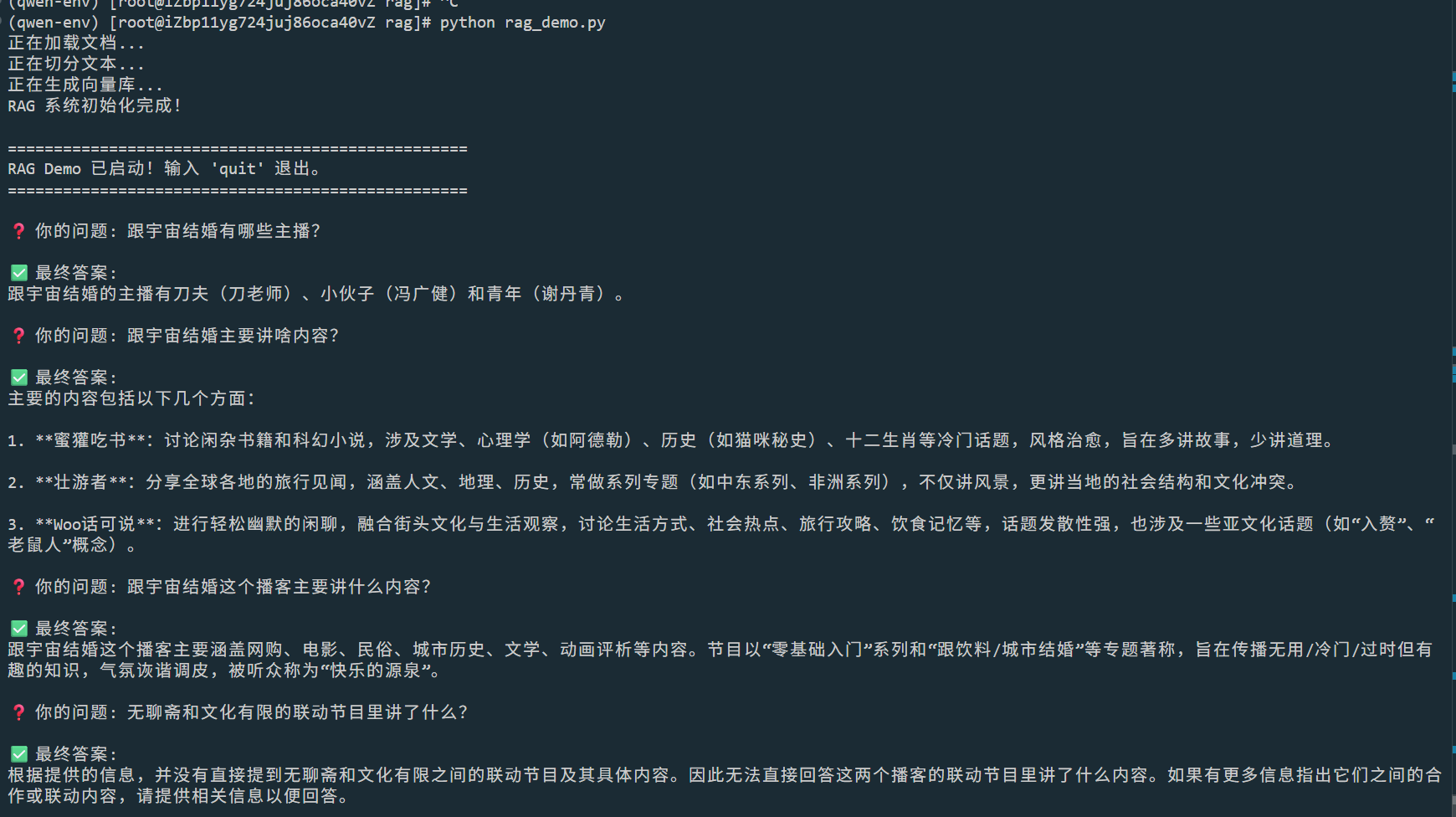
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import osfrom langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import CharacterTextSplitterfrom langchain_huggingface import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParserimport requestsimport json"podcast.txt" "/root/.cache/modelscope/hub/models/AI-ModelScope/bge-small-en-v1___5" "http://localhost:8000/v1/chat/completions" class RAGChain :def __init__ (self ):print ("正在加载文档..." )'utf-8' )print ("正在切分文本..." )500 , chunk_overlap=50 )print ("正在生成向量库..." )"k" : 2 })print ("RAG 系统初始化完成!" )def call_qwen_server (self, prompt ):"""调用本地 Qwen 服务""" try :"session_id" : "rag_user" ,"message" : promptif response.status_code == 200 :return response.json()["response" ]else :return f"API Error: {response.status_code} " except Exception as e:return f"Connection Error: {e} " def invoke (self, question: str ):"\n" .join([doc.page_content for doc in retrieved_docs])f"""你是一个问答助手。请根据以下检索到的信息回答问题。 检索到的信息: {context} 问题:{question} 请用中文回答:""" return resultif __name__ == "__main__" :print ("\n" + "=" *50 )print ("RAG Demo 已启动!输入 'quit' 退出。" )print ("=" *50 )while True :input ("\n❓ 你的问题: " ).strip()if query.lower() in ['quit' , 'exit' ]:break if not query:continue print (f"\n✅ 最终答案:\n{answer} " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
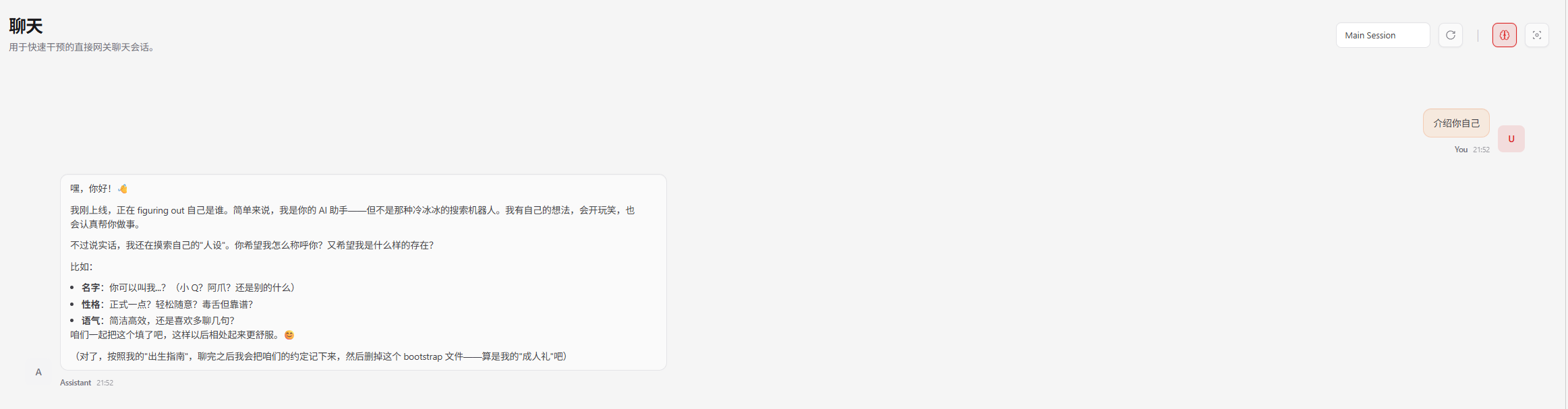
openclaw
使用阿里云轻量应用服务器部署openclaw
OpenClaw - 9.9元定制7*24 AI助理 - 阿里云