// nvme_pci_configure_admin_queue result = nvme_remap_bar(dev, db_bar_size(dev, 0));
// nvme_setup_io_queues do { size = db_bar_size(dev, nr_io_queues); result = nvme_remap_bar(dev, size); if (!result) break; // 映射成功,退出循环 if (!--nr_io_queues) return -ENOMEM; } while (1);
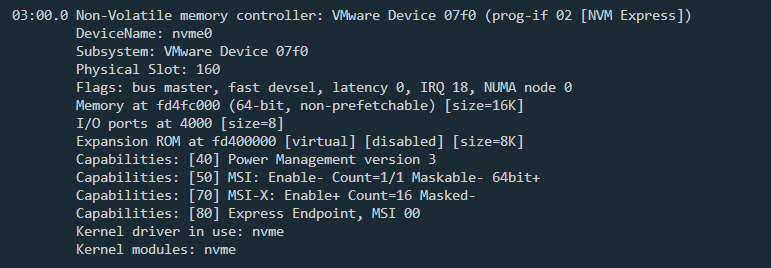
首先介绍Doorbell Stride寄存器——NVM-Express-Base-Specification 总的来说一句话,实际的物理设备CAP.DSTRD值为0,dev->db_stride为1,之后分析中默认db_stride为1 vmware中虚拟nvme硬盘BAR0为16K,驱动第一次映射了8K空间,第二次仅仅映射1个sq/cq寄存器对(admin)的空间,大概率是小于8K的,不需要重新映射,第三次首先计算IO队列数,而后持续尝试映射对应大小的BAR空间,直到找到合适的IO队列数,但通常也是小于8K的,所以不需要进行循环,所以大多数情况只需要进行一次实际的BAR空间映射 NVMe白皮书对NVMe的配置建议 由dev->dbs使用方式可知,每一个DB寄存器对,前4个字节为SQ Tail DB,后四个字节为CQ Head DB
/* * Initialize a NVMe controller structures. This needs to be called during * earliest initialization so that we have the initialized structured around * during probing. */ intnvme_init_ctrl(struct nvme_ctrl *ctrl, struct device *dev, conststruct nvme_ctrl_ops *ops, unsignedlong quirks) { int ret;
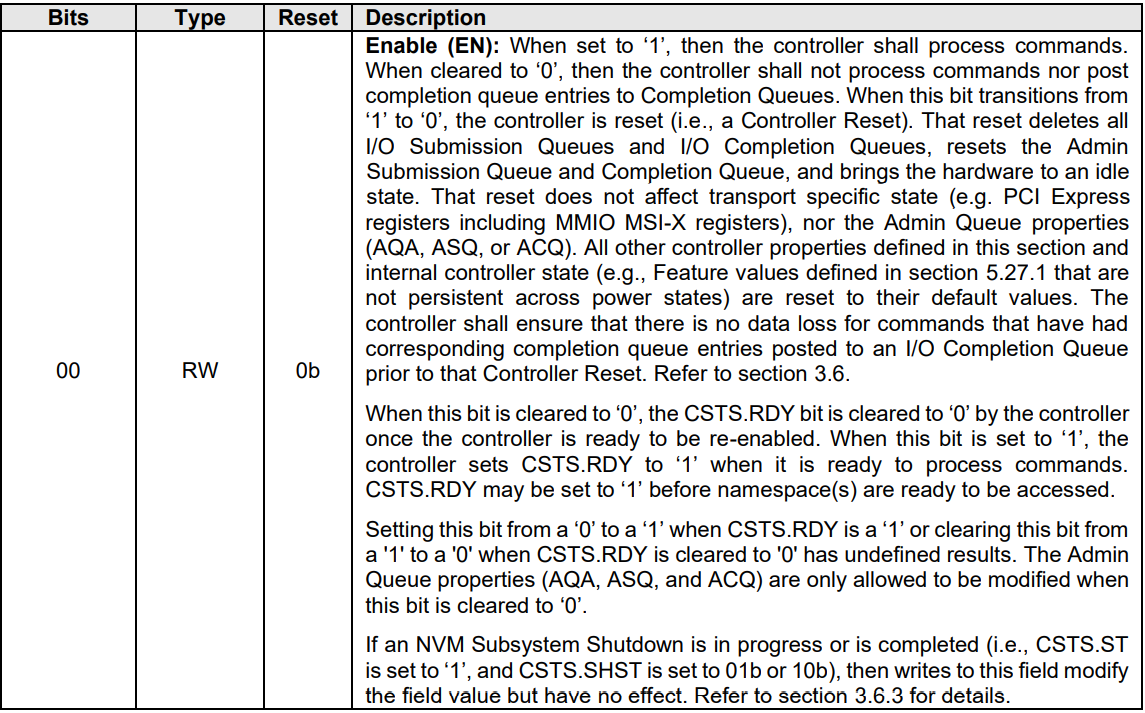
/* * If we're called to reset a live controller first shut it down before * moving on. */ // nvme_enable_ctrl: ctrl->ctrl_config |= NVME_CC_ENABLE; if (dev->ctrl.ctrl_config & NVME_CC_ENABLE) nvme_dev_disable(dev, false); // 驱动初始化时NVME_CC_ENABLE并未置位,不进入该函数
mutex_lock(&dev->shutdown_lock); result = nvme_pci_enable(dev); // 使能PCI设备
result = nvme_pci_configure_admin_queue(dev); // 配置admin queue
if (readl(dev->bar + NVME_REG_CSTS) == -1) { // 测试是否能读取BAR空间 result = -ENODEV; goto disable; }
/* * Some devices and/or platforms don't advertise or work with INTx * interrupts. Pre-enable a single MSIX or MSI vec for setup. We'll * adjust this later. */ result = pci_alloc_irq_vectors(pdev, 1, 1, PCI_IRQ_ALL_TYPES); // 请求中断向量
nvme_map_cmb(dev); // 映射CMB /* pci_enable_pcie_error_reporting enables the device to send error messages to root port when an error is detected. Note that devices don’t enable the error reporting by default, so device drivers need call this function to enable it. */ pci_enable_pcie_error_reporting(pdev); /* The pci_save_state() and pci_restore_state() functions can be used by a device driver to save and restore standard PCI config registers. The pci_save_state() function must be invoked while the device has valid state before pci_restore_state() can be used. If the device is not in the fully-powered state (PCI_POWERSTATE_D0) when pci_restore_state() is invoked, then the device will be transitioned to PCI_POWERSTATE_D0 before any config registers are restored. */ pci_save_state(pdev); return0;
/** * pci_enable_device_mem - Initialize a device for use with Memory space * @dev: PCI device to be initialized * * Initialize device before it's used by a driver. Ask low-level code * to enable Memory resources. Wake up the device if it was suspended. * Beware, this function can fail. */ intpci_enable_device_mem(struct pci_dev *dev) { return pci_enable_device_flags(dev, IORESOURCE_MEM); } /** * pci_enable_device - Initialize device before it's used by a driver. * @dev: PCI device to be initialized * * Initialize device before it's used by a driver. Ask low-level code * to enable I/O and memory. Wake up the device if it was suspended. * Beware, this function can fail. * * Note we don't actually enable the device many times if we call * this function repeatedly (we just increment the count). */ intpci_enable_device(struct pci_dev *dev) { return pci_enable_device_flags(dev, IORESOURCE_MEM | IORESOURCE_IO); }
Before touching any device registers, the driver needs to enable the PCI device by calling pci_enable_device(). This will: 1 wake up the device if it was in suspended state, 2 allocate I/O and memory regions of the device(if BIOS did not), 3 allocate an IRQ(if BIOS did not).
/* * Set both the DMA mask and the coherent DMA mask to the same thing. * Note that we don't check the return value from dma_set_coherent_mask() * as the DMA API guarantees that the coherent DMA mask can be set to * the same or smaller than the streaming DMA mask. */ staticinlineintdma_set_mask_and_coherent(struct device *dev, u64 mask) { int rc = dma_set_mask(dev, mask); if (rc == 0) dma_set_coherent_mask(dev, mask); return rc; }
pci_alloc_irq_vectors
传统中断在系统初始化扫描PCI bus tree时就已自动为设备分配好中断号, 但是如果设备需要使用MSI,驱动需要进行一些额外的配置。linux内核提供pci_alloc_irq_vectors来进行MSI/MSI-X capablity的初始化配置以及中断号分配。
/** * pci_alloc_irq_vectors() - Allocate multiple device interrupt vectors * @dev: the PCI device to operate on * @min_vecs: minimum required number of vectors (must be >= 1) * @max_vecs: maximum desired number of vectors * @flags: One or more of: * * * %PCI_IRQ_MSIX Allow trying MSI-X vector allocations * * %PCI_IRQ_MSI Allow trying MSI vector allocations * * * %PCI_IRQ_LEGACY Allow trying legacy INTx interrupts, if * and only if @min_vecs == 1 * * * %PCI_IRQ_AFFINITY Auto-manage IRQs affinity by spreading * the vectors around available CPUs * * Allocate up to @max_vecs interrupt vectors on device. MSI-X irq * vector allocation has a higher precedence over plain MSI, which has a * higher precedence over legacy INTx emulation. * * Upon a successful allocation, the caller should use pci_irq_vector() * to get the Linux IRQ number to be passed to request_threaded_irq(). * The driver must call pci_free_irq_vectors() on cleanup. * * Return: number of allocated vectors (which might be smaller than * @max_vecs), -ENOSPC if less than @min_vecs interrupt vectors are * available, other errnos otherwise. */ intpci_alloc_irq_vectors(struct pci_dev *dev, unsignedint min_vecs, unsignedint max_vecs, unsignedint flags) { return pci_alloc_irq_vectors_affinity(dev, min_vecs, max_vecs, flags, NULL); }
/* * Controllers may support a CMB size larger than their BAR, * for example, due to being behind a bridge. Reduce the CMB to * the reported size of the BAR */ if (size > bar_size - offset) size = bar_size - offset; dev->cmb = ioremap_wc(pci_resource_start(pdev, bar) + offset, size); // 进行虚拟地址-总线地址映射 if (!dev->cmb) return; dev->cmb_bus_addr = pci_bus_address(pdev, bar) + offset; // 设置CMB总线地址 dev->cmb_size = size; /** * sysfs_add_file_to_group - add an attribute file to a pre-existing group. * @kobj: object we're acting for. * @attr: attribute descriptor. * @group: group name. */ // 将一个属性attr加入kobj目录下已存在的的属性集合group sysfs_add_file_to_group(&dev->ctrl.device->kobj, &dev_attr_cmb.attr, NULL); }
/* /* * ioremap() and friends. * * ioremap() takes a resource address, and size. Due to the ARM memory * types, it is important to use the correct ioremap() function as each * mapping has specific properties. * * Function Memory type Cacheability Cache hint * ioremap() Device n/a n/a * ioremap_cache() Normal Writeback Read allocate * ioremap_wc() Normal Non-cacheable n/a * ioremap_wt() Normal Non-cacheable n/a * * All device mappings have the following properties: * - no access speculation * - no repetition (eg, on return from an exception) * - number, order and size of accesses are maintained * - unaligned accesses are "unpredictable" * - writes may be delayed before they hit the endpoint device * * All normal memory mappings have the following properties: * - reads can be repeated with no side effects * - repeated reads return the last value written * - reads can fetch additional locations without side effects * - writes can be repeated (in certain cases) with no side effects * - writes can be merged before accessing the target * - unaligned accesses can be supported * - ordering is not guaranteed without explicit dependencies or barrier * instructions * - writes may be delayed before they hit the endpoint memory * * The cache hint is only a performance hint: CPUs may alias these hints. * Eg, a CPU not implementing read allocate but implementing write allocate * will provide a write allocate mapping instead. */ /** * ioremap_wc - map memory into CPU space write combined * @phys_addr: bus address of the memory * @size: size of the resource to map * * This version of ioremap ensures that the memory is marked write combining. * Write combining allows faster writes to some hardware devices. * * Must be freed with iounmap. */ void __iomem *ioremap_wc(resource_size_t phys_addr, unsignedlong size) { return __ioremap_caller(phys_addr, size, _PAGE_CACHE_MODE_WC, __builtin_return_address(0), false); }
intnvme_enable_ctrl(struct nvme_ctrl *ctrl, u64 cap) { /* * Default to a 4K page size, with the intention to update this * path in the future to accomodate architectures with differing * kernel and IO page sizes. */ unsigned dev_page_min = NVME_CAP_MPSMIN(cap) + 12, page_shift = 12; int ret;
if (page_shift < dev_page_min) { dev_err(ctrl->device, "Minimum device page size %u too large for host (%u)\n", 1 << dev_page_min, 1 << page_shift); return -ENODEV; }
if (dev->ctrl.oacs & NVME_CTRL_OACS_DBBUF_SUPP) { result = nvme_dbbuf_dma_alloc(dev); if (result) dev_warn(dev->dev, "unable to allocate dma for dbbuf\n"); }