天池比赛记录
本文最后更新于:9 天前
赛题简单介绍
比赛地址:第四届全球数据库大赛赛道1:云原生共享内存数据库性能优化
赛题大致内容:
本地读写速度快,但空间小,远端读写速度慢,但空间大(通过eRDMA读写远端数据)
初赛时实现一个简化、高效的KV存储引擎,支持Write、Read接口,此时key-value皆为定值
复赛额外实现一个Delete接口和重建(rebuild)功能,此时value为变长值。
评测程序分为2个阶段:
1)程序正确性验证
验证KV操作的正确性(包括加密/解密过程),这部分的耗时不计入运行时间的统计。如果正确性测试不通过,则终止,评测失败。
2)性能评测
引擎使用的本地内存和远端内存限制在 8 GB 和 32 GB。 阶段1. 每个线程分别写入约 12 M个Key大小为 16 Bytes,Value大小为 80-1024 Bytes 的 KV对象,并选择性读取验证;阶段2. 每个线程会进行并发删除,每个线程删除 10 M个Key,删除操作耗时将计入运行时间;阶段3. 每个线程分别再次写入约 10 M个Key大小为 16 Bytes,Value大小为 80-256 Bytes 的 KV对象;接着会进行读写混合测试,开启16个线程以75%:25%的读写比例调用64M次。其中75%的读访问具有热点的特征,大部分的读访问集中在少量的Key上面。最后的分数为以上操作耗时的总和。
数据安排如下:本阶段保证任意时刻数据的value部分长度和不超过30G。纯写入的12M次操作中大约70%的操作Value长度在80-128Bytes之间;大约20%的操作Value长度在129-256Bytes之间;大约10%的操作Value长度在257-1024Bytes之间。读写混合的64M操作中,所有Set操作的Value长度均不超过128Bytes。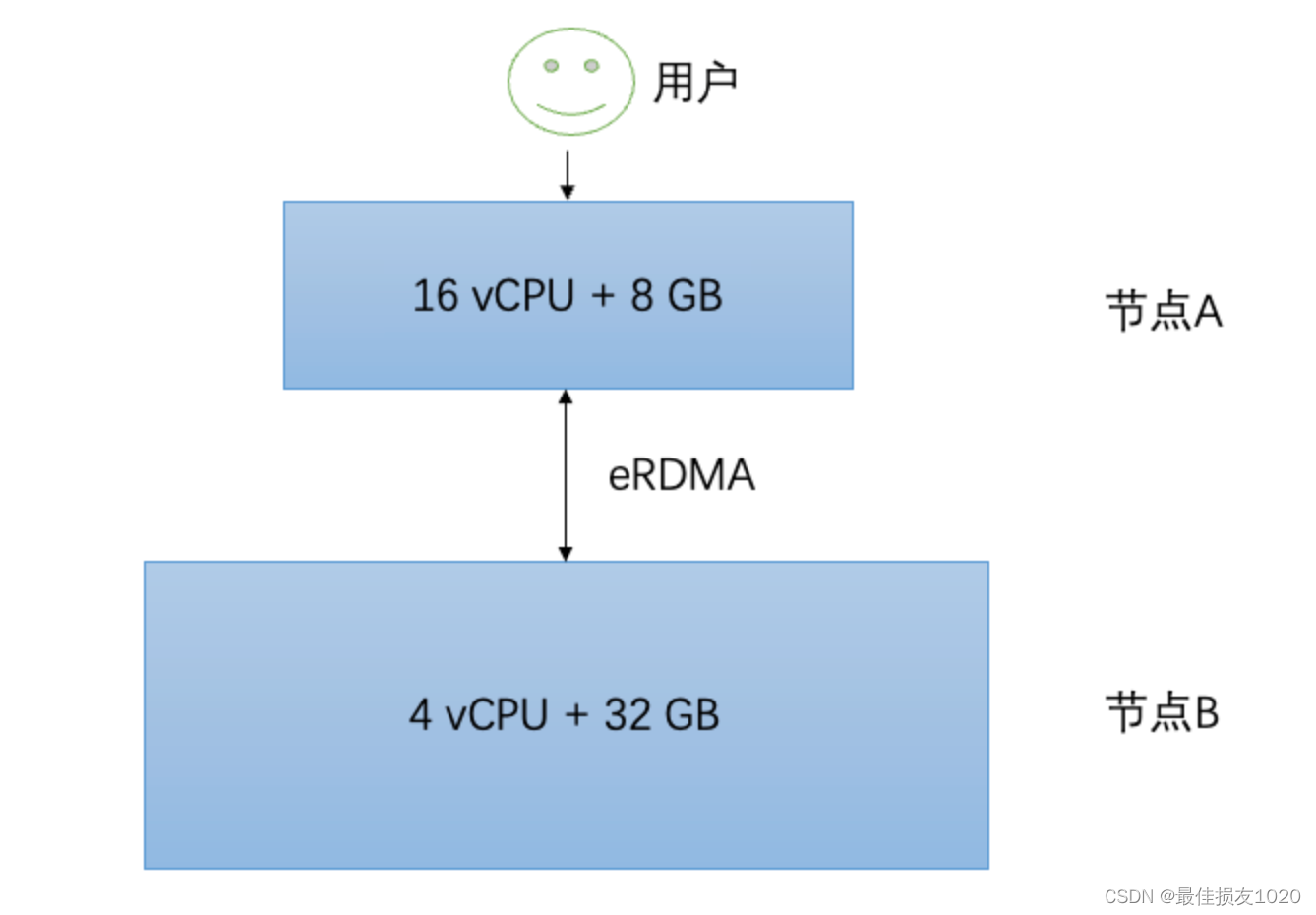
评测程序输出大致如下:
1 | |
复赛排名第20名,正好是极客奖最后一名,嘻嘻。
比赛经历
在初赛时官方提供了一个简单的demo,将key和远端地址存于本地,value全部存于远端,初赛结束时我们的代码大致架构为:
1 | |
初赛结束时,我们只得了9分,最大的原因在于第一次哈希与第二次哈希使用同样的哈希函数(std::hash),导致LocalEngineEntity里的自定义哈希表中很大的一部分空间永远不会被访问(哈希值皆为LocalEngineEntity下标的整数),增大了哈希冲突的概率。
在初赛的基础上编写复赛代码,主要实现三个功能:value的加密,删除操作,重构操作(删除被标记为无效的数据,整理有效数据使其排列更紧凑)。
加密:value的加密根据IPP-Crypto的接口简单实现一个加密算法即可,没有几行代码。
1 | |
删除: 代码的数据通路为:key——(page, index) ——本地缓存m_data_map——远端地址m_addr_map。故实现删除操作首先需要将key—>(page, index)的映射删除,这个只需要增加自定义哈希表的删除功能,注意将删除后的slot插入另一个链表中,以便复用该slot
1 | |
将该映射删除后,无法通过key访问相应的value,但value仍然占据存储空间,故需要标记该位置,表示该value已经被删除,在重构操作时不需要迁移该位置的数据。
1 | |
每一页增加一个位图,标记页中记录是否有效。其中kMaxIndex表示页中最大记录数,kBitmapSize表示运行过程中的最大页号。
与位图相关的另一个操作是更新操作,如果更新操作对应的数据当前在远端,若此时读取远端数据再进行本地更新效率太低;故将这个操作拆分为删除远端数据+插入新数据;这时也需要将远端数据标记为无效。
1 | |
重构:
本地缓存与远端数据交互的基本单位是页,程序运行过程中,无效记录会越来越多,故需定时读取所有页,将有效记录写入到新页中,删除旧页,类似于一种垃圾回收。
在读取远端页时,先读取其头部元数据,再依次读取有效记录,而不是读取整个页数据,这是因为rebuild时远端页有效记录占比较小,这样的读取方式可以减小读取量。
1 | |
一些细节
变长字符编码方式演化
1 | |
kv数据在本地缓存是以string数组(Page类)的形式存储的,当本地缓存达到阈值时,需将很久未访问的页写入到远端,此时是写一个大字符串;故需要将string数组转换为一个大字符串。由于之后有可能再访问该页,需要把各记录的大小也编码进字符串中。刚开始我将每个记录编码成记录大小 +’\0’ +记录内容的形式。
1 | |
而后稍微改变一下编码方式,将记录大小全部放在头部,记录数据放在尾部。
1 | |
这时候编码解码比之前稍微简单一点(去掉了get_size函数),但将长度编码进字符串的方式还是觉得有点低效。后面一想,为什么不直接把大字符串视作一个整数数组,对数组元素赋值就可以了,也就是说 123没必要转换成’1’ ‘2’ ‘3’后存入数组(3个字节),而是直接对一个short类型(2字节)的数赋值。 这样就不再需要编码额外的结束字符作为标记了。
字符数组的头部存储各种元数据,尾部存储实际key-value数据。
1 | |
后面发现leveldb中用了以下这种编码形式
详解varint编码原理
#pragma pack使用错误
本地缓存总共8G空间,有5G是存储key的元数据。其结构体定义如下:
1 | |
可以看到struct data_info_t占4字节,但struct hash_map_slot因为对齐的原因占32字节。自然而然的,为了节省空间,可以强制结构体4字节对齐,这样就能节省4字节的空间,也就节省了1/8的空间。但由于不熟悉#pragma pack,#pragma pack(4)并没有以#pragma pack()结束。然后一运行程序就段错误,gdb调试时bt显示调用栈,f3时传递参数为32位,f2突然截断,参数变成了16位。我觉得这个错误过于诡异,因为就修改了字节对齐,故到比赛结束我都没再用#pragma pack,一般也不建议使用#pragma pack。
示例程序:
1 | |
相关博客:
C/C++中结构体内存对齐(边界对齐),#pragma pack设置
关于#pragma pack(n)引发的一系列问题
右值引用本身是左值
1 | |
对于右值引用我一直有一个误区,认为右值引用是右值,例如以上代码片段,实参类型为Test&&,很容易认为此时调用的函数为第二个,但实际上此时调用的却是第一个。这是因为右值引用本身是左值,更为具体来说,右值引用类型既可以被当作左值也可以被当作右值,判断的标准是,如果它有名字,那就是左值,否则就是右值。
示例程序:
1 | |
实际上使用vscode将鼠标点到函数调用的地方就能看到所调用的函数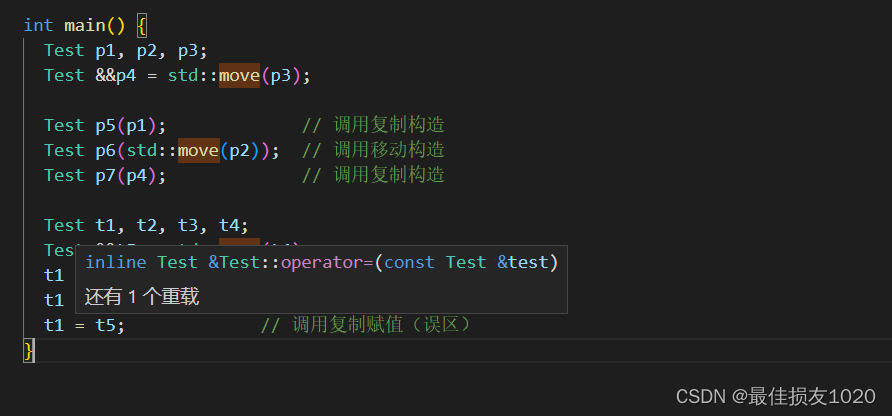
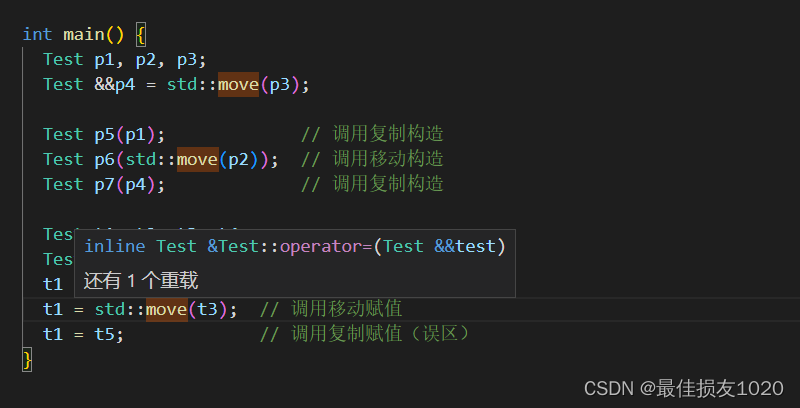
注意move后不应该再使用变量值
我有一次错误就在于调用move函数后仍然使用对象的size方法,导致未定义的行为。
1 | |
参考博客:
详解C++右值引用
其余优化
读者互斥锁
当读请求未命中时,程序需读取远端的字符串数据,并将其解码成string数组(Page类),插入本地缓存后再读取value;该操作耗时较长,且没必要持有锁;但如果多个请求同时请求该远端页,如果让每一个请求都读取远端页,既浪费IO资源,也没啥实际用处;故增加一个读者互斥锁,保证每一页只有一个读者正在请求远端页,其余请求同一远端页的读者会阻塞互斥锁前;待读取远端页的读者读取页数据完成并将该页插入本地缓存中,其余读者发现本地缓存已存在该页,就不会重复读取远端页了。
相关代码:
1 | |
时不时用sizeof看看占用空间,增加一个读者互斥锁相当于每页多了40字节,占比不大。
1 | |
LRU优化
不论是读操作还是写操作,末尾都需要更新LRU列表;为了减小冲突,LRU采用独立的锁,不在m_mutex_锁内更新;当前页(新申请的页)并不加入LRU列表,也不会被淘汰,待当前页写满后再插入到LRU列表中;上次LRU更新的页本次也不再更新(已在队首)。
1 | |
map改成数组 vector改数组
1 | |
程序说明
程序正确性预设
1:运行中页号不得超过kBitmapSize,页中记录数不得超过kMaxIndex,页导出字符串长度不得超过kAllocSize
2:程序经历连续的删除操作后才进入读写操作,使得rebuild最大化。在删除之前远端内存足容纳所有数据
3:即使每次插入时会检查当前页是否已满,但仍然无法阻止程序通过更新value值来增大页大小,所以页数据大小大于kAllocSize便会出现问题
4:kAllocSize小于65536,页成员就可以使用uint16存储,大于则需要使用uint32存储
5:mutex之外的操作耗时极短,可以在rebuild处理前完成
1 | |
相关代码
Engine
1 | |
type
1 | |
local_engine_entity
1 | |